

Diferença entre o Apache Hive e o Apache HBase -
A história do Apache Hive começa no ano de 2007, quando programadores que não são Java precisam lutar enquanto usam o Hadoop MapReduce. Pesquisadores e desenvolvedores previram que amanhã é uma era do Big Data. Já diferentes formatos de dados como estruturado, semiestruturado e não estruturado estavam se acumulando. Até o Facebook estava lutando com a maior quantidade de processamento de dados. Pesquisadores do Facebook apresentaram o Apache Hive para processamento de dados no Hadoop Cluster. O Facebook foi a primeira empresa a criar o Apache Hive.
A história do Apache HBase começa em 2006, quando a startup Powerset, com sede em São Francisco, estava tentando criar um mecanismo de busca em linguagem natural para a web. O HBase é uma implementação do Bigtable do Google. Já percebemos por que havia a necessidade de criar outra arquitetura de armazenamento? O Sistema de Gerenciamento de Banco de Dados Relacional existe desde o início dos anos 70. Existem muitos casos de uso para os quais os bancos de dados relacionais fazem sentido perfeitamente, mas para alguns problemas específicos, o modelo relacional não se encaixa muito bem.
Deixe-me explicar sobre o Apache Hive e o Apache HBase em mais detalhes.
Diferenças entre o Apache Hive e o Apache HBase
O Apache Hive é um projeto de código-fonte aberto Apache, construído sobre o Hadoop, para consultar, resumir e analisar grandes conjuntos de dados usando uma interface semelhante a SQL. O Apache Hive fornece uma linguagem semelhante ao SQL chamada HiveQL, que converte consultas de forma transparente ao MapReduce para execução em grandes conjuntos de dados armazenados no HDFS (Hadoop Distributed File System). O Apache Hive é um componente de cluster do Hadoop que normalmente é implementado pelos analistas de dados. O Apache hive é usado para processamento em lote de grandes tarefas ETL. O Apache Hive também suporta consultas SQL em lote em conjuntos de dados muito grandes. O Apache Hive aumenta a flexibilidade do design do esquema e também a serialização e desserialização de dados. O Apache Hive não suporta o Online Transaction Processing (OLTP) porque o hive não suporta consultas em tempo real e atualizações em nível de linha.
O Apache HBase é um banco de dados NoSQL de código aberto que fornece acesso em tempo real, leitura e gravação a grandes conjuntos de dados. NoSQL é um banco de dados não relacional. O Apache HBase é um banco de dados orientado a colunas distribuído que é executado sobre o HDFS (Hadoop Distributed File System). Portanto, o HBase traz benefícios do NoSQL ao Hadoop. O Apache HBase fornece recursos de acesso aleatório aos dados presentes no HDFS. Ele aproveita a tolerância a falhas fornecida pelo HDFS. O usuário pode armazenar os dados no HDFS diretamente ou através do HBase.
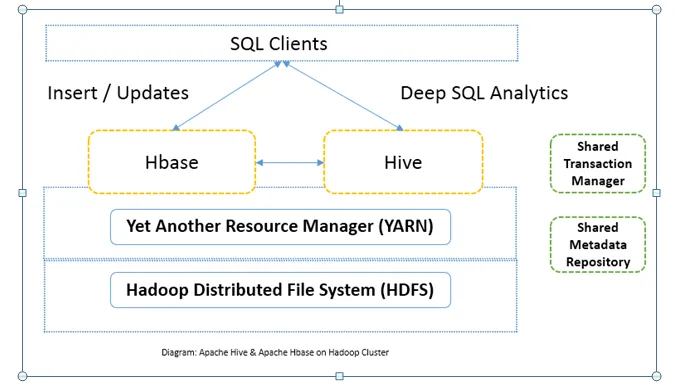
Comparação cara a cara entre Apache Hive x Apache HBase (Infográficos)
Abaixo está a diferença entre os 12 principais entre o Apache Hive e o Apache HBase

Principais diferenças - Apache Hive vs Apache HBase
Abaixo estão as listas de pontos, descreva as principais diferenças entre o Apache Hive e o Apache HBase:
- O Apache HBase é um banco de dados, enquanto o Apache Hive é um mecanismo de banco de dados.
- O Apache Hive é usado principalmente para processamento em lote (OLAP), enquanto o Apache HBase é usado principalmente para processamento transacional (OLTP).
- O Apache Hive executa a maioria das consultas SQL, enquanto o Apache HBase não permite consultas SQL diretamente.
- O Apache Hive não suporta operações em nível de registro, como atualização, inserção e exclusão, enquanto o Apache HBase suporta operações em nível de registro, como atualização, inserção e exclusão.
- O Apache Hive é executado sobre o MapReduce, enquanto o Apache HBase é executado sobre o HDFS (Hadoop Distributed File System).
O Apache Hive consulta os arquivos definindo uma tabela virtual e executando consultas HQL sobre ela. É um processo em que os arquivos estão virtualmente conectados a uma tabela como estrutura e o usuário pode executar o Hive Query Language (HQL) e essas consultas são convertidas no MapReduce Job pelo Hive. O usuário não precisa gravar a tarefa MapReduce, as consultas HQL são convertidas internamente em arquivos jar e esses arquivos jar serão implementados nos conjuntos de dados.
Enquanto no Apache HBase, as tabelas são divididas em regiões e são servidas pelos servidores da região. Outras regiões são divididas verticalmente por famílias de colunas em lojas e as Lojas são salvas como arquivos no HDFS.
Quando usar o Apache Hive:
- Requisitos de armazenamento de dados
- Consultas analíticas
- Análise de dados familiarizada com SQL
Quando usar o Apache HBase:
- Processamento de dados rápido e interativo
- Consultas em tempo real
- Pesquisas rápidas
- Processamento no servidor
- Acesso aleatório de leitura / gravação ao Big Data
- Escalabilidade de aplicativos
O Apache Hive pode ser usado para calcular tendências e registros do site de comércio eletrônico por uma determinada duração, região ou fuso horário. Ele pode ser usado para processar consultas em lote sobre dados históricos, enquanto o Apache HBase pode ser usado pelo Facebook ou LinkedIn para mensagens e análises em tempo real. Também pode ser usado para contar gostos.
Tabela de comparação Apache Hive vs Apache HBase
Estou discutindo os principais artefatos e distinguindo entre Apache Hive e Apache HBase.
| Apache Hive | Apache HBase | |
| Processamento de dados | O Apache Hive é usado para
processamento em lote, ou seja, OLAP (Online Analytical Processing) | O Apache HBase é usado para processamento transacional, ou seja, Online Transactional Processing (OLTP) |
| Velocidade de processamento | O Apache Hive tem latência mais alta devido à execução da tarefa MapReduce em segundo plano | O Apache HBase trabalha com consultas em tempo real e muito mais rápido que o Apache Hive |
| Compatibilidade com o Hadoop | O Apache Hive é executado sobre o MapReduce | O Apache HBase é executado em cima do HDFS |
| Definição | O Apache Hive é de código aberto e semelhante ao SQL usado para consultas analíticas | O Apache HBase é um banco de dados NoSQL de código aberto usado para consultas em tempo real |
| Metadados compartilhados | Os dados criados no Apache Hive são visíveis automaticamente no Apache HBase | Os dados criados no Apache HBase são automaticamente visíveis no Apache Hive |
| Esquema | O Apache hive suporta o Esquema para inserir dados em tabelas | O Apache HBase é um banco de dados livre de esquema. |
| Atualizar recurso | O recurso de atualização é complicado no Apache Hive | O usuário pode facilmente atualizar os dados no Apache HBase |
| Operações | As operações no Apache Hive não são executadas em tempo real | As operações no Apache HBase são executadas em tempo real |
| Tipos de dados | O Apache Hive é destinado a dados estruturados e semiestruturados | O Apache HBase é para dados não estruturados. |
| Nível de Consistência | Apache hive suporta Consistência Eventual | O Apache HBase suporta consistência imediata |
| Métodos de Partição | O Apache Hive suporta os recursos Sharding | O Apache HBase também suporta os recursos Sharding |
| Armazenamento de dados | A data é armazenada no Hive Metastore, partições e baldes no Apache Hive | Os dados são armazenados em colunas e tabelas em linhas no Apache HBase |
Conclusão - Apache Hive vs Apache HBase
Geralmente o Apache Hive vs o Apache HBase são usados juntos no mesmo cluster. Ambos podem ser usados juntos para aumentar o poder de processamento. Desde que o hive melhora os lados analíticos do HDFS, enquanto o HBase aprimora as transações em tempo real. O usuário pode usar o Hive como uma ferramenta ETL para inserções em lote com os dados no HBase e, em seguida, executar consultas que podem associar ainda mais os dados presentes nas tabelas HBase aos dados que já estão presentes no HDFS. Os dados podem ser lidos e gravados do Apache Hive para o HBase e vice-versa. A interface entre o Apache Hive e o Apache HBase ainda está em fase de maturação. Há muito mais por vir. Ainda assim, posso dizer que o Apache Hive e o Apache HBase tornam o cluster do Hadoop mais robusto e poderoso.
Artigos relacionados:
Este foi um guia do Apache Hive vs Apache HBase, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- As 5 principais tendências de big data
- 5 desafios do Big Data Analytics
- Como quebrar a entrevista do desenvolvedor do Hadoop?
- 5 desafios do Big Data Analytics