
Introdução à arquitetura Hive
A Hive Architecture é construída sobre o ecossistema Hadoop. O Hive freqüentemente tem interações com o Hadoop. O Apache Hive lida com o sistema de banco de dados SQL do domínio e com a Redução de mapa. Os aplicativos Hive podem ser escritos em várias linguagens como Java, python. A arquitetura do Hive mostra como escrever a linguagem de consulta do hive e como as interações entre o programador são feitas usando a interface da linha de comandos. A linguagem de consulta do Hive faz o trabalho de converter todas as tarefas de cluster do Hadoop por meio da redução de mapa. Como todos sabíamos, o Hadoop processava big data em um ambiente distribuído e formava uma estrutura de código aberto. Com o hive, é flexível gerenciar e executar a consulta e um bom suporte para executar funções como encapsulamento e consultas ad-hoc. Este artigo fornece uma breve introdução à arquitetura de seção, que reside na camada Hadoop para executar resumos em big data.
Arquitetura do Hive com seus componentes
O Hive desempenha um papel importante na análise de dados e na integração de inteligência de negócios e suporta formatos de arquivo como arquivo de texto e arquivo rc. O Hive usa um sistema distribuído para processar e executar consultas e, finalmente, o armazenamento é feito no disco e finalmente processado usando uma estrutura de redução de mapa. Ele resolve o problema de otimização encontrado em mapa-reduzir e seção executar tarefas em lote que são claramente explicadas no fluxo de trabalho. Aqui, uma meta-loja armazena informações do esquema. Uma estrutura chamada Apache Tez foi projetada para desempenho de consultas em tempo real.
Os principais componentes do Hive são apresentados abaixo:
- Clientes do Hive
- Hive Services
- Armazenamento de seção (Meta storage)
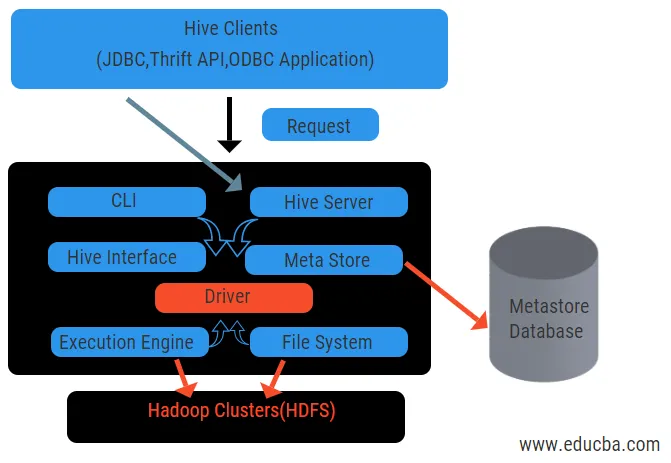
O diagrama acima mostra a arquitetura do Hive e seus elementos componentes.
Clientes da Hive:
Eles incluem o aplicativo Thrift para executar comandos de seção fáceis, disponíveis para python, ruby, C ++ e drivers. Esses aplicativos cliente se beneficiam da execução de consultas na seção. O Hive possui três tipos de categorização de clientes: clientes econômicos, clientes JDBC e ODBC.
Serviços de colméia:
Para processar todas as seções da consulta, existem vários serviços. Todas as funções são facilmente definidas pelo usuário na seção. Vamos ver todos esses serviços em breve:
- Interface da linha de comandos ( interface do usuário): permite a interação entre o usuário e a seção, um shell padrão. Ele fornece uma GUI para executar a linha de comando e o insight da seção. Também podemos usar interfaces da Web (HWI) para enviar as consultas e interações com um navegador da web.
- Driver Hive: Ele recebe consultas de diferentes fontes e clientes, como o servidor thrift, e armazena e busca no driver ODBC e JDBC, que são automaticamente conectados à seção. Este componente faz análise semântica ao ver as tabelas do metastore que analisa uma consulta. O driver leva a ajuda do compilador e executa funções como analisador, planejador, execução de tarefas do MapReduce e otimizador.
- Compilador: O processo de análise e semântica da consulta é feito pelo compilador. Ele converte a consulta em uma árvore de sintaxe abstrata e novamente no DAG para compatibilidade. O otimizador, por sua vez, divide as tarefas disponíveis. O trabalho do executor é executar as tarefas e monitorar o cronograma de pipeline das tarefas.
- Mecanismo de execução: todas as consultas são processadas por um mecanismo de execução. Os planos de estágio de um DAG são executados pelo mecanismo e ajudam a gerenciar as dependências entre os estágios disponíveis e executá-los em um componente correto.
- Metastore: Ele atua como um repositório central para armazenar todas as informações estruturadas dos metadados. Também é um aspecto importante para a seção, pois possui informações como tabelas e detalhes de particionamento e armazenamento de arquivos HDFS. Em outras palavras, diremos que o metastore atua como um espaço para nome de tabelas. O Metastore é considerado um banco de dados separado que também é compartilhado por outros componentes. O Metastore possui duas partes chamadas serviço e armazenamento de backlog.
O modelo de dados da seção é estruturado em Partições, buckets, tabelas. Tudo isso pode ser filtrado, ter chaves de partição e avaliar a consulta. A consulta do Hive funciona na estrutura do Hadoop, não no banco de dados tradicional. O servidor Hive é uma interface entre as consultas de um cliente remoto e a seção. O mecanismo de execução é completamente incorporado em um servidor de seção. Você pode encontrar aplicação de colméia em aprendizado de máquina, inteligência de negócios no processo de detecção.
Fluxo de trabalho da colméia:
O Hive funciona em dois tipos de modos: modo interativo e modo não interativo. O modo anterior permite que todos os comandos do hive acessem diretamente o shell do hive, enquanto o tipo posterior executa o código no modo do console. Os dados são divididos em partições que se dividem ainda mais em buckets. Os planos de execução são baseados em agregação e inclinação de dados. Uma vantagem adicional do uso do hive é que ele processa facilmente grande escala de informações e possui mais interfaces com o usuário.
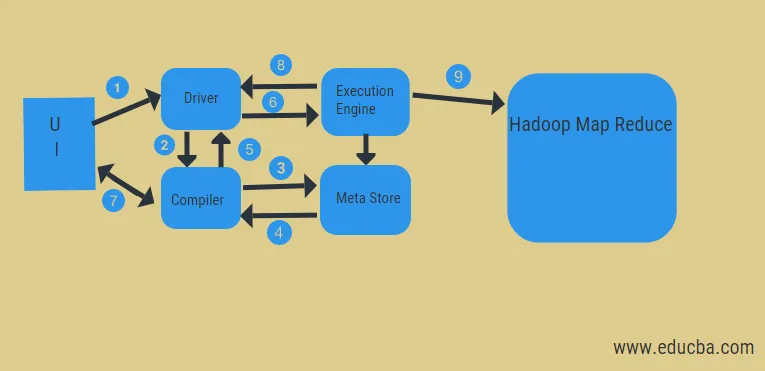
No diagrama acima, podemos ter uma idéia do fluxo de dados na seção com o sistema Hadoop.
Os passos incluem:
- executar a consulta da interface do usuário
- obter um plano a partir das etapas do DAG das tarefas do driver
- obter solicitação de metadados da meta store
- envie metadados do compilador
- enviando o plano de volta ao motorista
- Executar plano no mecanismo de execução
- buscando resultados para a consulta de usuário apropriada
- enviando resultados bidirecionalmente
- processamento do mecanismo de execução no HDFS com os resultados de redução de mapa e busca dos nós de dados criados pelo rastreador de tarefas. Ele atua como um conector entre o Hive e o Hadoop.
O trabalho do mecanismo de execução é se comunicar com os nós para obter as informações armazenadas na tabela. Aqui, operações SQL como criar, soltar, alterar são executadas para acessar a tabela.
Conclusão:
Examinamos o Hive Architecture e seu fluxo de trabalho, o hive basicamente executa uma quantidade de petabytes de dados e, portanto, é um pacote de data warehouse na plataforma Hadoop. Como o hive é uma boa opção para lidar com alto volume de dados, ajuda na preparação de dados com o guia da interface SQL para resolver os problemas do MapReduce. O Apache hive é uma ferramenta ETL para processar dados estruturados. Conhecer o funcionamento da arquitetura do hive ajuda as pessoas corporativas a entender o princípio de funcionamento do hive e começa bem com a programação do hive.
Artigos recomendados:
Este foi um guia para a Hive Architecture. Aqui discutimos a arquitetura da seção, diferentes componentes e fluxo de trabalho da seção. você também pode consultar os seguintes artigos para saber mais
- Arquitetura Hadoop
- Usos do Ruby
- O que é C ++
- O que é o banco de dados MySQL
- Hive Order By