
Diferença entre HBase e Cassandra
O HBase é um banco de dados que usa o sistema de arquivos distribuídos Hadoop para armazenamento. O HBase é uma parte importante do HDFS e é executado em cima do Hadoop Cluster. O HBase não é um banco de dados relacional tradicional, requer uma abordagem de modelagem de dados diferente. Cassandra trabalha no modelo de replicação de dados, portanto, no caso de indisponibilidade de qualquer nó, não haverá perda de dados. Cassandra é um banco de dados distribuído significa que os dados podem ser acessados por um cliente de qualquer cluster e de qualquer nó
1.1) Cassandra:
Foi iniciado pelo Facebook, pois está sempre no requisito do aplicativo. O Cassandra foi iniciado em 2005 e disponibilizado ao público em 2008. O Cassandra foi desenvolvido para aplicativos sempre ativos, como redes sociais como Facebook e Twitter.
Cassandra trabalha na arquitetura "sempre ativa " e possui um modelo de nó ativo / ativo para que não haja SPoF (ponto único de falha). CQL (Cassandra Query Language) é a linguagem de consulta do Cassandra, mas com a mesma sintaxe do SQL. Ele suporta todos os principais sistemas operacionais, como Linux, Unix, OSX e Windows.
Sempre:
Cassandra é um banco de dados com um modelo de distribuição e todos os nós são iguais no cluster. Os dados são replicados em nós configuráveis, portanto, em caso de falha de alguns não. de nós não resultará na perda dos dados.
(Sempre no modelo)
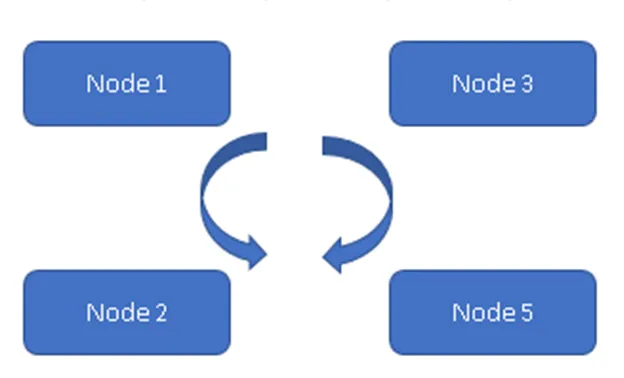
Na Figura 1, todos os quatro nós estão sincronizados entre si e replicando os dados no cluster. Todos estão trabalhando no modelo ativo-ativo, portanto, no caso de falha de qualquer nó, não resultará em perda de dados. Um cliente pode ler os dados do restante dos nós / nós disponíveis.
1.2) HBase:
O HBase é um banco de dados baseado em NoSQL e projetado para processar consultas em tabelas grandes com bilhões de linhas com milhões de colunas e rodar em um cluster de hardware comum / normal. Ele fornece recursos de consulta em tempo real com a velocidade de um " armazenamento de chave / valor " .
O HBase atualmente baseia / trabalha em um modelo de dados quadridimensional.
- ID da linha / chave da linha
- Família de colunas.
- Pares de valor-chave.
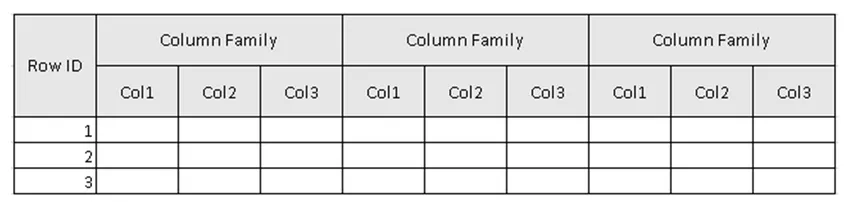
(Figura 2, esquema de exemplo da tabela no HBase.)
Na Figura 2, Tabela é a coleção de família de colunas e Família de colunas é a coleção de colunas. Colunas são a coleção de pares de valores-chave
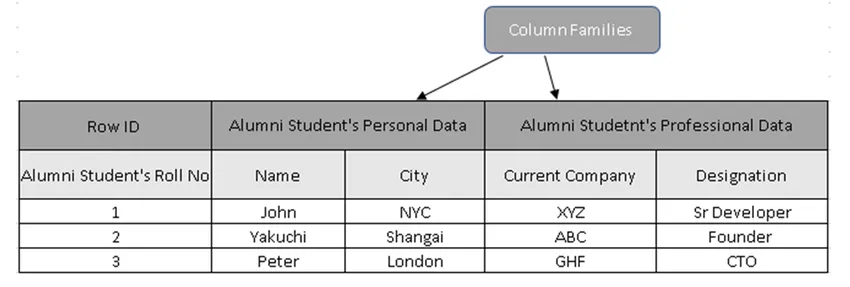
(Figura 3, Tabela de amostra no HBase)
Na Figura 3, as famílias da coluna são a coleta de dados dos alunos de ex-alunos e os IDs de linha (chaves de linha) contêm o número do rolo do aluno
De fato, as Chaves de Linha mantêm o valor exclusivo nos dados da Família de Colunas. Usando a chave de linha, é possível extrair todos os detalhes, razões pelas quais os bancos de dados orientados a colunas são muito mais rápidos que os bancos de dados tradicionais.
O Apache HBase pode ser usado para acesso aleatório de leitura / gravação e fornece suporte a falhas. Ele também suporta replicação e trabalho no modelo de banco de dados de distribuição.
Comparação cara a cara de HBase vs Cassandra (Infográficos)
Abaixo está a diferença top 9 entre HBase vs Cassandra
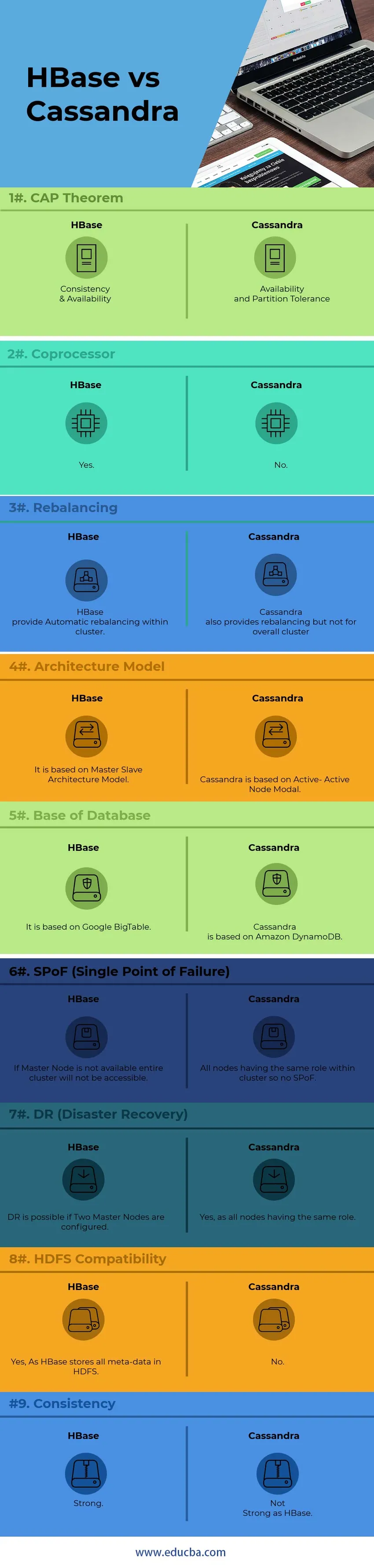 Principais diferenças entre HBase e Cassandra
Principais diferenças entre HBase e Cassandra
Abaixo estão as listas de pontos, descreva as principais diferenças entre o HBase e o Cassandra:
1) Para comunicação de nó interno, Cassandra usa o Protocolo GOSSIP enquanto o HBase é baseado no Zookeeper. Os serviços do Protocolo GOSSIP são integrados ao Cassandra do outro lado. O Zookeeper é um aplicativo de distribuição totalmente separado.
2) Na arquitetura Cassandra, todos os nós funcionam como Nó Ativo, enquanto o arquiteto HBase segue o modelo de Nó Mestre-Escravo. No modelo Nó Ativo-Ativo, não há SPoF (Ponto Único de Falha). No HBase, se o nó Mestre ficar inativo, todo o cluster não estará acessível.
3) HBase suporta o modelo de pesquisa de árvore binária, enquanto o Cassandra não suporta o modelo de árvore B Sem o B-Tree, você não pode pesquisar a Família de Colunas do Usuário para todos os que tenham um aniversário em abril, enquanto pode procurar todos os que vivem em Pequim com um Aniversário em abril.
4) HBase, suporta linguagens de script C, C ++, Java, Python, Scala, enquanto o Cassandra também suporta JavaScript e Ruby.
5) O HBase está tendo um recurso chamado coprocessador, enquanto o Cassandra não possui esse recurso a partir de agora. Os coprocessadores fornecem uma biblioteca e um ambiente de tempo de execução para executar o código do usuário no servidor da região HBase e nos processos principais.
6) O HBase foi projetado para suportar o data warehouse, enquanto o Cassandra será perfeito para aplicativos que executam o tempo todo, como aplicativos da Web e móveis.
7) A linguagem de consulta HBase é uma linguagem personalizada que precisa ser aprendida, enquanto o Cassandra usa seu próprio CQL (Cassandra Query Language) desenvolvido, que é uma linguagem semelhante ao SQL
8) Gerenciar o Cassandra é muito mais fácil que o HBase. No Cassandra, é necessário executar um único processo Java por nó, enquanto para o HBase, é necessário um HDFS totalmente operacional, vários processos do HBase e um sistema Zookeeper.
9) O HBase termina as somas de verificação de ponta a ponta e o reequilíbrio automático, enquanto o Cassandra não suporta o reequilíbrio do cluster em geral.
10) Baseado no " Teorema da CAP", Cassandra trabalha no modelo AP enquanto o HBase é o modelo CP.
Teorema da PAC
Este teorema é usado para sistemas distribuídos. C significa Consistência, A significa Disponibilidade e P é Tolerância de Partição. Teorema do CAP explicado abaixo:
C (Consistência): Consistência significa que se alguém tiver gravado um valor em um banco de dados, outros poderão ler imediatamente o mesmo valor.
R (Disponibilidade) : disponibilidade significa que se alguns nós não estiverem disponíveis no cluster (os nós foram desativados / não estiveram no cluster devido a algum problema) não afetarão o cluster inteiro e o sistema / banco de dados distribuído estará disponível para acessar os dados. O cluster estará acessível para todos os tipos de tarefas.
P (Tolerância de Partição): Tolerância de Partição significa que, se um Data Center ficar inativo ainda, isso não deve afetar os dados presentes nos nós e todos os dados devem estar acessíveis a qualquer momento. Significa que a tolerância à partição permite uma melhor replicação de dados para outros Data Center, bem como no ambiente do cluster.
Tabela de comparação HBase vs Cassandra
| Pontos | HBase | Cassandra |
| Teorema da PAC | Consistência e disponibilidade | Disponibilidade e tolerância de partição |
| Coprocessador | sim | Não |
| Rebalanceamento | O HBase fornece reequilíbrio automático dentro de um cluster. | Cassandra também fornece reequilíbrio, mas não para o cluster geral |
| Modelo de Arquitetura | É baseado no Modelo de Arquitetura Master-Slave | Cassandra é baseado no nó ativo-ativo modal |
| Base de Dados | É baseado no Google BigTable | Cassandra é baseado no Amazon DynamoDB |
| SPoF (ponto único de falha) | Se o Nó Mestre não estiver disponível, o cluster inteiro não estará acessível | Todos os nós com a mesma função no cluster, portanto, nenhum SPoF |
| DR (recuperação de desastres) | O DR é possível se Dois nós principais estiverem configurados. | Sim, como todos os nós com a mesma função |
| Compatibilidade com HDFS | Sim, como o HBase armazena todos os metadados no HDFS | Não |
| Consistência | Forte | Não é forte como HBase |
Conclusão - HBase vs Cassandra
O Facebook e outro lado das redes sociais prefeririam o HBase (anteriormente ambos usavam o Cassandra, consulte a publicação no Facebook) por causa de sua disponibilidade, outro setor de domínio bancário lateral procura segurança para todas as transações financeiras, para que eles selecionem o Cassandra no HBase.
As principais características do Cassandra envolvem alta disponibilidade, administração mínima e sem SPoF (ponto único de falha) do outro lado. O HBase é bom para ler e gravar dados mais rapidamente, com escalabilidade linear.
Empresas como Verizon, Bloomberg, Bank of America e muito mais estão usando o HBase e o Cassandra está sendo usado pelos principais sites de redes sociais como Twitter, Facebook, etc.
Não podemos concluir qual é o melhor, o HBase e o Cassandra estão tendo suas próprias vantagens e desvantagens. O desempenho real dos bancos de dados HBase e Cassandra pode ser visto no ambiente de produção.
Artigos recomendados:
Este foi um guia para HBase vs Cassandra, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- Hadoop vs Apache Spark - coisas interessantes que você precisa saber
- Como quebrar a entrevista do desenvolvedor do Hadoop?
- As 5 principais tendências de big data
- 5 desafios do Big Data Analytics