

Introdução ao Apache Flume
O Apache Flume é o Data Ingestion Framework, que grava dados baseados em eventos no Hadoop Distributed File System. É um fato conhecido que o Hadoop processa Big Data, surge uma pergunta sobre como os dados gerados a partir de diferentes servidores da Web são transmitidos ao Hadoop File System? A resposta é Apache Flume. O Flume foi projetado para ingestão de dados de alto volume no Hadoop de dados baseados em eventos.
Considere um cenário em que o número de servidores web gera arquivos de log e esses arquivos de log precisam transmitir ao sistema de arquivos Hadoop. O Flume coleta esses arquivos como eventos e os ingere no Hadoop. Embora o Flume seja usado para transmitir ao Hadoop, não há uma regra rígida de que o destino deve ser o Hadoop. O Flume é capaz de gravar em outros Frameworks como Hbase ou Solr.
Arquitetura Flume
Em geral, a arquitetura do Apache Flume é composta pelos seguintes componentes:
- Fonte do Flume
- Flume Channel
- Flume Sink
- Flume Agent
- Evento Flume
Vamos dar uma breve olhada em cada componente do Flume
1. Fonte de Flume
Uma fonte Flume está presente em geradores de dados como o Face Book ou o Twitter. A fonte coleta dados do gerador e os transfere para o Flume Channel na forma de Eventos do Flume. O Flume suporta vários tipos de fontes, como o Avro Flume Source - se conecta na porta Avro e recebe eventos do cliente externo Avro, o Thrift Flume Source - se conecta na porta Thrift e recebe eventos de fluxos externos do cliente Thrift, Spool Directory Source e Kafka Flume Source.
2. Canal de Flume
Um armazenamento intermediário que armazena em buffer os eventos enviados pelo Flume Source até que sejam consumidos pelo Sink é chamado Flume Channel. O canal atua como uma ponte intermediária entre o Source e o Sink. Os canais de canal são de natureza transacional.
O Flume fornece suporte para o canal File e o canal Memory. O canal do arquivo é de natureza durável, o que significa que, uma vez que os dados sejam gravados no canal, eles não serão perdidos, embora se o agente reiniciar. Na memória, os eventos do canal são armazenados na memória, por isso não é durável, mas é muito rápido por natureza.
3. Pia de Flume
Um Flume Sink está presente em repositórios de dados como HDFS, HBase. O Flume sink consome eventos do Channel e os armazena em lojas de destino como HDFS. Não existe uma regra que permita que o coletor entregue eventos ao Store. Em vez disso, podemos configurá-lo de forma que um coletor possa entregar eventos para outro agente. O Flume suporta vários coletores, como HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
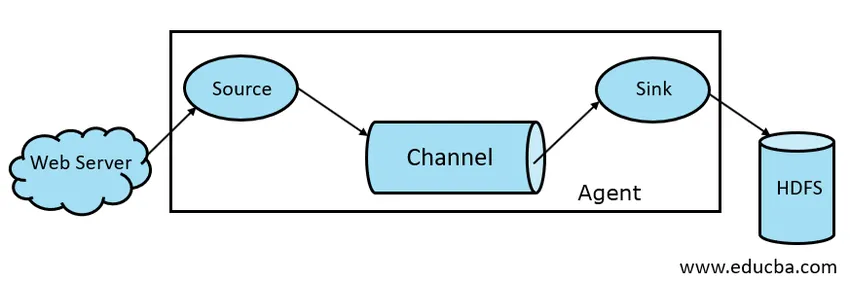
Fig 1.1 Arquitetura básica do Flume
4. Agente Flume
Um agente do Flume é um processo Java de execução longa executado na combinação Source - Channel - Sink. O Flume pode ter mais de um agente. Podemos considerar o Flume como uma coleção de agentes conectados do Flume que são distribuídos na natureza.
5. Evento Flume
Um evento é a unidade de dados transportada no Flume . A representação geral do objeto de dados no Flume é chamada de evento. O evento é composto de uma carga útil de uma matriz de bytes com cabeçalhos opcionais.
Trabalho de Flume
Um agente do Flume é um processo java que consiste no Source - Channel - Sink em sua forma mais simples. A fonte coleta dados do gerador de dados na forma de Eventos e os entrega ao Canal. Uma fonte pode ser entregue em vários canais, conforme o requisito. Fan-out é o processo em que uma única fonte grava em vários canais para que eles possam ser entregues em vários coletores.
Um evento é a unidade básica de dados sendo transmitida no Flume. O canal armazena em buffer os dados até que sejam ingeridos pelo Sink. O Sink coleta os dados do Channel e os entrega ao armazenamento de dados centralizado, como o HDFS ou o Sink pode encaminhar esses eventos para outro agente do Flume, conforme o requisito.
O Flume suporta Transações. Para obter confiabilidade, o Flume usa transações separadas da origem para o canal e do canal para o coletor. Se os eventos não forem entregues, a transação será revertida e posteriormente devolvida.
Para entender o funcionamento do Flume, vamos dar um exemplo da configuração do Flume, em que source é diretório de spool e sink é Hdfs. Neste exemplo, o agente do Flume está na forma mais simples, isto é, topologia de fonte única - canal - coletor, configurada usando um arquivo de propriedades java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
No exemplo de configuração acima, agent é a base com a qual definimos outras propriedades. source1 e sink1 e channel1 são os nomes de source, sink e channel respectivamente e seus tipos e locais também são mencionados em conformidade.
Vantagens do Apache Flume
- O Flume é escalável, confiável e tolerante a falhas por natureza. Essas propriedades são discutidas em detalhes abaixo
- Escalonável - O Flume é escalável horizontalmente, ou seja, podemos adicionar novos nós conforme nossos requisitos
- Confiável - O Apache Flume tem suporte para transações e garante que nenhum dado seja perdido no processo de transmissão de dados. Possui transações diferentes de origem para canal e de canal para origem.
- O Flume é personalizável e fornece suporte para várias fontes e sumidouros como Kafka, Avro, diretório de spool, Thrift etc.
- No Flume, a fonte única pode transmitir dados para vários canais e esses canais, por sua vez, transmitem os dados para vários coletores, assim, a fonte única pode transmitir dados para vários coletores. Esse mecanismo é chamado Fan out. O Flume também suporta o Fan out.
- O Flume fornece um fluxo constante de transmissão de dados, ou seja, se a velocidade de leitura de dados aumenta e a velocidade de gravação de dados também aumenta.
- Embora o Flume geralmente grave dados no armazenamento centralizado como HDFS ou Hbase, podemos configurá-lo de acordo com nossos requisitos, para que o Sink possa gravar dados em outro agente. Isso mostra flexibilidade do Flume
- O Apache Flume é de código aberto por natureza.
Conclusão
Neste artigo do Flume, os componentes do Flume e o trabalho do Flume são discutidos em detalhes. O Flume é uma plataforma flexível, confiável e escalável para transmitir dados para um armazenamento centralizado como o HDFS. Sua capacidade de integrar-se a vários aplicativos como Kafka, Hdfs, Thrift torna sua opção viável para ingestão de dados.
Artigos recomendados
Este foi um guia para o Apache Flume. Aqui discutimos a arquitetura, o funcionamento e as vantagens do Apache Flume. Você também pode consultar os seguintes artigos para saber mais -
- O que é o Apache Flink?
- Diferença entre Apache Kafka e Flume
- Arquitetura de Big Data
- Ferramentas Hadoop
- Aprenda os diferentes eventos JavaScript