

Diferença entre Big Data e Apache Hadoop
Tudo está na Internet. A Internet tem muitos dados. Portanto, tudo é Big Data. Você sabia que 2, 5 Quintilhões de bytes de dados são criados todos os dias e se acumulam como Big Data? Nossas atividades diárias, como comentar, curtir, postar etc. nas mídias sociais como Facebook, LinkedIn, Twitter e Instagram, estão sendo adicionadas como Big Data. Supõe-se que, até o ano 2020, quase 1, 7 megabytes de dados serão criados a cada segundo, para todas as pessoas na Terra. Você pode imaginar e considerar quantos dados estão sendo gerados, assumindo cada pessoa na Terra. Hoje estamos conectados e compartilhando nossas vidas online. A maioria de nós está conectada online. Estamos morando em uma casa inteligente e usando veículos inteligentes e todos estão conectados aos nossos telefones inteligentes. Você já imaginou como esses dispositivos estão se tornando inteligentes? Eu gostaria de dar uma resposta muito simples, é por causa da análise de uma quantidade muito grande de dados, ou seja, Big Data. Dentro de cinco anos, haverá mais de 50 bilhões de dispositivos conectados inteligentes no mundo, todos desenvolvidos para coletar, analisar e compartilhar dados para tornar nossa vida mais confortável.
A seguir, apresentamos o Big Data vs Apache Hadoop
Apresentando o termo Big Data
O que é Big Data? Qual tamanho de Dados é considerado grande e será denominado Big Data? Temos muitas suposições relativas para o termo Big Data. É possível que a quantidade de dados diga que 50 terabytes podem ser considerados grandes volumes de dados para empresas iniciantes, mas pode não ser grande volume de dados para empresas como Google e Facebook. É porque eles têm a infraestrutura para armazenar e processar essa quantidade de dados. Gostaria de definir o termo Big Data como:
- Big Data é a quantidade de dados que vai além da capacidade da tecnologia de armazenar, gerenciar e processar com eficiência.
- Big Data são dados cuja escala, diversidade e complexidade exigem nova arquitetura, técnicas, algoritmos e análises para gerenciá-lo e extrair valor e conhecimento oculto.
- O big data são ativos de informações de grande volume, alta velocidade e alta variedade que exigem formas inovadoras e econômicas de processamento de informações que permitem uma percepção aprimorada, tomada de decisão e automação de processos.
- Big Data refere-se a tecnologias e iniciativas que envolvem dados muito diversificados, de rápida mudança ou maciços para que tecnologias, habilidades e infraestrutura convencionais possam lidar com eficiência. Dito de forma diferente, o volume, velocidade ou variedade de dados é muito grande.
3 V's de Big Data
- Volume: Volume refere-se à quantidade / quantidade na qual os dados estão sendo criados, a cada hora, as transações dos clientes do Wal-Mart fornecem à empresa cerca de 2, 5 petabytes de dados.
- Velocidade: velocidade refere-se à velocidade com que os dados estão se movendo, como os usuários do Facebook enviam, em média, 31, 25 milhões de mensagens e visualizam 2, 77 milhões de vídeos a cada minuto, todos os dias, na Internet.
- Variedade: variedade refere-se a diferentes formatos de dados criados como dados estruturados, semiestruturados e não estruturados. Como enviar e-mails com o anexo no Gmail são dados não estruturados, enquanto postar comentários com alguns links externos também é denominado como dados não estruturados. Compartilhar fotos, clipes de áudio e videoclipes são uma forma não estruturada de dados.
Armazenar e processar esse enorme volume, velocidade e variedade de dados é um grande problema. Precisamos pensar em outra tecnologia que não seja RDBMS for Big Data. Isso ocorre porque o RDBMS é capaz de armazenar e processar apenas dados estruturados. Então aqui o Apache Hadoop é um resgate.
Apresentando o Termo Apache Hadoop
O Apache Hadoop é uma estrutura de software de código aberto para armazenamento de dados e execução de aplicativos em clusters de hardware comum. O Apache Hadoop é uma estrutura de software que permite o processamento distribuído de grandes conjuntos de dados entre clusters de computadores usando modelos de programação simples. Ele foi projetado para expandir de servidores únicos para milhares de máquinas, cada uma oferecendo computação e armazenamento local. O Apache Hadoop é uma estrutura para armazenamento e processamento de Big Data. O Apache Hadoop é capaz de armazenar e processar todos os formatos de dados, como dados estruturados, semiestruturados e não estruturados. O Apache Hadoop é um hardware de código aberto e de mercadorias que trouxe revolução ao setor de TI. É facilmente acessível a todos os níveis de empresas. Eles não precisam investir mais para configurar o cluster Hadoop e em infraestrutura diferente. Vamos ver a diferença útil entre o Big Data e o Apache Hadoop em detalhes nesta postagem.
Estrutura do Apache Hadoop
A estrutura do Apache Hadoop é dividida em duas partes:
- Sistema de arquivos distribuídos do Hadoop (HDFS): essa camada é responsável pelo armazenamento de dados.
- MapReduce: essa camada é responsável pelo processamento de dados no Hadoop Cluster.
O Hadoop Framework é dividido em arquitetura mestre e escravo. Camada Sistema de arquivos distribuídos (HDFS) do Hadoop Nome O nó é componente principal enquanto o Nó de dados é componente Escravo enquanto na camada MapReduce O Job Tracker é componente principal enquanto o rastreador de tarefas é componente escravo. Abaixo está o diagrama da estrutura do Apache Hadoop.
Por que o Apache Hadoop é importante?
- Capacidade de armazenar e processar grandes quantidades de qualquer tipo de dados, rapidamente
- Poder de computação: o modelo de computação distribuída do Hadoop processa big data rapidamente. Quanto mais nós de computação você usar, mais poder de processamento você terá.
- Tolerância a falhas: O processamento de dados e aplicativos está protegido contra falhas de hardware. Se um nó ficar inoperante, os trabalhos serão automaticamente redirecionados para outros nós para garantir que a computação distribuída não falhe. Várias cópias de todos os dados são armazenadas automaticamente.
- Flexibilidade: você pode armazenar quantos dados quiser e decidir como usá-los posteriormente. Isso inclui dados não estruturados, como texto, imagens e vídeos.
- Baixo custo: a estrutura de código aberto é gratuita e usa hardware comum para armazenar grandes quantidades de dados.
- Escalabilidade: você pode expandir seu sistema facilmente para lidar com mais dados simplesmente adicionando nós. É necessária pouca administração
Comparação cara a cara entre Big Data x Apache Hadoop (Infográficos)
Abaixo está a comparação top 4 entre Big Data vs Apache Hadoop
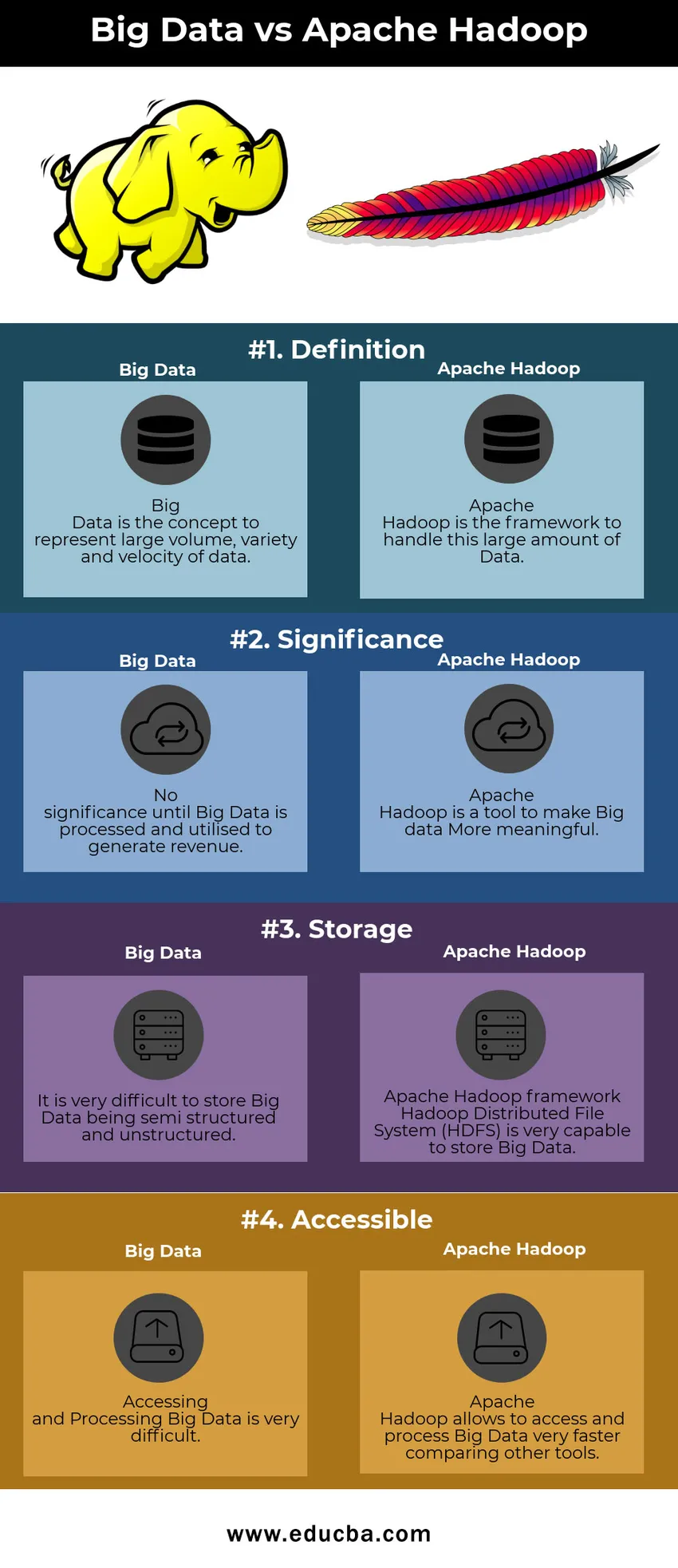
Tabela de comparação Big Data x Apache Hadoop
Estou discutindo os principais artefatos e distinguindo entre Big Data e Apache Hadoop
| Big Data | Apache Hadoop | |
| Definição | Big Data é o conceito para representar grande volume, variedade e velocidade de dados | O Apache Hadoop é a estrutura para lidar com essa grande quantidade de dados |
| Significado | Sem importância até que o Big Data seja processado e utilizado para gerar receita | O Apache Hadoop é uma ferramenta para tornar o Big Data mais significativo |
| Armazenamento | É muito difícil armazenar o Big Data semiestruturado e não estruturado | Estrutura do Apache Hadoop O HDFS (Sistema de Arquivos Distribuídos) do Hadoop é muito capaz de armazenar Big Data |
| Acessível | Acessar e processar Big Data é muito difícil | O Apache Hadoop permite acessar e processar Big Data muito mais rápido, comparando outras ferramentas |
Conclusão - Big Data vs Apache Hadoop
Você não pode comparar o Big Data e o Apache Hadoop. Isso ocorre porque o Big Data é um problema, enquanto o Apache Hadoop é a Solução. Como a quantidade de dados está aumentando exponencialmente em todos os setores, é muito difícil armazenar e processar dados de um único sistema. Portanto, para processar essa grande quantidade de dados, precisamos de processamento e armazenamento distribuídos de dados. Portanto, o Apache Hadoop oferece a solução de armazenamento e processamento de uma quantidade muito grande de dados. Por fim, concluirei que o Big Data é uma grande quantidade de dados complexos, enquanto o Apache Hadoop é um mecanismo para armazenar e processar o Big Data de maneira muito eficiente e sem problemas.
Artigo recomendado
Este foi um guia para Big Data vs Apache Hadoop, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. este artigo consiste em todas as diferenças úteis entre Big Data e Apache Hadoop. Você também pode consultar os seguintes artigos para saber mais -
- Big Data vs Data Science - Como são diferentes?
- As 5 principais tendências de big data que as empresas terão que dominar
- Hadoop vs Apache Spark - coisas interessantes que você precisa saber
- Apache Hadoop vs Apache Spark | As 10 melhores comparações que você deve saber!