

Introdução ao map Join no Hive
A junção de mapa é um recurso usado nas consultas do Hive para aumentar sua eficiência em termos de velocidade. Associação é uma condição usada para combinar os dados de 2 tabelas. Portanto, quando realizamos uma junção normal, o trabalho é enviado para uma tarefa Map-Reduce que divide a tarefa principal em 2 etapas - “Map stage” e “Reduce stage”. O estágio Map interpreta os dados de entrada e retorna a saída para o estágio de redução na forma de pares de valores-chave. O próximo passo passa pelo estágio de reprodução aleatória, onde são classificados e combinados. O redutor pega esse valor classificado e conclui o trabalho de junção.
Uma tabela pode ser carregada na memória completamente dentro de um mapeador e sem a necessidade de usar o processo Map / Reducer. Ele lê os dados da tabela menor e os armazena em uma tabela de hash na memória e os serializa em um arquivo de memória de hash, reduzindo o tempo substancialmente. Também é conhecido como junção lateral do mapa no Hive. Basicamente, envolve a realização de junções entre 2 tabelas usando apenas a fase Mapa e pulando a fase Reduzir. Uma diminuição do tempo no cálculo de suas consultas pode ser observada se elas usarem regularmente uma pequena tabela de junções.
Sintaxe para ingressar no mapa no Hive
Se quisermos executar uma consulta de junção usando map-join, precisamos especificar uma palavra-chave “/ * + MAPJOIN (b) * /” na declaração como a seguir:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Neste exemplo, precisamos criar 2 tabelas com os nomes tablename1 e tablename2 com 2 colunas: emp_id e emp_name. Um deve ser um arquivo maior e o outro deve ser menor.
Antes de executar a consulta, precisamos definir a propriedade abaixo como true:
hive.auto.convert.join=true
A consulta de junção para junção de mapa é escrita como acima e o resultado obtido é:
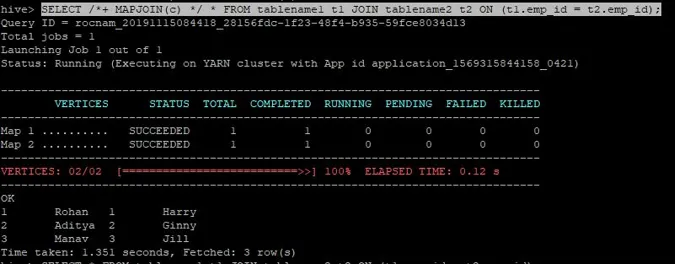
A consulta foi concluída em 1, 351 segundos.
Exemplos de junção de mapa no Hive
Aqui estão os seguintes exemplos mencionados abaixo
1. Exemplo de junção de mapa
Neste exemplo, vamos criar 2 tabelas denominadas tabela1 e tabela2 com 100 e 200 registros, respectivamente. Você pode consultar o comando abaixo e as capturas de tela para executar o mesmo:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Agora carregamos os registros nas duas tabelas usando os comandos abaixo:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Vamos executar uma consulta de junção de mapa normal em seus IDs, como mostrado abaixo, e verificar o tempo necessário para o mesmo:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
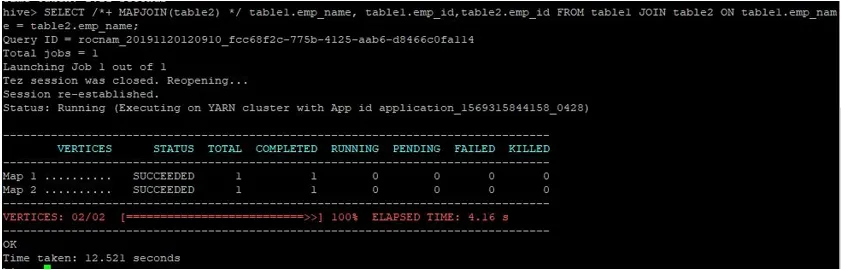
Como podemos ver, uma consulta de junção de mapa normal levou 12, 521 segundos.
2. Exemplo de junção de mapa de bucket
Vamos agora usar a junção Bucket-map para executar o mesmo. Existem algumas restrições que precisam ser seguidas para o depósito:
- Os buckets podem ser unidos entre si apenas se o total de buckets de qualquer tabela for múltiplo do número de buckets na outra tabela.
- Deve ter tabelas em balde para executar o balde. Portanto, vamos criar o mesmo.
A seguir, estão os comandos usados para criar tabelas em balde table1 e table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Também inseriremos os mesmos registros da tabela1 nessas tabelas em bucket:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
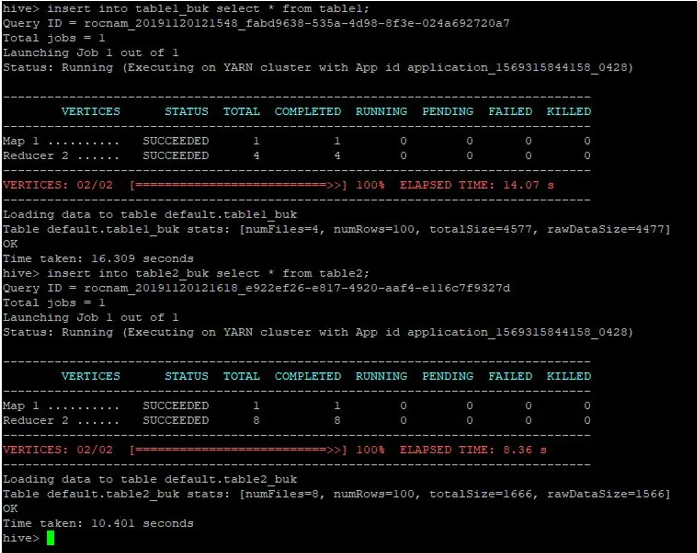
Agora que temos nossas 2 tabelas em balde, vamos realizar uma junção de mapa de balde nessas. A primeira tabela possui 4 intervalos, enquanto a segunda tabela possui 8 intervalos criados na mesma coluna.
Para que a consulta de junção bucket-map funcione, devemos definir a propriedade abaixo como true na seção:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
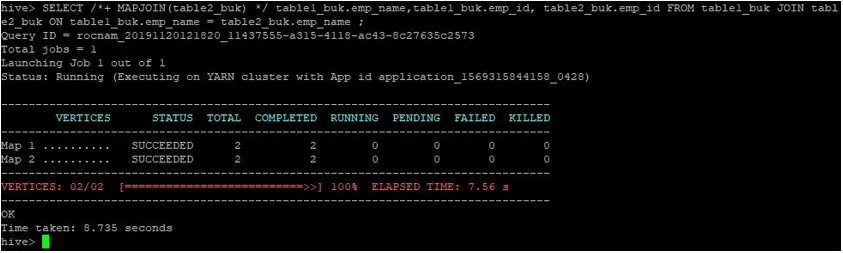
Como podemos ver, a consulta foi concluída em 8.735 segundos, o que é mais rápido que uma junção normal no mapa.
3. Classificar exemplo de junção de mapa de cubo de distribuição (SMB)
O SMB pode ser executado em tabelas em balde com o mesmo número de baldes e se as tabelas precisarem ser classificadas e agrupadas em colunas de junção. O nível do mapeador une esses buckets correspondentemente.
Assim como na junção de mapa de bucket, existem 4 buckets para a tabela 1 e 8 buckets para a table2. Para este exemplo, criaremos outra tabela com 4 baldes.
Para executar a consulta SMB, precisamos definir as seguintes propriedades da seção, conforme mostrado abaixo:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Para executar a junção SMB, é necessário que os dados sejam classificados de acordo com as colunas de junção. Portanto, sobrescrevemos os dados na tabela 1 agrupados como abaixo:
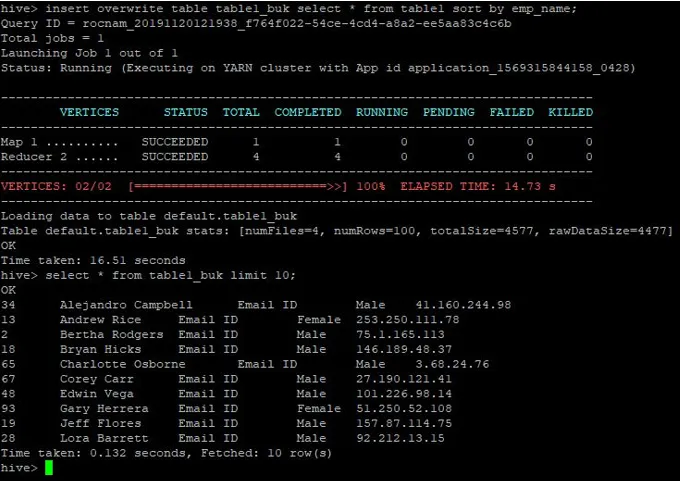
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Os dados são classificados agora, que podem ser vistos na captura de tela abaixo:
Também substituiremos os dados na tabela em balde2 como abaixo:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Vamos realizar a junção para 2 tabelas acima, da seguinte maneira:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
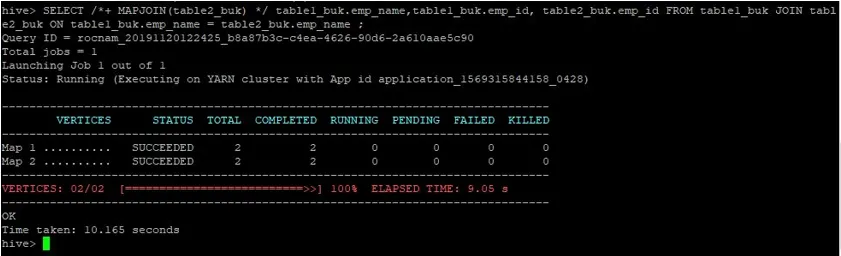
Podemos ver que a consulta levou 10.165 segundos, o que é melhor do que uma junção normal no mapa.
Vamos agora criar outra tabela para a tabela2 com 4 intervalos e os mesmos dados classificados com emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
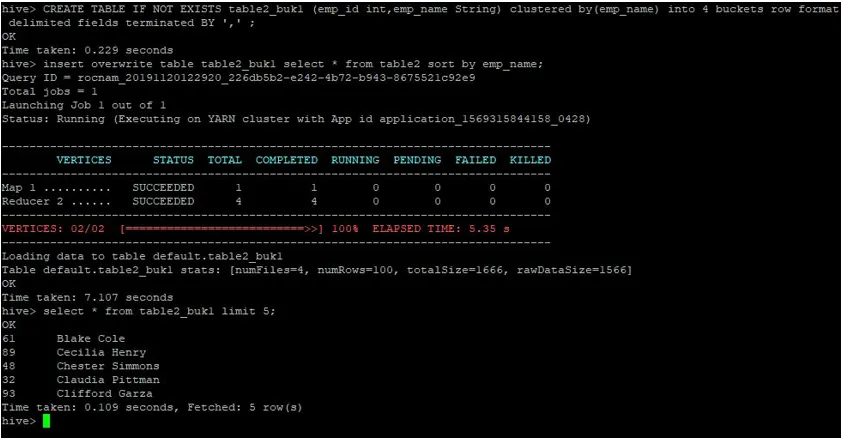
Considerando que agora temos ambas as tabelas com 4 buckets, vamos executar novamente uma consulta de junção.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
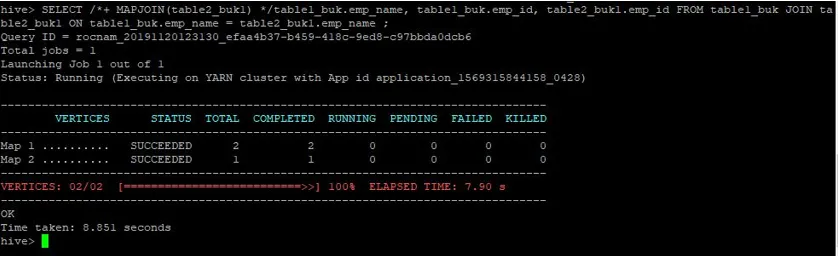
A consulta levou 8, 851 segundos novamente mais rápido que a consulta de junção no mapa normal.
Vantagens
- A junção de mapa reduz o tempo necessário para processos de classificação e mesclagem que ocorrem no shuffle e reduz as etapas, minimizando também o custo.
- Aumenta a eficiência de desempenho da tarefa.
Limitações
- A mesma tabela / alias não pode ser usada para ingressar em colunas diferentes na mesma consulta.
- A consulta de junção de mapa não pode converter junções externas completas em junções laterais do mapa.
- A junção de mapa pode ser executada apenas quando uma das tabelas é pequena o suficiente para caber na memória. Portanto, ele não pode ser executado onde os dados da tabela são enormes.
- É possível fazer uma junção esquerda em uma junção no mapa apenas quando o tamanho da tabela certa for pequeno.
- É possível fazer uma junção direita em uma junção no mapa apenas quando o tamanho da tabela esquerda for pequeno.
Conclusão
Tentamos incluir os melhores pontos possíveis de junção de mapa no Hive. Como vimos acima, a junção no lado do mapa funciona melhor quando uma tabela possui menos dados, para que o trabalho seja concluído rapidamente. O tempo gasto para as consultas mostradas aqui depende do tamanho do conjunto de dados, portanto, o tempo mostrado aqui é apenas para análise. A junção de mapa pode ser facilmente implementada em aplicativos em tempo real, pois temos dados enormes, ajudando assim a reduzir o tráfego de E / S da rede.
Artigos recomendados
Este é um guia para o Map Join no Hive. Aqui discutimos os exemplos de junção de mapas no Hive, além das vantagens e limitações. Você também pode consultar o seguinte artigo para saber mais -
- Junta-se ao Hive
- Funções internas do Hive
- O que é uma colméia?
- Comandos do Hive