

O que é o AWS Kinesis?
O Kinesis é uma plataforma que ajuda na coleta, processamento e análise de dados de streaming no Amazon Web Services. Os dados de streaming são uma grande quantidade de dados gerados por diferentes fontes, como mídia social, sensores de IoT, previsão do tempo, assistência médica etc. Eles são usados na criação de aplicativos com base nos requisitos do usuário. Alguns dos aplicativos comuns incluem análise preditiva em Big Data, Machine Learning, etc. Neste tópico, aprenderemos sobre o AWS Kinesis.
Serviços da AWS Kinesis
Antes de passar para os serviços, vamos primeiro entender algumas terminologias usadas no Kinesis.
Terminologia
| Prazo | Definição |
| Registro de dados | Unidade de dados armazenada no fluxo de dados do Kinesis. Consiste em blob de dados, número de sequência e uma chave de partição |
| Estilhaço | Conjunto da sequência de registros de dados. O número de shards pode ser aumentado ou diminuído se a taxa de dados for aumentada. |
| Período de retenção | O período em que os dados podem ser acessados após serem adicionados ao fluxo.
Período de retenção padrão: 24 horas |
| Produtor | Ele reúne registros de dados no Kinesis Stream |
| Consumidor | Ele obtém registros do Kinesis Stream e os processa. |
A Kinesis fornece três serviços principais. Eles são:
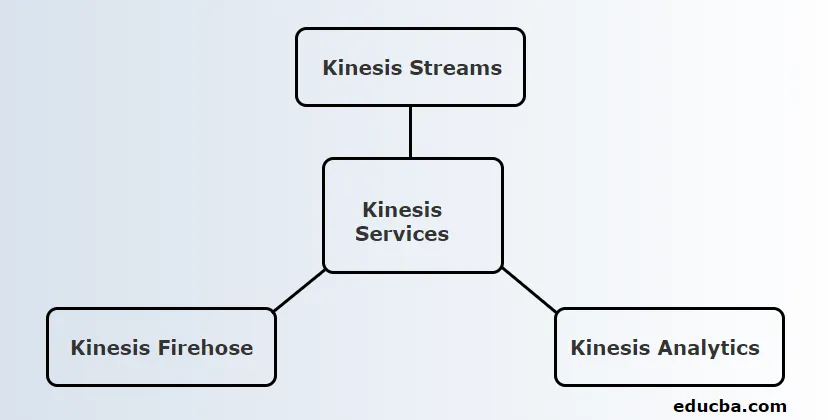
1. Kinesis Streams
O Kinesis Stream consiste em um conjunto de seqüências de registros de dados conhecidos como Shards. Esses fragmentos têm uma capacidade fixa que pode fornecer uma taxa máxima de leitura de 2 MB / segundo e taxa de gravação de 1 MB / segundo. A capacidade máxima de um fluxo é a soma da capacidade de cada fragmento.
Trabalho de Kinesis:
- Os dados produzidos pela IoT e outras fontes conhecidas como Produtores são alimentados no Kinesis Streams para armazenamento em Shards.
- Esses dados estarão disponíveis no Shard por um período máximo de 24 horas.
- Se precisar ser armazenado por mais tempo que o padrão, o usuário poderá aumentar para um período de retenção de 7 dias.
- Quando os dados atingem os Shards, as instâncias do EC2 podem coletar esses dados para propósitos diferentes.
- As instâncias do EC2 que recuperam dados são conhecidas como Consumidores.
- Após o processamento dos dados, eles são alimentados em um dos Amazon Web Services, como Simple Storage Service (S3), DynamoDB, Redshift etc.
2. Kinesis Firehose
O Kinesis Firehose é útil para mover dados para os serviços da Amazon na Web, como Redshift, serviço de armazenamento simples, Elastic Search etc. É uma parte da plataforma de streaming que não gerencia nenhum recurso. Os produtores de dados são configurados de modo que os dados tenham que ser enviados para o Kinesis Firehose e os enviam automaticamente para o destino correspondente.
Trabalho de Kinesis Firehose:
- Conforme mencionado no trabalho do AWS Kinesis Streams, o Kinesis Firehose também obtém dados de produtores como telefones celulares, laptops, EC2 etc. Mas isso não precisa levar dados para shards ou aumentar os períodos de retenção como o Kinesis Streams. É porque o Kinesis Firehose faz isso automaticamente.
- Os dados são analisados automaticamente e alimentados no Simple Storage Service
- Como não há período de retenção, os dados devem ser analisados ou enviados para qualquer armazenamento, dependendo dos requisitos do usuário.
- Se os dados tiverem que ser enviados para o Redshift, eles devem ser movidos primeiro para o Simple Storage Service e precisam ser copiados para o Redshift a partir daí.
- Porém, no caso da Elastic Search, os dados podem ser diretamente alimentados de forma semelhante ao Simple Storage Service.
3. Kinesis Analytics
O Kinesis Firehose permite executar consultas SQL nos dados presentes no Kinesis Firehose. Usando essas consultas SQL, os dados podem ser armazenados no Redshift, Simple Storage Service, ElasticSearch, etc.
Arquitetura do AWS Kinesis
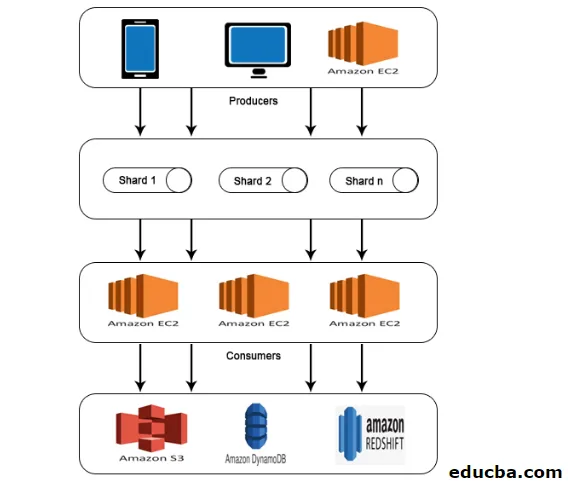
A AWS Kinesis Architecture consiste em
- Produtores
- Estilhaços
- Consumidores
- Armazenamento
Semelhante ao trabalho explicado no AWS Kinesis Data Stream, os dados dos Producers são alimentados no Shards, onde os dados são processados e analisados. Os dados analisados são então movidos para instâncias do EC2 para executar determinados aplicativos. Por fim, os dados serão armazenados em qualquer um dos serviços web da Amazon, como S3, Redshift etc.
Como usar o AWS kinesis?
Para trabalhar com o AWS Kinesis, é necessário executar as duas etapas a seguir.
1. Instale a interface de linha de comando (AWS) da AWS.
A instalação da interface da linha de comandos é diferente para diferentes sistemas operacionais. Portanto, instale a CLI com base no seu sistema operacional.
Para usuários do Linux, use o comando sudo pip install AWS CLI
Verifique se você possui uma versão python 2.6.5 ou superior. Após o download, configure-o usando o comando AWS configure. Em seguida, os seguintes detalhes serão solicitados conforme mostrado abaixo.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Para usuários do Windows, baixe o MSI Installer apropriado e execute-o.
2. Execute operações do Kinesis usando CLI
Observe que os fluxos de dados do Kinesis não estão disponíveis para o nível gratuito da AWS. Portanto, os fluxos Kinesis criados serão cobrados.
Agora vamos ver algumas operações de kinesis na CLI.
- Criar fluxo
Crie um KStream de fluxo com o Shard count 2 usando o seguinte comando.
aws kinesis create-stream --stream-name KStream --shard-count 2
Verifique se o fluxo foi criado.
aws kinesis describe-stream --stream-name KStream
Se ele for criado, uma saída semelhante ao exemplo a seguir será exibida.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Colocar registro
Agora, um registro de dados pode ser inserido usando o comando put-record. Aqui, um registro contendo um teste de dados é inserido no fluxo.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Se a inserção for bem sucedida, a saída será exibida como mostrado abaixo.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Obter registro
Primeiro, o usuário precisa obter o iterador de shard que representa a posição do fluxo para o shard.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Em seguida, execute o comando usando o iterador de shard obtido.
aws kinesis get-records --shard-iterator ###########
Uma saída de amostra será obtida como mostrado abaixo.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Limpar
Para evitar cobranças, o fluxo criado pode ser excluído usando o comando abaixo.
aws kinesis delete-stream --stream-name KStream
Conclusão
O AWS Kinesis é uma plataforma que coleta, processa e analisa dados de streaming para vários aplicativos, como aprendizado de máquina, análise preditiva e assim por diante. Os dados de streaming podem ter qualquer formato, como áudio, vídeo, dados do sensor etc.
Artigos recomendados
Este é um guia para o AWS Kinesis. Aqui discutimos como usar o AWS Kinesis e também seu serviço com o trabalho e a arquitetura. Você também pode consultar o seguinte artigo para saber mais -
- Arquitetura da AWS
- O que é o AWS Lambda?
- Tecnologias de Big Data
- Arquitetura de mineração de dados
- Serviços de armazenamento da AWS
- Guia para concorrentes da AWS com recursos