

O que é a função Hive?
Como sabemos hoje, o Hadoop é uma das tecnologias versáteis em big data. O Hadoop tem a capacidade de lidar com grandes conjuntos de dados, mas como o crescimento dos dados é proporcional, os programas de redução de mapa se tornam difíceis. Para executar consultas SQL, presente no HDFS, uma dessas tecnologias foi introduzida pelo Hadoop, chamada apache Hive, iniciada pelo Facebook. O Hive é altamente usado pelo analista de dados. Eles são implantados para três funcionalidades, a saber: resumo de dados, análise de dados em arquivos distribuídos e consulta de dados. O Hive fornece consultas semelhantes ao SQL, chamadas HQL - a linguagem de consulta alta suporta DML, funções definidas pelo usuário. O compilador Hive converte internamente essa consulta em tarefas de redução de mapa, o que simplifica o trabalho do Hadoop na criação de programas complexos. Poderíamos encontrar uma colméia em aplicativos como data warehousing, visualização de dados e análise ad-hoc, google analytics. A principal vantagem é que eles usam o conhecimento de SQL, uma habilidade básica implementada entre cientistas de dados e profissionais de software.
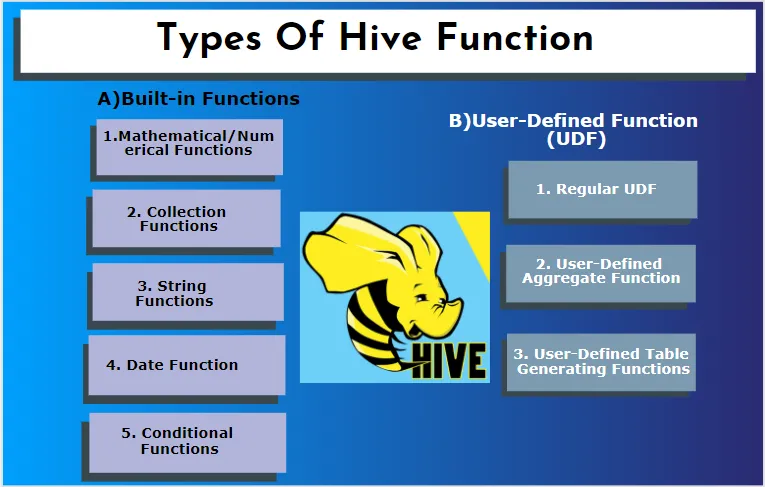
Diferentes funções do Hive em detalhes
O Hive suporta tipos de dados diferentes que não são encontrados em outros sistemas de banco de dados. inclui um mapa, matriz e estrutura. O Hive possui algumas funções internas para executar várias funções matemáticas e aritméticas para um propósito especial. Funções na seção podem ser categorizadas nos seguintes tipos. São funções internas e funções definidas pelo usuário.
A) Funções internas
Essas funções extraem dados das tabelas de seção e processam os cálculos. Algumas das funções internas são:
1. Funções matemáticas / numéricas
Essas funções são usadas principalmente para cálculos matemáticos. Essas funções são usadas em consultas SQL.
| Nome da Função | Exemplo | Descrição |
| ABS (x duplo) | Hive> selecione ABS (-200) em tmp; | Retornará o valor absoluto de um número. |
| CEIL (duplo x) | Hive> selecione CEIL (8.5) de tmp; | Ele buscará o menor número inteiro maior que ou igual ao valor x. |
| Rand (), rand (int seed) | Hive> selecione Rand () de tmp;
Rand (0-9) | Ele retorna um número aleatório, depende do valor inicial, os números aleatórios gerados seriam determinísticos. |
| Pow (dobro x, dobro y) | Hive> selecione Pow (5, 2) de tmp; | Retorna o valor x elevado à potência y. |
| PISO (duplo y) | Hive> selecione FLOOR (11.8) de tmp; | Retorna um número inteiro máximo menor ou igual ao valor y. |
| EXP (duplo a) | Hive> selecione Exp (30) de tmp; | Ele retornará o valor do expoente de 30. os valores do algoritmo natural. |
| PMOD (int a, int b) | Hive> selecione PMOD (2, 4) de tmp; | Dá o módulo positivo do número. |
2. Funções de coleção
Despejar todos os elementos juntos e retornar elementos únicos depende do tipo de dados incluído.
| Nome da função | Exemplo | Descrição |
| Map_values (Mapa) | Hive> selecione Valores do mapa ('oi', 45) | Ele busca elementos de matriz não ordenados. |
| Tamanho (Mapa) | Hive> selecione o tamanho (mapa) | Retorna o número de elementos no mapa do tipo de dados. |
| Matriz_contains (Matriz b) | Hive> selecione array_contains (a (10)) | Retorna VERDADEIRO se a matriz contiver o valor. |
| Matriz de classificação (matriz a) | Hive> selecione sort_array ((10, 3, 6, 1, 7)) | Classifica a matriz de entrada em ordem crescente, de acordo com a ordem natural dos elementos da matriz e retorna o valor. |
3. Funções de String
Usando funções de string, a análise de dados é realizada de forma excelente.
| Dividir (string s, string pat) | Hive> selecione a saída de divisão ('educba ~ hive ~ Hadoop, ' ~ '): ("educba", "hive", "Hadoop") | Ele divide a string em torno das expressões pat e retorna uma matriz. |
| load (string s, int Len, bloco de cordas) | Hive> selecionar carga ('EDUCBA', 6, 'H') | Retorna cadeias com preenchimento à direita com o comprimento da cadeia. (caractere de bloco). |
| Comprimento (string str) | Hive> selecione o comprimento ('educba') | Esta função retorna o comprimento da string. |
| Rtrim (sequência a) | Hive> selecione rtrim ('TOPIC');
Saída: 'Tópico' | Retorna o resultado aparando espaços das extremidades direitas. |
| Concat (sequência m, sequência n) | Hive> selecione concat ('dados', 'ware') Resultado: Dataware | Isso resulta na string fazendo concatenação de duas strings, isso pode levar qualquer número de entradas. |
| Reverso (string s) | Hive> selecione reverso ('Celular') | Retorna o resultado de uma sequência invertida. |
4. Função Data
É necessário ter o formato de dados na seção para evitar erro nulo na saída. É necessário ter compatibilidade de data para ir com as funções de data introduzidas do hive.
| Unix_timestamp (data da string, padrão da string) | Hive> selecione Unix_ timestamp ('2019-06-08', 'aaaa-mm-dd'); Resultado: 124576 400 tempo gasto: 0, 146 segundos | Esta função retorna a data ao formato específico e retorna segundos entre a data e a hora do Unix. |
| Unix_timestamp (data da sequência ) | Hive> selecione Unix_ timestamp ('2019-06-08 09:20:10', 'aaaa-mm-dd'); | Ele retorna a data no formato 'aaaa-MM-dd HH: mm: ss' no carimbo de data / hora do Unix. |
| Hora (data da sequência) | Hive> selecione a hora ('2019-06-08 09:20:10'); Resultado: 09 horas | Retorna a hora do carimbo de data / hora |
5. Funções Condicionais
| Se (teste booleano, valor T verdadeiro, t falso) | Hive> selecione SE (1 = 1, 'VERDADEIRO', 'FALSO') como IF_CONDITION_TEST; | Ele verifica com a condição se o valor é true retorna 1 e false retorna 0. |
| Não é nulo (b) | Hive> Select não é nulo (nulo); | Isso busca instruções não nulas. se nulo retornar falso. |
| Unir (valor1, valor2) | Exemplo: seção> selecionar coalescência (Nulo, nulo, 4, nulo, 6). retorna 4. | Ele busca primeiro valores não nulos da lista de valores. |
B) Função definida pelo usuário (UDF)
O Hive usa funções específicas do usuário de acordo com os requisitos do cliente, ele está escrito na programação java. É implementado por duas interfaces: API simples e API complexa. Eles são chamados a partir da consulta da seção. Três tipos de UDFs:
1. UDF regular
Funciona em uma tabela com uma única linha. Ele é criado através da criação de uma classe java e, em seguida, empacotando-os em um arquivo .jar. A próxima etapa é verificar com um caminho de classe da seção. finalmente, executando-os em uma consulta de seção.
2. Função Agregada Definida pelo Usuário
Eles usam funções agregadas como avg / mean implementando cinco métodos init (), iterate (), parcial (), merge (), terminate ().
3. Funções de geração de tabela definidas pelo usuário
Ele funciona com uma única linha em uma tabela e resulta em várias linhas.
Conclusão
Em conclusão, aprendemos como trabalhar na plataforma hive com funções internas e funções definidas pelo usuário em detalhes neste artigo. A maioria das organizações possui programadores e desenvolvedores de SQL para trabalhar no processo do lado do servidor, mas uma seção apache é uma ferramenta poderosa que os ajuda a usar a estrutura do Hadoop sem nenhum conhecimento prévio sobre programas e reduzir o mapa. O Hive ajuda os novos usuários a iniciar e explorar a análise de dados sem barreiras.
Artigos recomendados
Este é um guia para a função Hive. Aqui discutimos o conceito, dois tipos diferentes de funções e subfunções no Hive. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Principais funções de string no Hive
- Hive Interview Questions
- O que é o RMAN Oracle?
- O que é o modelo Waterfall?
- Introdução à arquitetura Hive
- Hive Order By