

Introdução à Árvore de Decisão na Mineração de Dados
No mundo de hoje em “Big Data”, o termo “Mineração de Dados” significa que precisamos examinar grandes conjuntos de dados e executar “mineração” nos dados e destacar o importante suco ou essência do que os dados desejam dizer. Uma situação muito análoga é a da mineração de carvão, onde são necessárias ferramentas diferentes para extrair o carvão enterrado nas profundezas do solo. Das ferramentas na mineração de dados, a “Árvore de Decisão” é uma delas. Assim, a mineração de dados em si é um vasto campo em que os próximos parágrafos aprofundaremos a “ferramenta” da Árvore de Decisão na Mineração de Dados.
Algoritmo da Árvore de Decisão na Mineração de Dados
Uma árvore de decisão é uma abordagem de aprendizado supervisionado, na qual treinamos os dados presentes já sabendo qual é a variável de destino. Como o nome sugere, esse algoritmo possui um tipo de estrutura em árvore. Vamos primeiro examinar o aspecto teórico da Árvore de Decisão e depois o mesmo em uma abordagem gráfica. Na Árvore de Decisão, o algoritmo divide o conjunto de dados em subconjuntos com base no atributo mais importante ou significativo. O atributo mais significativo é designado no nó raiz e é aí que a divisão ocorre de todo o conjunto de dados presente no nó raiz. Essa divisão feita é conhecida como nós de decisão. Caso não seja possível dividir mais, esse nó é denominado como nó folha.
Para parar o algoritmo para alcançar um estágio avassalador, é empregado um critério de parada. Um dos critérios de parada é o número mínimo de observações no nó antes que a divisão ocorra. Ao aplicar a árvore de decisão na divisão do conjunto de dados, é preciso ter cuidado para que muitos nós possam ter apenas dados ruidosos. Para atender a problemas de dados extremos ou barulhentos, empregamos técnicas conhecidas como remoção de dados. A remoção de dados não passa de um algoritmo para classificar dados do subconjunto, o que dificulta o aprendizado de um determinado modelo.
O algoritmo de árvore de decisão foi lançado como ID3 (dicotomizador iterativo) pelo pesquisador de máquina J. Ross Quinlan. Mais tarde, o C4.5 foi lançado como sucessor do ID3. Tanto o ID3 quanto o C4.5 são uma abordagem gananciosa. Agora, vejamos um fluxograma do algoritmo da Árvore de Decisão.
Para nosso entendimento de pseudocódigo, usaríamos "n" pontos de dados, cada um com atributos "k". O fluxograma abaixo é elaborado tendo em mente o "Ganho de informações" como condição para uma divisão.
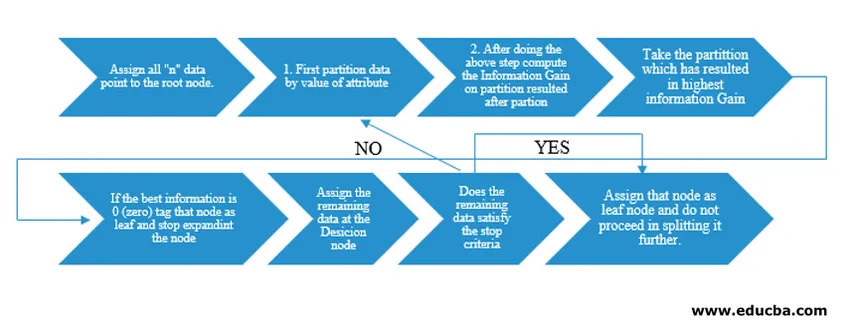
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Em vez do ganho de informação (IG), também podemos empregar o índice de Gini como critério de uma divisão. Para entender a diferença entre esses dois critérios em termos leigos, podemos pensar nesse ganho de informação como Diferença de entropia antes da divisão e após a divisão (divisão com base em todos os recursos disponíveis).
Entropia é como aleatoriedade e chegaríamos a um ponto após a divisão para ter o menor estado de aleatoriedade. Portanto, o ganho de informação precisa ser maior no recurso que queremos dividir. Caso contrário, se desejarmos dividir com base no Índice Gini, encontraremos o índice Gini para diferentes atributos e, usando o mesmo, descobriremos o Índice Gini ponderado para diferentes divisões e usaremos aquele com maior Índice Gini para dividir o conjunto de dados.
Termos importantes da árvore de decisão na mineração de dados
Aqui estão alguns dos termos importantes de uma árvore de decisão na mineração de dados fornecidos abaixo:
- Nó Raiz: Este é o primeiro nó em que a divisão ocorre.
- Nó Folha: Este é o nó após o qual não há mais ramificação.
- Nó de Decisão: O nó formado após a divisão dos dados de um nó anterior é conhecido como nó de decisão.
- Ramificação: subseção de uma árvore que contém informações sobre as consequências da divisão no nó de decisão.
- Remoção: Quando há uma remoção de subnós de um nó de decisão para atender a dados externos ou ruidosos, isso é chamado de remoção. Também é pensado para ser o oposto de dividir.
Aplicação da árvore de decisão na mineração de dados
A Árvore de Decisão possui um tipo de arquitetura de fluxograma embutido com o tipo de algoritmo. Essencialmente, ele possui um tipo de padrão “Se X, então Y mais Z” enquanto a divisão é feita. Esse tipo de padrão é usado para entender a intuição humana no campo programático. Portanto, pode-se usar isso extensivamente em vários problemas de categorização.
- Esse algoritmo pode ser amplamente utilizado no campo em que a função objetivo está relacionada com a análise realizada.
- Quando existem vários cursos de ação disponíveis.
- Análise outlier.
- Compreendendo o conjunto significativo de recursos de todo o conjunto de dados e "explorando" os poucos recursos de uma lista de centenas de recursos em big data.
- Selecionando o melhor voo para viajar para um destino.
- Processo de tomada de decisão baseado em diferentes situações circunstanciais.
- Análise de rotatividade.
- Análise de sentimentos.
Vantagens da árvore de decisão
Aqui estão algumas vantagens da árvore de decisão explicada abaixo:
- Facilidade de entendimento: a maneira como a árvore de decisão é retratada em suas formas gráficas facilita o entendimento de uma pessoa com formação não analítica. Especialmente para as pessoas na liderança que desejam analisar quais recursos são importantes apenas uma olhada na árvore de decisão que podem trazer sua hipótese.
- Exploração de dados: Como discutido, a obtenção de variáveis significativas é uma funcionalidade essencial da árvore de decisão e, usando a mesma, pode-se descobrir durante a exploração de dados a decisão de qual variável precisaria de atenção especial durante o curso da fase de mineração e modelagem de dados.
- Há muito pouca intervenção humana durante o estágio de preparação dos dados e, como resultado desse tempo consumido durante os dados, a limpeza é diminuída.
- A Árvore de Decisão é capaz de lidar com variáveis categóricas e também numéricas e também atender a problemas de classificação de várias classes.
- Como parte da suposição, as árvores de decisão não assumem uma estrutura espacial de distribuição e classificador.
Conclusão
Finalmente, para concluir, as Árvores de Decisão trazem uma classe totalmente diferente de não linearidade e atendem à resolução de problemas na não linearidade. Esse algoritmo é a melhor opção para imitar um pensamento em nível de decisão dos humanos e retratá-lo em uma forma matemática-gráfica. Ele adota uma abordagem de cima para baixo na determinação de resultados de novos dados invisíveis e segue o princípio de dividir e conquistar.
Artigos recomendados
Este é um guia para a Árvore de Decisão na Mineração de Dados. Aqui discutimos o algoritmo, a importância e a aplicação da árvore de decisão na mineração de dados, além de suas vantagens. Você também pode consultar os seguintes artigos para saber mais -
- Aprendizado de máquina de ciência de dados
- Tipos de técnicas de análise de dados
- Árvore de decisão em R
- O que é mineração de dados?
- Guia de várias metodologias de análise de dados