

O que é Big Data e Hadoop?
Os dados estão crescendo exponencialmente todos os dias e, com esses dados crescentes, surge a necessidade de utilizá-los. Como nos dias anteriores, tínhamos unidades de disquete para armazenar dados e a transferência de dados também era lenta, mas hoje em dia elas são insuficientes e o armazenamento na nuvem é usado, pois temos terabytes de dados. No mundo de hoje, as mídias sociais contribuem com o maior crescimento de dados. Consiste no comportamento, na mentalidade e em vários outros aspectos das pessoas. Diz-se que, a cada minuto, 300 horas de vídeo são carregadas no YouTube, mais de 20 milhões de fotos são carregadas no Facebook e muitas outras. Além disso, não existe uma estrutura adequada para o upload dos dados, o que é o maior desafio para o processamento desses dados.
Como dados enormes estão sendo gerados em alta velocidade, os sistemas RDBMS tradicionais não foram capazes de lidar com esse crescimento acelerado. Além disso, eles também não são capazes de lidar com dados não estruturados. Tornou-se muito difícil lidar com uma quantidade tão grande de dados heterogêneos crescendo rapidamente e processá-los com alta velocidade de processamento. Assim, surgiu a necessidade de um sistema capaz de lidar com grandes conjuntos de dados com eficiência. Portanto, para resolver o cenário, o Hadoop passou a existir. O HDFS é o componente do Hadoop que solucionou o problema de armazenamento do grande conjunto de dados usando o armazenamento distribuído, enquanto o YARN é o componente que solucionou o problema de processamento, reduzindo drasticamente o tempo de processamento.
O Hadoop é uma estrutura de software de código aberto para armazenar e processar grandes conjuntos de dados usando um grande cluster distribuído de hardware comum. Foi desenvolvido por Doug Cutting e Michael J. Cafarella e licenciado sob Apache. Foi escrito em Java e foi desenvolvido com base no artigo escrito pelo Google no sistema MapReduce e aplica conceitos de programação funcional. É confiável, econômico, flexível e escalável.
Os principais componentes do Hadoop
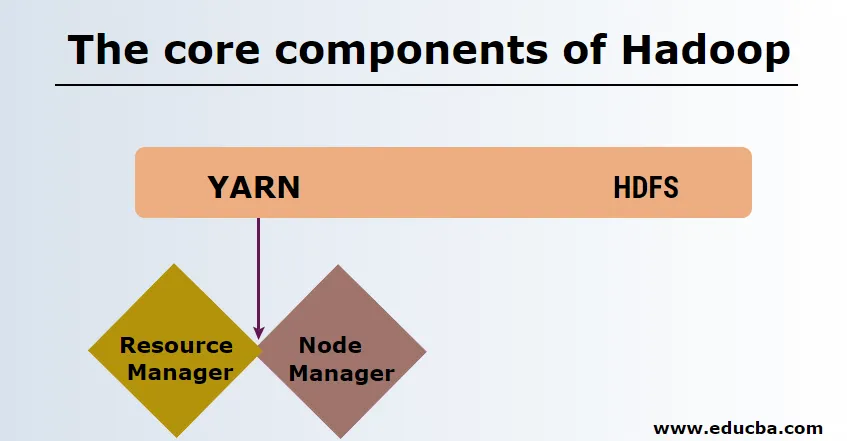
Os principais componentes do Hadoop são os seguintes
-
HDFS
O HDFS ou o Hadoop Distributed File System possui Namenode e nó de dados. Namenode é o nó principal que está executando o daemon principal e gerencia os nós de dados e mantém o controle de todas as operações. Datanodes são os escravos onde os dados são realmente armazenados.
-
FIO
YARN consiste em dois componentes principais:
1. ResourceManager: É executado no nó principal e gerencia todos os recursos e agenda todos os aplicativos. Possui Scheduler & ApplicationManager.
2. NodeManager: É executado em cada nó escravo e é responsável pelo gerenciamento de contêineres e pelo monitoramento da utilização dos recursos.
Vários componentes do Hadoop
Existem vários componentes do Hadoop, como o porco, a colméia, o sqoop, a calha, o mahout, oozie, o zookeeper, o HBase etc.
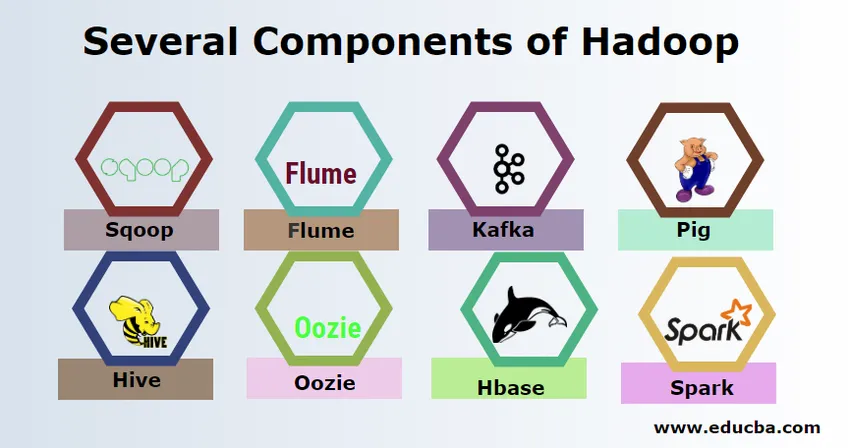
- Sqoop - É usado para importar e exportar dados do RDBMS para o Hadoop e vice-versa.
- Flume - É usado para extrair dados em tempo real para o Hadoop.
- Kafka - É um sistema de mensagens usado para rotear dados em tempo real para o Hadoop.
- Porco - É usado como uma linguagem de script para processamento de dados.
- Hive - É uma estrutura de data warehousing criada no HDFS, para que usuários familiarizados com o SQL possam executar consultas para obter os dados. Essas consultas são chamadas de HiveQL.
- Oozie - É usado para agendar o fluxo de trabalho de tarefas para execução em eventos ou horários especificados.
- Hbase - É o banco de dados sem SQL fornecido como parte do Apache Hadoop.
- Spark - É usado para executar o processamento na memória, que é muito mais rápido do que o mapa reduzido do Hadoop.
Provedores do Hadoop
Existem muitas empresas que oferecem distribuições do Hadoop. Abaixo estão os melhores fornecedores para o Hadoop:
- Cloudera
- Hortonworks
- MapR
Existem alguns pré-requisitos para aprender o Hadoop. É necessária experiência prévia em Java e linguagem de script. Embora o Hadoop já tenha suas próprias linguagens de programação de alto nível, como pig e hive, que gera o código de back-end para processamento adicional, ainda é possível criar o próprio programa de redução de mapa de qualquer linguagem de programação como Ruby, Python, Perl e até C.
Bigdata e Hadoop estão em alta demanda no mercado atual. Isso vai aumentar mais nos próximos dias. Muitas organizações já se mudaram para o Hadoop e as que não o fizerem mudarão em breve. Existe um relatório atual afirmando que as principais empresas começaram a investir em análise de big data. A previsão de marketing de big data está sempre na tendência ascendente e não é de modo algum um estado de curta duração. Além de tudo isso, os trabalhos no Hadoop e o big data sempre oferecem altos salários em comparação com outras tecnologias.
Principais empresas de Big Data e Hadoop
Abaixo estão algumas das principais empresas que empregam o maior número de recursos do Hadoop.
- Yahoo
- Amazonas
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Existem muitas empresas que usam aplicativos de big data. Esses são:
-
Nokia
Ele usa componentes Cloudera e Hadoop como HDFS, HBase, Sqoop, Scribe para o aplicativo. Ele usou os dados do usuário de forma eficaz para entender e melhorar a experiência do usuário. Ele usa processamento de dados e análises complexas para construir o mapa com tráfego preditivo e modelos de elevação em camadas.
-
SAS
Ele colaborou com o Hadoop para ajudar os cientistas de dados a obter uma melhor visão, fornecendo um ambiente que oferece experiência visual e interativa, ajudando assim a explorar novas tendências. Os programas analíticos extraem informações significativas dos dados e a tecnologia na memória ajuda a um acesso mais rápido aos dados.
Também existem muitas outras empresas usando plataformas de big data para várias análises. Trata-se da análise de dados de voos da caixa preta na indústria da aviação, a análise diferente em participação no mercado, etc.
Vantagens do Haddop
Abaixo estão algumas das vantagens do Hadoop
- Escalável - Ao contrário do RDBMS tradicional, é uma plataforma altamente escalável, pois pode armazenar grandes conjuntos de dados em clusters distribuídos em hardware comum operando em paralelo.
- Custo-benefício - O custo era muito alto para o RDBMS armazenar dados que foram aliviados no Hadoop.
- Rápido e flexível - Oferece dados para serem acessados rapidamente através de seu sistema de arquivos distribuído. Também oferece informações de negócios a partir de dados semiestruturados e não estruturados.
- Tolerante a falhas - sempre que qualquer dado é enviado para um nó, os mesmos dados são replicados para outros nós que podem ser acessados em caso de falha do primeiro nó.
Conclusão - o que é Big Data e Hadoop
Os dados estão crescendo continuamente e, portanto, sempre haverá necessidade de big data e do Hadoop para dar sentido a esses dados. Por esse motivo, profissionais com habilidades no Hadoop sempre encontrarão amplas oportunidades nos próximos dias e podem ser um ativo vital para uma organização que impulsiona os negócios e sua carreira.
Artigos recomendados
Este foi um guia sobre o que é Big Data e Hadoop. Aqui discutimos os conceitos básicos e os componentes do Big Data e do Hadoop. Você também pode consultar o seguinte artigo para saber mais -
- Exemplos de análise de big data
- Usos do Hadoop
- Guia de Visualização de Dados
- O que é análise de Big Data?