

Introdução aos comandos do Hive
O comando Hive é uma ferramenta de infraestrutura de data warehouse que fica no topo do Hadoop para resumir o Big Data. Ele processa dados estruturados. Isso facilita a consulta e análise de dados. O comando Hive também é chamado de "esquema na leitura". O Hive não verifica os dados quando são carregados, a verificação ocorre apenas quando uma consulta é emitida. Essa propriedade do Hive facilita o carregamento inicial. É como copiar ou simplesmente mover um arquivo sem colocar restrições ou verificações. A colméia foi desenvolvida primeiro pelo Facebook. A Apache Software Foundation o adotou mais tarde e o desenvolveu.
Aqui estão os componentes do comando Hive:
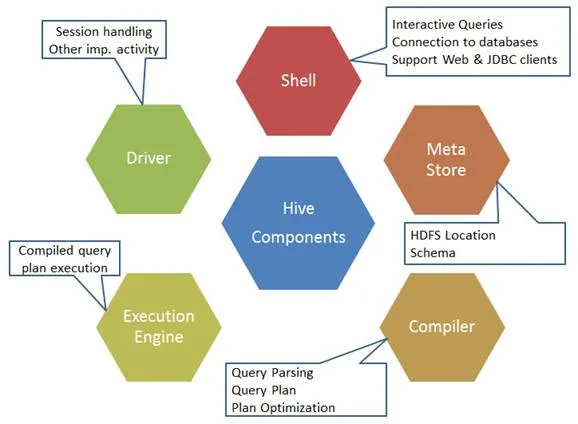
Fig 1. Componentes do Hive
https://www.developer.com/
Aqui estão os recursos do comando Hive listados abaixo:
- As lojas do Hive são um conjunto de dados brutos e processados no Hadoop.
- Ele foi projetado para o processamento de transações on-line (OLTP). O OLTP é o sistema que facilita os dados de grande volume em muito menos tempo, sem depender do servidor único.
- É rápido, escalável e confiável.
- A linguagem de consulta do tipo SQL fornecida aqui é chamada HiveQL ou HQL. Isso facilita as tarefas ETL e outras análises.
Fig 2. Propriedades da seção
Fontes de imagens: - Google
Existem algumas limitações do comando Hive, também listadas abaixo:
- O Hive não suporta subconsultas.
- O Hive certamente suporta sobrescrições, mas, infelizmente, não suporta exclusão e atualizações.
- O Hive não foi projetado para OLTP, mas é usado para isso.
Para entrar no shell interativo do Hive:
$ HIVE_HOME / bin / hive
Comandos básicos do Hive
-
Crio
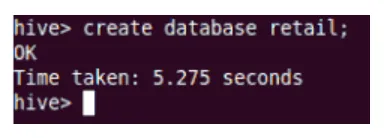
Isso criará o novo banco de dados no Hive.
-
Solta
A gota removerá uma tabela do Hive
-
Alterar
O comando Alter o ajudará a renomear a tabela ou colunas da tabela.
Por exemplo:
seção> ALTER TABLE employee RENAME TO employee1;
-
exposição
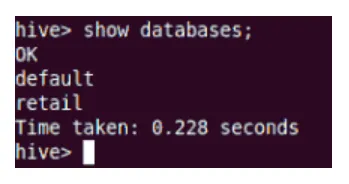
O comando Show mostrará todos os bancos de dados residentes no Hive.
-
Descrever
O comando Descrever ajudará você com as informações sobre o esquema da tabela.
Comandos intermediários de ramificação
O Hive divide uma tabela em partições relacionadas de várias maneiras com base em colunas. Usando essas partições, fica mais fácil consultar dados. Essas partições ainda são divididas em buckets, para executar consultas com eficiência nos dados.
Em outras palavras, os buckets distribuem dados no conjunto de clusters calculando o código de hash da chave mencionado na consulta.
-
Adicionando Partição
A adição de partição pode ser realizada alterando a tabela. Digamos que você tenha a tabela "EMP", com campos como Id, Nome, Salário, Departamento, Designação e yoj.
colméia> funcionário da ALTER TABLE
> ADICIONAR PARTIÇÃO (ano = '2012')
localização '/ 2012 / part2012';
-
Renomeando partição
colméia> ALTER TABLE funcionário PARTIÇÃO (ano = '1203')
Renomear para a partição (Yoj = '1203');
-
Drop Partition
colméia> ALTER TABLE funcionário DROP (SE EXISTE)
> PARTIÇÃO (ano = '1203');
-
Operadores relacionais
Operadores relacionais consistem em um determinado conjunto de operadores, que ajuda na busca de informações relevantes.
Por exemplo: digamos que sua tabela "EMP" tenha a seguinte aparência:
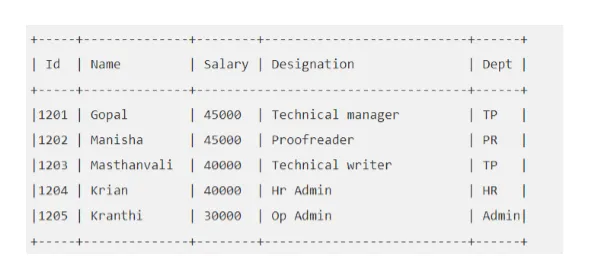
Vamos executar a consulta do Hive, que buscará o funcionário cujo salário é maior que 30000.
seção> SELECT * FROM EMP WHERE Salário> = 40000;
-
Operadores aritméticos
São operadores que ajudam na execução de operações aritméticas nos operandos e, por sua vez, sempre retornam tipos de números.
Por exemplo: Para adicionar dois números, como 22 e 33
seção> SELECT 22 + 33 ADICIONAR DE temp;
-
Operador lógico
Esses operadores devem executar operações lógicas, que sempre retornam True / False.
seção> SELECT * FROM EMP WHERE Salário> 40000 && Dept = TP;
Comandos avançados do Hive
-
Visão
O conceito de exibição no Hive é semelhante ao do SQL. A visualização pode ser criada no momento da execução de uma instrução SELECT.
Exemplo:
seção> CREATE VIEW EMP_30000 AS
SELECIONE * DO EMP
ONDE salário> 30000;
-
Carregando dados na tabela
Hive> Carrega o caminho local de dados '/home/hduser/Desktop/AllStates.csv' nos estados da tabela;
Aqui "States" é a tabela já criada no Hive.
https://www.tutorialspoint.com/hive/
O Hive possui algumas funções internas que ajudam você a obter seu resultado de uma maneira melhor.
Como redondo, andar, BIGINT etc.
-
Junte-se
A cláusula de junção pode ajudar na junção de duas tabelas com base no mesmo nome da coluna.
Exemplo:
seção> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
DE CLIENTES c JUNTAR PEDIDOS o
LIGADO (c.ID = o.CUSTOMER_ID);
Todos os tipos de junções são suportados pelo Hive: junção externa esquerda, junção externa direita, junção externa completa.
Dicas e truques para usar comandos de seção
O Hive torna o processamento de dados tão fácil, direto e extensível, que o usuário presta menos atenção para otimizar as consultas do Hive. Mas prestar atenção em poucas coisas ao escrever a consulta do Hive certamente trará grande sucesso no gerenciamento da carga de trabalho e na economia de dinheiro. Abaixo estão algumas dicas sobre isso:
- Partições e buckets: o Hive é uma ferramenta de big data, que pode consultar grandes conjuntos de dados. No entanto, escrever a consulta sem entender o domínio pode trazer grandes partições no Hive.
Se o usuário estiver ciente do conjunto de dados, as colunas relevantes e altamente usadas poderão ser agrupadas na mesma partição. Isso ajudará na execução da consulta de maneira mais rápida e ineficiente.
Em última análise, o não. O mapeador e as operações de E / S também serão reduzidas.
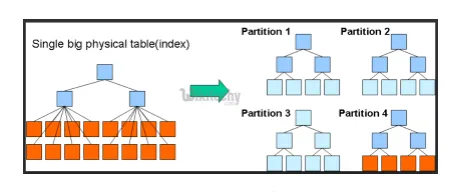
Fig 3. Particionamento
Fontes de imagens: imagem do Google
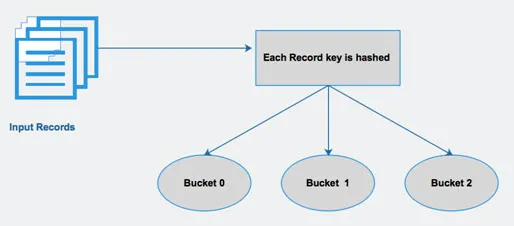
Fig 4 Bucketing
Fontes de imagens: - Google image
- Execução Paralela: O Hive executa a consulta em vários estágios. Em alguns casos, esses estágios podem depender de outros, portanto, não podem ser iniciados, uma vez que o estágio anterior esteja concluído. No entanto, tarefas independentes podem ser executadas paralelamente para economizar tempo de execução geral. Para habilitar a execução paralela no Hive:
defina hive.exec.parallel = true;
Portanto, isso aumentará a utilização do cluster.
- Amostragem em bloco: a amostragem de dados de uma tabela permitirá a exploração de consultas nos dados.
Apesar da resistência, preferimos amostrar o conjunto de dados de maneira mais aleatória. A amostragem em bloco vem com várias sintaxes poderosas, o que ajuda na amostragem dos dados de várias maneiras.
A amostragem pode ser usada para encontrar aprox. informações do conjunto de dados, como a distância média entre origem e destino.
Consultar 1% dos grandes dados dará quase a resposta perfeita. A exploração fica muito mais fácil e eficaz.
Conclusão - Comandos do Hive
O Hive é uma abstração de nível superior sobre o HDFS, que fornece uma linguagem de consulta flexível. Ajuda na consulta e processamento de dados de uma maneira mais fácil.
O Hive pode ser batido com outros elementos de Big Data, para aproveitar sua funcionalidade de maneira completa.
Artigos recomendados
Este foi um guia para os comandos do Hive. Aqui discutimos comandos básicos e avançados do Hive e alguns comandos imediatos do Hive. Você também pode consultar o seguinte artigo para saber mais -
- Hive Interview Questions
- Hive VS Hue - As 6 melhores comparações úteis
- Comandos do Tableau
- Comandos do Adobe Photoshop
- Usando a função ORDER BY no Hive
- Baixe e instale o Hive passo a passo