

Introdução aos comandos Spark
O Apache Spark é uma estrutura construída sobre o Hadoop para cálculos rápidos. Ele estende o conceito de MapReduce no cenário baseado em cluster para executar uma tarefa com eficiência. Comando Spark é escrito em Scala.
O Hadoop pode ser utilizado pelo Spark das seguintes maneiras (veja abaixo):
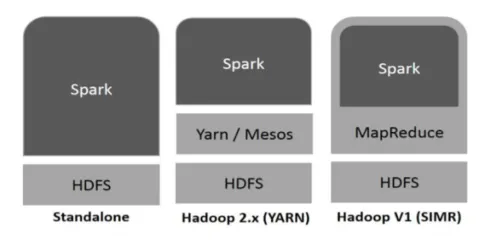
Figura 1
https://www.tutorialspoint.com/
- Independente: Spark implantado diretamente no Hadoop. Os trabalhos do Spark são executados paralelamente no Hadoop e Spark.
- Hadoop YARN: O Spark é executado no Yarn sem a necessidade de pré-instalação.
- Spark no MapReduce (SIMR): o Spark no MapReduce é usado para iniciar o trabalho do spark, além da implantação autônoma. Com o SIMR, é possível iniciar o Spark e usar seu shell sem nenhum acesso administrativo.
Componentes do Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Os conjuntos de dados distribuídos resilientes (RDD) são considerados como a estrutura de dados fundamental dos comandos do Spark. RDD é imutável e somente leitura por natureza. Todo tipo de computação nos comandos spark é feita através de transformações e ações nos RDDs.
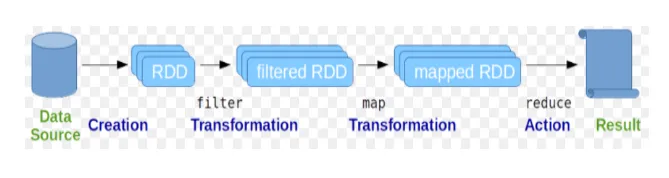
Figura 2
Imagem do Google
O shell Spark fornece um meio para os usuários interagirem com suas funcionalidades. Os comandos do Spark têm muitos comandos diferentes que podem ser usados para processar dados no shell interativo.
Comandos básicos do spark
Vamos dar uma olhada em alguns dos comandos do Basic Spark que são dados abaixo: -
-
Para iniciar o shell Spark:

Fig 3
-
Leia o arquivo do sistema local:

Aqui "sc" é o contexto da centelha. Considerando que "data.txt" está no diretório inicial, ele é lido assim, caso contrário, é necessário especificar o caminho completo.
-
Crie RDD através da paralelização

NewData é o RDD agora.
-
Contar itens no RDD

-
Coletar
Esta função retorna todo o conteúdo do RDD ao programa do driver. Isso é útil na depuração em várias etapas do programa de gravação.
-
Leia os 3 primeiros itens de RDD

-
Salve os dados de saída / processados no arquivo de texto

Aqui, a pasta "output" é o caminho atual.
Comandos de ignição intermediários
1. Filtre no RDD
Vamos criar um novo RDD para itens que contêm "yes".

O filtro de transformação precisa ser chamado no RDD existente para filtrar a palavra "yes", que criará um novo RDD com a nova lista de itens.
2. Operação em Cadeia

Aqui, a transformação de filtro e a ação de contagem agiram em conjunto. Isso é chamado de operação em cadeia.
3. Leia o primeiro item do RDD

4. Contar partições RDD
Como sabemos, o RDD é feito de várias partições, ocorre a necessidade de contar o não. de partições. Isso ajuda no ajuste e na solução de problemas ao trabalhar com os comandos do Spark.

Por padrão, número mínimo. partição pf é 2.
5. participar
Esta função une duas tabelas (o elemento de tabela é pareado) com base na chave comum. No RDD aos pares, o primeiro elemento é a chave e o segundo elemento é o valor.
6. Cache de um arquivo
O armazenamento em cache é uma técnica de otimização. Armazenar em cache o RDD significa que o RDD residirá na memória e todo o cálculo futuro será feito nesses RDD na memória. Ele economiza o tempo de leitura do disco e melhora o desempenho. Em resumo, reduz o tempo para acessar os dados.

No entanto, os dados não serão armazenados em cache se você executar a função acima. Isso pode ser comprovado visitando a página da web:
http: // localhost: 4040 / storage
O RDD será armazenado em cache assim que a ação for concluída. Por exemplo:

Mais uma função que funciona de maneira semelhante ao cache () é persist (). Persist oferece aos usuários a flexibilidade de fornecer o argumento, o que pode ajudar os dados a serem armazenados em cache na memória, disco ou memória fora da pilha. Persistir sem nenhum argumento funciona da mesma forma que cache ().
Comandos Spark avançados
Vamos dar uma olhada em alguns dos comandos avançados do Spark que são dados abaixo: -
-
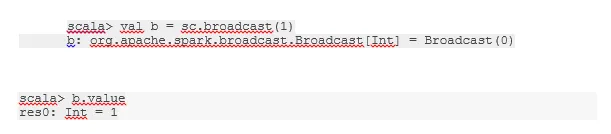
Transmitir uma variável
A variável Broadcast ajuda o programador a manter a leitura da única variável armazenada em cache em todas as máquinas do cluster, em vez de enviar a cópia dessa variável com tarefas. Isso ajuda na redução dos custos de comunicação.
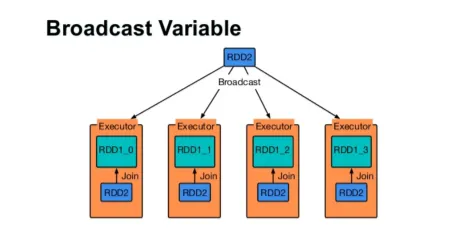
Fig 4
imagem do Google
Em resumo, existem três recursos principais da variável Broadcasted:
- Imutável
- Caber na memória
- Distribuído pelo cluster
-
Acumuladores
Acumuladores são as variáveis que são adicionadas às operações associadas. Existem muitos usos para acumuladores, como contadores, somas etc.

O nome do acumulador no código também pode ser visto na interface do usuário do Spark.
-
Mapa
A função de mapa ajuda na iteração de todas as linhas no RDD. A função usada no mapa é aplicada a todos os elementos no RDD.
Por exemplo, no RDD (1, 2, 3, 4, 6) se aplicarmos “rdd.map (x => x + 2)” obteremos o resultado como (3, 4, 5, 6, 8).
-
Flatmap
O Flatmap funciona de maneira semelhante ao mapa, mas o mapa retorna apenas um elemento, enquanto o flatmap pode retornar a lista de elementos. Portanto, a divisão de frases em palavras precisará de um mapa plano.
-
Coalesce
Esta função ajuda a evitar o embaralhamento de dados. Isso é aplicado na partição existente para que menos dados sejam embaralhados. Dessa forma, podemos restringir o uso de nós no cluster.
Dicas e truques para usar comandos spark
Abaixo estão as dicas e truques diferentes dos comandos do Spark: -
- Iniciantes do Spark podem usar o Spark-shell. Como os comandos do Spark são criados no Scala, é definitivamente ótimo usar o shell do scala. No entanto, o python spark shell também está disponível, portanto, também é possível usar algo que seja versado em python.
- O shell Spark tem muitas opções para gerenciar os recursos do cluster. O comando Abaixo pode ajudá-lo com isso:

- No Spark, trabalhar com conjuntos de dados longos é o usual. Mas as coisas dão errado quando uma entrada ruim é recebida. É sempre uma boa idéia eliminar linhas ruins usando a função de filtro do Spark. O bom conjunto de entradas será uma ótima opção.
- O Spark escolhe boa partição por si só para seus dados. Mas é sempre uma boa prática ficar de olho nas partições antes de iniciar seu trabalho. Experimentar partições diferentes o ajudará com o paralelismo do seu trabalho.
Conclusão - Comandos Spark:
O comando Spark é um mecanismo de big data revolucionário e versátil, que pode funcionar para processamento em lote, processamento em tempo real, armazenamento em cache de dados etc. O Spark possui um rico conjunto de bibliotecas de Machine Learning que podem permitir que cientistas de dados e organizações analíticas criem organizações fortes, interativas e aplicações rápidas.
Artigos recomendados
Este foi um guia para os comandos do Spark. Aqui discutimos comandos básicos e avançados do Spark e alguns comandos imediatos do Spark. Você também pode consultar o seguinte artigo para saber mais -
- Comandos do Adobe Photoshop
- Comandos importantes do VBA
- Comandos do Tableau
- Cábula SQL (comandos, dicas grátis e truques)
- Tipos de junções no Spark SQL (exemplos)
- Componentes Spark Visão geral e os 6 principais componentes