

Introdução à ANOVA em R
O artigo a seguir ANOVA em R fornece um esboço para comparar o valor médio de diferentes grupos. Uma Análise de Variância (ANOVA) é uma técnica muito comum usada para comparar o valor médio de diferentes grupos. O modelo ANOVA é usado para teste de hipóteses, onde certas suposições ou parâmetros são gerados para uma população e o método estatístico é usado para determinar se a hipótese é verdadeira ou falsa.
A hipótese é derivada da suposição do pesquisador e das informações disponíveis sobre a população. A ANOVA é chamada de Análise de Variância e é usada para testes de hipóteses em que é necessário medir as médias de uma variável em vários grupos independentes.
Por exemplo, em um laboratório para estudar ou inventar um novo medicamento para obesidade, os pesquisadores compararão o resultado do tratamento experimental e padrão. Em um estudo sobre obesidade, resultados valiosos podem ser obtidos quando a taxa média de obesidade da população pode ser comparada em diferentes faixas etárias. Nesse caso, gostaríamos de observar a taxa média de obesidade entre diferentes faixas etárias, como idade (5 a 18), (19, 35) e (36 a 50). O método ANOVA é aplicado, pois existem mais de dois grupos independentes. O método ANOVA é utilizado para comparar a obesidade média dos grupos independentes. A função aov () é usada e a sintaxe é aov (fórmula, dados = quadro de dados). Neste artigo, aprenderemos sobre o modelo ANOVA e discutiremos melhor o modelo ANOVA unidirecional e bidirecional, além de exemplos.
Por que ANOVA?
- Essa técnica é usada para responder à hipótese enquanto analisa vários grupos de dados. Existem várias abordagens estatísticas, no entanto, a ANOVA em R é aplicada quando a comparação precisa ser feita em mais de dois grupos independentes, como no exemplo anterior, em três faixas etárias diferentes.
- A técnica ANOVA mede a média dos grupos independentes para fornecer aos pesquisadores o resultado da hipótese. Para obter resultados precisos, é necessário levar em consideração a média da amostra, o tamanho da amostra e o desvio padrão de cada grupo individual.
- É possível observar a média individualmente para cada um dos três grupos para comparação. No entanto, essa abordagem tem limitações e pode ser incorreta, porque essas três comparações não consideram dados totais e, portanto, podem levar ao erro do tipo 1. R nos fornece a função de realizar a análise ANOVA para examinar a variabilidade entre os grupos independentes de dados. Existem cinco estágios de condução da análise ANOVA. No primeiro estágio, os dados são organizados no formato csv e a coluna é gerada para cada variável. Uma das colunas seria uma variável dependente e as restantes são a variável independente. No segundo estágio, os dados são lidos no R studio e nomeados adequadamente. No terceiro estágio, um conjunto de dados é anexado a variáveis individuais e lido pela memória. Finalmente, a ANOVA em R é definida e analisada. Nas seções abaixo, forneci alguns exemplos de estudos de caso nos quais as técnicas de ANOVA devem ser usadas.
- Seis inseticidas foram testados em 12 campos cada, e os pesquisadores contaram o número de insetos que permaneciam em cada campo. Agora, os agricultores precisam saber se os inseticidas fazem alguma diferença e, em caso afirmativo, qual deles melhor utiliza. Você responde a essa pergunta usando a função aov () para executar uma ANOVA.
- Cinqüenta pacientes receberam um dos cinco tratamentos com drogas redutoras de colesterol (trt). Três das condições de tratamento envolveram o mesmo medicamento administrado como 20 mg uma vez por dia (1 vez) 10 mg duas vezes por dia (2 vezes) 5 mg quatro vezes por dia (4 vezes). As duas condições restantes (drugD e drugE) representavam drogas concorrentes. Qual tratamento medicamentoso produziu a maior redução de colesterol (resposta)?
ANOVA Só de ida
- O método unidirecional é uma das técnicas básicas de ANOVA na qual a análise de variância é aplicada e o valor médio de vários grupos populacionais é comparado.
- A ANOVA unidirecional recebeu esse nome devido à disponibilidade de dados classificados unidirecionais. Em uma ANOVA unidirecional variável dependente única e uma ou mais variáveis independentes podem estar disponíveis.
- Por exemplo, executaremos a técnica ANOVA no conjunto de dados de colesterol. O conjunto de dados consiste em duas variáveis trt (que são tratamentos em 5 níveis diferentes) e variáveis de resposta. Variável independente - grupos de tratamento medicamentoso, variável dependente - média de 2 ou mais grupos ANOVA. A partir desses resultados, você pode confirmar que tomar as doses de 5 mg 4 vezes ao dia foi melhor do que tomar uma dose de 20 mg uma vez ao dia. O medicamento D tem melhores efeitos quando comparado ao medicamento E
O medicamento D fornece melhores resultados se tomado em doses de 20 mg em comparação com o medicamento E
Usa o conjunto de dados de colesterol no pacote multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
O teste ANOVA F para tratamento (trt) é significativo (p <0, 0001), fornecendo evidências de que os cinco tratamentos
# não são todos igualmente eficazes.
resumo (aov_model)
destacar (colesterol)

A função plotmeans () no pacote gplots pode ser usada para produzir um gráfico de médias de grupos e seus intervalos de confiança. Isso mostra claramente as diferenças de tratamentoinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
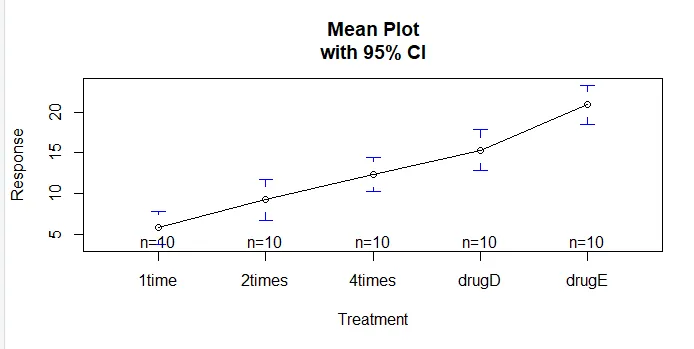
Vamos examinar a saída de TukeyHSD () para diferenças aos pares entre médias de grupos
TukeyHSD (aov_model)
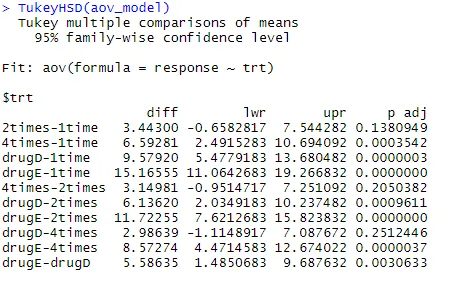
As reduções médias de colesterol por 1 e 2 vezes não são significativamente diferentes entre si (p = 0, 138), enquanto a diferença entre 1 e 4 vezes é significativamente diferente (p <0, 001).
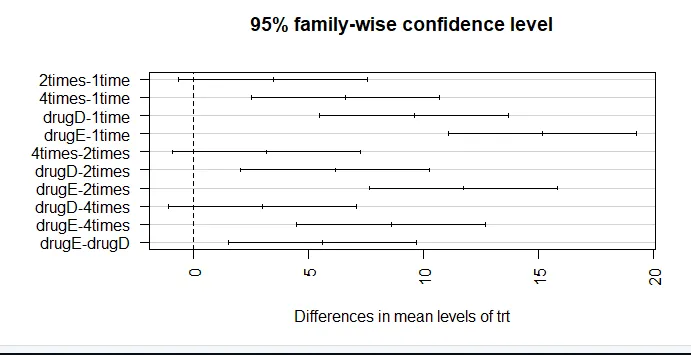
par (mar = c (5, 8, 4, 2)) # aumenta o gráfico da margem esquerda (TukeyHSD (aov_model), las = 2)
A confiança nos resultados depende do grau em que seus dados satisfazem as suposições subjacentes aos testes estatísticos. Em uma ANOVA unidirecional, presume-se que a variável dependente seja normalmente distribuída e tenha variância igual em cada grupo. Você pode usar um gráfico de QQ para avaliar a biblioteca de suposições de normalidade (carro).
Gráfico QQ (lm (resposta ~ trt, dados = colesterol), simulação = VERDADEIRO, principal = ”Gráfico QQ”, rótulos = FALSO)
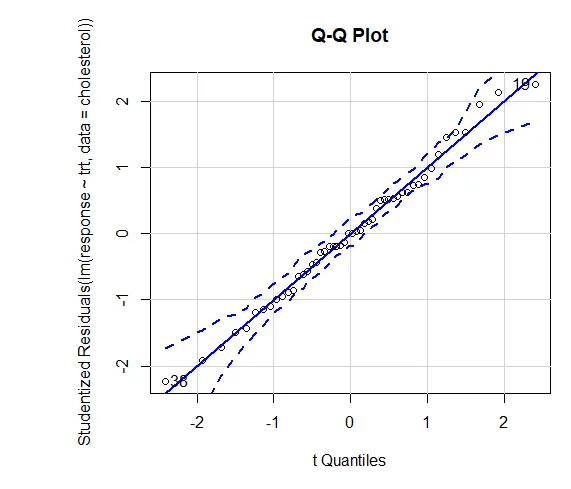
Linha pontilhada = envelope de confiança de 95%, sugerindo que a suposição de normalidade foi cumprida razoavelmente bem. A ANOVA assume que as variações são iguais entre os grupos ou amostras. O teste de Bartlett pode ser usado para verificar se essa suposição
bartlett.test (resposta ~ dados, = colesterol). O teste de Bartlett indica que as variações nos cinco grupos não diferem significativamente (p = 0, 97).
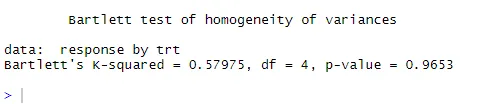
A ANOVA também é sensível ao teste de outliers para outliers usando a função outlierTest () no pacote do carro. Pode não ser necessário executar este pacote para atualizar sua biblioteca de carros.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
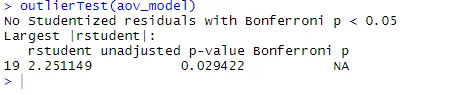
A partir da saída, você pode ver que não há indicação de outliers nos dados de colesterol (NA ocorre quando p> 1). Tomando o gráfico QQ, o teste de Bartlett e o teste externo, os dados parecem se encaixar muito bem no modelo ANOVA.
Anova de duas vias
Outra variável é adicionada no teste ANOVA de duas vias. Quando houver duas variáveis independentes, precisaremos usar ANOVA bidirecional em vez de ANOVA unidirecional, que foi usada no caso anterior em que tínhamos uma variável dependente contínua e mais de uma variável independente. Para verificar a ANOVA bidirecional, várias suposições precisam ser atendidas.
- Disponibilidade de observações independentes
- As observações devem ser normalmente distribuídas
- A variação deve ser igual nas observações
- Outliers não devem estar presentes
- Erros independentes
Para verificar a ANOVA bidirecional, outra variável chamada BP é adicionada ao conjunto de dados. A variável indica a taxa de pressão arterial em pacientes. Gostaríamos de verificar se existe alguma diferença estatística entre a PA e a dosagem administrada aos pacientes.
df <- read.csv ("arquivo.csv")
df
anova_two_way <- aov (resposta ~ trt + BP, dados = df)
resumo (anova_two_way)
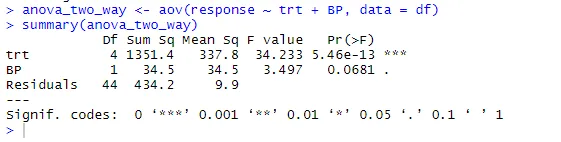
A partir do resultado, pode-se concluir que tanto a trt quanto a BP são estatisticamente diferentes de 0. Portanto, a hipótese nula pode ser rejeitada.
Benefícios da ANOVA em R
O teste ANOVA determina a diferença na média entre dois ou mais grupos independentes. Essa técnica é muito útil para a análise de vários itens, essencial para a análise de mercado. Usando o teste ANOVA, é possível obter as informações necessárias a partir dos dados. Por exemplo, durante uma pesquisa de produto em que várias informações, como listas de compras, gostos de clientes e desgostos, são coletadas dos usuários. O teste ANOVA nos ajuda a comparar grupos da população. O grupo pode ser masculino ou feminino ou vários grupos etários. A técnica ANOVA ajuda a distinguir entre os valores médios de diferentes grupos da população que são realmente diferentes.
Conclusão - ANOVA em R
ANOVA é um dos métodos mais comumente usados para teste de hipóteses. Neste artigo, realizamos um teste ANOVA no conjunto de dados que consiste em cinquenta pacientes que receberam tratamento medicamentoso para redução do colesterol e vimos como a ANOVA bidirecional pode ser realizada quando uma variável independente adicional está disponível.
Artigos recomendados
Este é um guia para ANOVA em R. Aqui discutimos o modelo Anova unidirecional e bidirecional, juntamente com exemplos e benefícios da ANOVA. Você também pode consultar nossos outros artigos sugeridos -
- Regressão vs ANOVA
- O que é o SPSS?
- Como interpretar resultados usando o teste ANOVA
- Funções em R