
Diferença entre Hive e HBase
O Apache Hive e o HBase são tecnologias de big data baseadas no Hadoop. Os dois costumavam consultar dados. O Hive e o HBase são executados no Hadoop e diferem em sua funcionalidade. O Hive é um dialeto SQL baseado em redução de mapa, enquanto o HBase suporta apenas o MapReduce. O HBase armazena dados na forma de pares de chave / valor ou família de colunas, enquanto o Hive não armazena dados.
Diferenças cara a cara entre Hive x HBase (Infográficos)
Abaixo está a diferença top 8 entre Hive vs HBase
Principais diferenças entre Hive x HBase
- O Hbase é compatível com ACID, enquanto o Hive não é.
- O Hive suporta critérios de particionamento e filtro com base no formato da data, enquanto o HBase suporta o particionamento automatizado.
- O Hive não suporta instruções de atualização, enquanto o HBase as suporta.
- O Hbase é mais rápido quando comparado ao Hive na busca de dados.
- O Hive é usado para processar dados estruturados, enquanto o HBase, por ser livre de esquema, pode processar qualquer tipo de dados.
- O Hbase é altamente escalável (horizontalmente) quando comparado ao Hive.
- O Hive analisa os dados no HDFS com o suporte das consultas SQL e, em seguida, eles convertem isso em um mapa e reduzem os trabalhos, enquanto no Hbase, como é o fluxo em tempo real, ele executa diretamente suas operações no banco de dados particionando em tabelas e famílias de colunas.
- ao chegar à consulta do data hive, usa um shell conhecido como shell do Hive para emitir os comandos, enquanto o HBase, como é o banco de dados, usaremos um comando para processar os dados no HBase.
- Para acessar o shell do Hive, usaremos o comando hive. Depois de dar isso, ele aparecerá como seção>. No HBase, simplesmente damos como Usar HBase.
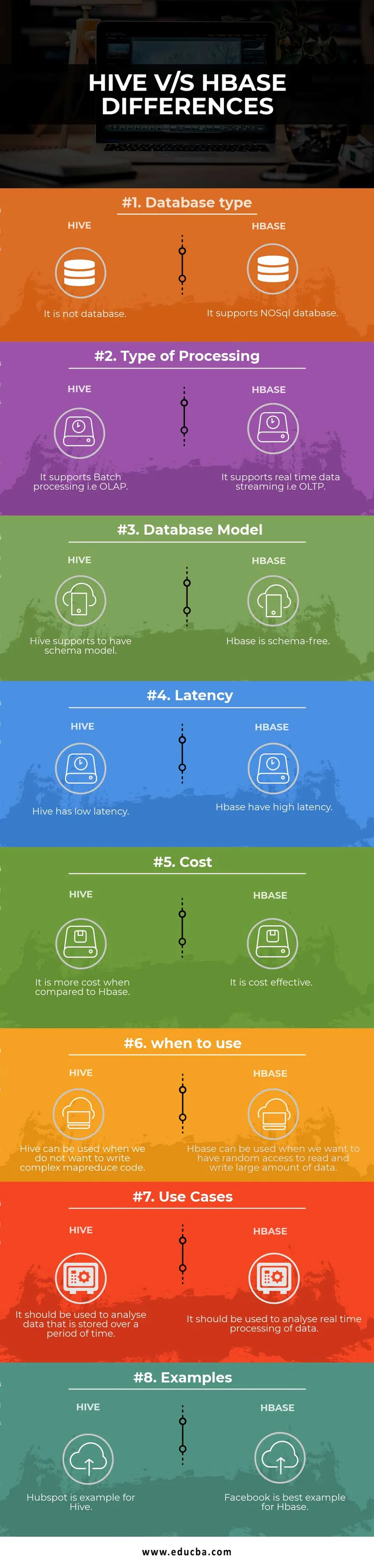
Tabela de comparação Hive vs HBase
| Base para comparação | Colmeia | Hbase |
| Tipo de banco de dados | Não é um banco de dados | Suporta banco de dados NoSQL |
| Tipo de processamento | Ele suporta processamento em lote, ou seja, OLAP | Ele suporta streaming de dados em tempo real, ou seja, OLTP |
| Modelo de banco de dados | O Hive suporta ter modelo de esquema | Hbase é livre de esquema |
| Latência | O Hive possui baixa latência | Hbase possui alta latência |
| Custo | É mais caro quando comparado ao HBase | É rentável |
| quando usar | O Hive pode ser usado quando não queremos escrever código MapReduce complexo | O HBase pode ser usado quando queremos ter acesso aleatório para ler e gravar uma grande quantidade de dados |
| Casos de uso | Deve ser usado para analisar dados armazenados durante um período de tempo | Deve ser usado para analisar o processamento de dados em tempo real. |
| Exemplos | Hubspot é um exemplo para o Hive | O Facebook é o melhor exemplo para o Hbase |
Diferenças na codificação entre Hive e HBase
Vamos agora discutir as diferenças básicas entre Hive e HBase na codificação.
| Base para comparação | Colmeia | Hbase |
| Para criar um banco de dados | CRIAR DATABASE (SE NÃO EXISTE) DATABASE-NAME; | Como o Hbase é um banco de dados, não precisamos criar um banco de dados específico |
| Para descartar um banco de dados | DROP DATABASE (SE EXISTE) DATABASE-NAME (RESTRITO OU CASCATA); | N / D |
| Para criar uma tabela | CRIAR TABELA (TEMPORÁRIA OU EXTERNA) (SE NÃO EXISTIR) NOME DA TABELA ((nome da coluna nome_do_dado) (comentário da coluna comentário), ….)) (comentário da tabela comentário) (formato de linha ROW FORMAT) (armazenado como formato de arquivo) | CRIO '', '' |
| Para alterar uma tabela | ALTER TABLE nome RENOMEAR PARA novo nome
ALTER TABLE nome DROP (COLUMN) nome da coluna ALTER TABLE nome ADD COLUMNS (especificação de col (, espec de col ..)) ALTER TABLE nome CHANGE nome da coluna novo nome novo tipo ALTER TABLE nome SUBSTITUIR COLUNAS (col-spec (, col-spec ..)) | ALTER 'NOME DA TABELA', NOME => 'NOME DA COLUNA', VERSÕES => |
| Desabilitando uma tabela | N / D | desativar 'TABLE-NAME' -> para desativar o nome da tabela especificado
disable_all 'r *' -> para desativar todas as tabelas que correspondem à expressão regular |
| Habilitando uma tabela | N / D | ative 'TABLE-NAME' |
| Para soltar uma tabela | DROP TABLE SE EXISTE nome da tabela | Se quisermos soltar uma tabela, primeiro precisamos desativá-la
desativar 'nome da tabela' solte 'nome da tabela' Da mesma forma, podemos usar disable_all e drop_all para excluir as tabelas que correspondem à expressão regular especificada. |
| Para listar bancos de dados | mostre bancos de dados; | N / D |
| Para listar tabelas no banco de dados | mostrar tabelas; | Lista |
| Para descrever o esquema de uma tabela | descreva o nome da tabela; | descrever 'nome da tabela' |
Integração do Hive vs HBase
- Instale e configure o Hive.
- Instale e configure o HBase.
- Para a integração do Hive e do HBase, usamos STORAGE HANDLERS no Hive.
- Manipuladores de armazenamento é uma combinação de SERDE, InputFormat, OutputFormat que aceita qualquer entidade externa como uma tabela no Hive.
- Portanto, esse recurso ajuda o usuário a emitir consultas SQL, seja a tabela presente no Hadoop ou no banco de dados NOSQL, como HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Agora, veremos um exemplo para conectar o Hive ao HBase usando o HiveStorageHandler:
- Primeiro, precisamos criar a tabela Hbase usando o comando
criar 'Aluno', 'informação pessoal', 'informação do departamento'
-> Informações pessoais e informações do departamento criam duas famílias de colunas diferentes na tabela Aluno.
- Precisamos inserir alguns dados na tabela Student. Por exemplo, conforme mencionado abaixo.
put 'student', 'sid01', 'personalinfo: name', 'Ram'
coloque 'aluno', 'sid01', 'informações pessoais: mailid', ' '
Coloque 'aluno', 'sid01', 'deptinfo: deptname', 'Java'
Coloque 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> Da mesma forma, podemos criar dados para sid02, sid03…
- Agora precisamos criar a tabela do Hive apontando para a tabela do HBase.
- Para cada coluna no Hbase, criaremos uma tabela específica para essa coluna no Hive.Neste caso, criaremos 2 tabelas no Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Da mesma forma, precisamos criar a tabela de detalhes das informações do departamento na seção.
- Agora podemos escrever a consulta SQL em uma seção, conforme mencionado abaixo.
select * from student_hbase;
Dessa forma, podemos integrar o Hive ao HBase.
Conclusão - Hive vs HBase
Conforme discutido, ambas são tecnologias diferentes que fornecem funcionalidades diferentes nas quais o Hive trabalha usando a linguagem SQL e também pode ser chamado, pois o HQL e o HBase usam pares de valores-chave para analisar os dados. O Hive e o HBase funcionam melhor se forem combinados porque o Hive tem baixa latência e pode processar uma enorme quantidade de dados, mas não pode manter dados atualizados, e o HBase não suporta análise de dados, mas suporta atualizações em nível de linha em grande quantidade De dados.
Artigo recomendado
Este foi um guia para o Hive vs HBase, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- Apache Pig vs Apache Hive - As 12 principais diferenças úteis
- Descubra as 7 melhores diferenças entre Hadoop e HBase
- Top 12 Comparação de Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Descubra as melhores diferenças