

O que é o algoritmo MapReduce?
O algoritmo MapReduce é principalmente inspirado no modelo de programação funcional. É usado para processar e gerar big data. Esses conjuntos de dados podem ser executados simultaneamente e distribuídos em um cluster. Um programa MapReduce consiste principalmente em um procedimento de mapeamento e um método de redução para executar a operação de resumo, como contar ou produzir alguns resultados. O sistema MapReduce funciona em servidores distribuídos que são executados em paralelo e gerenciam todas as comunicações entre diferentes sistemas. O modelo é uma estratégia especial da estratégia de divisão-aplicação-combinação que ajuda na análise de dados. O mapeamento é feito pela classe Mapper e reduz a tarefa pela classe Reducer.
Noções básicas sobre o algoritmo MapReduce
O algoritmo MapReduce funciona principalmente em três etapas:
- Função Mapa
- Função Aleatória
- Reduzir Função
Vamos discutir cada função e suas responsabilidades.
1. Função Mapa
Esta é a primeira etapa do algoritmo MapReduce. Ele pega os conjuntos de dados e os distribui em subtarefas menores. Isso é feito ainda em duas etapas, divisão e mapeamento. A divisão pega o conjunto de dados de entrada e divide o conjunto de dados enquanto o mapeamento pega esses subconjuntos de dados e executa a ação necessária. A saída desta função é um par de valores-chave.
2. Função Aleatória
Isso também é conhecido como função de combinação e inclui mesclagem e classificação. A mesclagem combina todos os pares de valores-chave. Todos estes terão as mesmas chaves. A classificação pega a entrada da etapa de mesclagem e classifica todos os pares de valores-chave, usando as chaves. Esta etapa também retornará aos pares de valores-chave. A saída será classificada.
3. Reduzir Função
Este é o último passo deste algoritmo. Ele retira os pares de valores-chave do shuffle e reduz a operação.
Como os algoritmos do MapReduce facilitam o trabalho?
Os sistemas de banco de dados relacional têm um servidor centralizado que ajuda a armazenar e processar os dados. Estes eram geralmente sistemas centralizados. Quando vários arquivos entram em cena, o processamento é entediante e cria um gargalo ao processar vários arquivos. O MapReduce mapeia o conjunto de dados e converte o conjunto de dados em que todos os dados são divididos em tuplas, e a tarefa de redução obtém a saída desta etapa e combina essas tuplas de dados em conjuntos menores. Ele funciona em diferentes fases e cria pares de valores-chave que podem ser distribuídos por diferentes sistemas.
O que você pode fazer com os algoritmos do MapReduce?
O MapReduce pode ser usado com uma variedade de aplicativos. Ele pode ser usado para pesquisa baseada em padrões distribuídos, classificação distribuída, reversão de gráfico de link da web, estatísticas de log de acesso à web. Também pode ajudar na criação e no trabalho em vários clusters, grades de área de trabalho, ambientes de computação voluntários. Também é possível criar ambientes dinâmicos em nuvem, ambientes móveis e também ambientes de computação de alto desempenho. O Google fez uso do MapReduce, que regenera o Índice do Google na World Wide Web. Ao usá-lo, os programas ad hoc antigos são atualizados e executam diferentes tipos de análise. Também integrou os resultados da pesquisa ao vivo sem reconstruir o índice completo. Todas as entradas e saídas são armazenadas no sistema de arquivos distribuído. Os dados transitórios são armazenados em um disco local.
Trabalhando com o algoritmo MapReduce
Para trabalhar com o algoritmo MapReduce, você deve conhecer o processo completo de como ele funciona. Os dados que são ingeridos seguem as seguintes etapas:
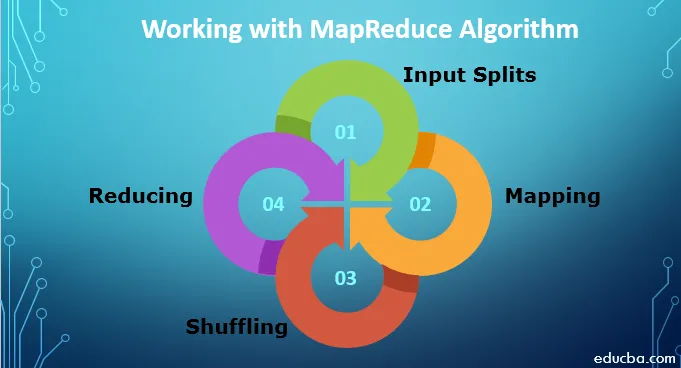
1. Divisões de entrada: todos os dados de entrada provenientes do trabalho MapReduce são divididos em partes iguais, conhecidas como divisões de entrada. É um pedaço de entrada que pode ser consumido por qualquer um dos mapeadores.
2. Mapeamento: Depois que os dados são divididos em partes, eles passam pela fase de mapeamento no programa de redução de mapas. Esses dados divididos são passados para a função de mapeamento que produz diferentes valores de saída.
3. Baralhar: Depois que o mapeamento é concluído, os dados são enviados para esta fase. Seu trabalho é juntar os registros necessários da fase anterior.
4. Redução: Nesta fase, a saída da fase de embaralhamento é agregada. Nesta fase, todos os valores são embaralhados e reunidos por agregação para que ele retorne um único valor de saída. Ele cria um resumo do conjunto de dados completo.
Vantagens do algoritmo MapReduce
Os aplicativos que usam o MapReduce têm as seguintes vantagens:
- Eles foram fornecidos com convergência e bom desempenho de generalização.
- Os dados podem ser manipulados usando aplicativos com uso intenso de dados.
- Ele fornece alta escalabilidade.
- Contar todas as ocorrências de cada palavra é fácil e possui uma enorme coleção de documentos.
- Uma ferramenta genérica pode ser usada para pesquisar a ferramenta em muitas análises de dados.
- Oferece tempo de balanceamento de carga em grandes agrupamentos.
- Também ajuda no processo de extração de contextos de localização do usuário, situações, etc.
- Ele pode acessar grandes amostras de respondentes rapidamente.
Por que devemos usar o algoritmo MapReduce?
O MapReduce é um aplicativo usado para o processamento de grandes conjuntos de dados. Esses conjuntos de dados podem ser processados em paralelo. O MapReduce pode potencialmente criar grandes conjuntos de dados e um grande número de nós. Esses grandes conjuntos de dados são armazenados no HDFS, o que facilita a análise dos dados. Ele pode processar qualquer tipo de dados como estruturado, não estruturado ou semiestruturado.
Por que precisamos do algoritmo MapReduce?
O MapReduce está crescendo rapidamente e ajuda na computação paralela. Ajuda a determinar o preço dos produtos e a obter os maiores lucros. Também ajuda a prever e recomendar análises. Ele permite que os programadores executem modelos em diferentes conjuntos de dados e usa técnicas estatísticas avançadas e técnicas de aprendizado de máquina que ajudam na previsão de dados. Ele filtra e envia os dados para diferentes nós no cluster e funciona de acordo com a função mapeador e redutor.
Como esta tecnologia o ajudará no crescimento da carreira?
O Hadoop está entre os trabalhos mais procurados atualmente. Está acelerando a taxa e a oportunidade que está crescendo muito rapidamente neste campo. Haverá um boom nessa área ainda mais. Os profissionais de TI que trabalham em Java têm um ponto positivo, pois são as pessoas mais procuradas. Além disso, desenvolvedores, arquitetos de dados, data warehouse e profissionais de BI podem receber grandes quantidades de salário aprendendo essa tecnologia.
Conclusão
MapReduce é o básico da estrutura do Hadoop. Ao aprender isso, você certamente entrará no mercado de análise de dados. Você pode aprendê-lo completamente e conhecer como grandes conjuntos de dados estão sendo processados e como essa tecnologia está trazendo uma mudança no processamento e armazenamento de dados.
Artigos recomendados
Este é um guia para os algoritmos do MapReduce. Aqui discutimos o conceito, entendimento, trabalho, necessidade, vantagens e crescimento na carreira. Você também pode acessar nossos outros artigos sugeridos para saber mais -
- Perguntas da entrevista do MapReduce
- O que é o MapReduce no Hadoop?
- Como o MapReduce funciona?
- O que é o MapReduce?
- Diferenças entre o Hadoop e o MapReduce
- Diferentes operações relacionadas a Tuplas