

Diferença entre MapReduce e Spark
O Map Reduce é uma estrutura de código aberto para gravar dados no HDFS e processar dados estruturados e não estruturados presentes no HDFS. O Map Reduce está limitado ao processamento em lote e, em outro Spark, é capaz de executar qualquer tipo de processamento. O SPARK é um mecanismo de processamento independente para processamento em tempo real que pode ser instalado em qualquer sistema de arquivos distribuídos como o Hadoop. O SPARK fornece um desempenho 10 vezes mais rápido que o Map Reduce no disco e 100 vezes mais rápido que o Map Reduce em uma rede na memória.
Necessidade de SPARK
- Análise iterativa: a redução de mapa não é tão eficiente quanto uma SPARK para resolver problemas que exigem análise iterativa, pois é necessário ir ao disco para cada iteração.
- Análise interativa: a redução de mapa é frequentemente usada para executar consultas ad-hoc para as quais ele precisa acessar a memória em disco, que novamente não é tão eficiente quanto o SPARK, porque o último se refere à memória mais rápida.
- Não é adequado para OLTP: como funciona na estrutura orientada a lotes, não é adequado para um grande número de transações curtas.
- Não é adequado para o gráfico: a biblioteca do Apache Graph processa o gráfico que adiciona mais complexidade ao Map Reduce.
- Não é adequado para operações triviais: para operações como um filtro e junções, talvez seja necessário reescrever os trabalhos, o que se torna mais complexo devido ao padrão de valor-chave.
Comparação cara a cara entre MapReduce vs Spark (Infographics)
Abaixo está a diferença dos 15 principais entre o MapReduce e o Spark

Principais diferenças entre o MapReduce e o Spark
Abaixo estão as listas de pontos, descrevem as principais diferenças entre o MapReduce e o Spark:
- O Spark é adequado para tempo real enquanto processa usando a memória, enquanto o MapReduce é limitado ao processamento em lote.
- O Spark tem RDD (Conjunto de dados distribuídos resilientes), oferecendo-nos operadores de alto nível, mas, na redução de mapa, precisamos codificar cada operação, tornando-a comparativamente difícil.
- O Spark pode processar gráficos e suporta a ferramenta de aprendizado de máquina.
- Abaixo está a diferença entre o ecossistema MapReduce e Spark.
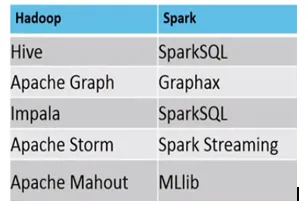
Exemplo, onde MapReduce vs Spark são adequados, são os seguintes
Spark: detecção de fraude no cartão de crédito
MapReduce: elaboração de relatórios regulares que requerem tomada de decisão.
Tabela de comparação MapReduce vs Spark
| Base de comparação | MapReduce | Faísca |
| Estrutura | Uma estrutura de código aberto para gravar dados no HDFS e processar dados estruturados e não estruturados presentes no HDFS. | Uma estrutura de código aberto para processamento de dados mais rápido e de uso geral |
| Rapidez | Map-Reduce processa os dados (leituras e gravação) do disco para que a infiltração seja lenta em comparação com o Spark. | O Spark é pelo menos 10 vezes mais rápido no disco e 100X mais rápido na memória do que o Map Reduce. |
| Dificuldade | Precisamos codificar / manipular cada processo. | Com a disponibilidade do RDD (Conjunto de dados distribuídos resilientes), é fácil programar. |
| Tempo real | Não é adequado para transações OLTP apenas no modo Lote | Ele pode lidar com o processamento em tempo real. Usando o SPARK Streaming. |
| Latência | Estrutura de computação de latência de alto nível | Estrutura de computação de latência de baixo nível. |
| Tolerância ao erro | Os daemons mestres verificam o batimento cardíaco dos daemons escravos e, caso os daemons escravos falhem, os daemons mestre reprogramam toda a operação pendente e em andamento para outro escravo. | Os RDDs fornecem tolerância a falhas para SPARK. Eles se referem ao conjunto de dados presente no armazenamento externo, como (HDFS, HBase) e operam em paralelo. |
| Agendador | No Map Reduce, usamos um agendador externo como Oozie. | À medida que o SPARK trabalha com a computação na memória, ele atua como seu próprio agendador. |
| Custo | Reduzir mapa é comparativamente mais barato quando comparado ao SPARK. | Como ele funciona na memória, requer muita RAM, o que o torna relativamente mais caro. |
| Plataforma desenvolvida em | O Map Reduce foi desenvolvido usando Java. | O SPARK foi desenvolvido usando o Scala. |
| Idioma Suportado | O Map Reduce suporta basicamente C, C ++, Ruby, Groovy, Perl, Python. | O Spark suporta Scala, Java, Python, R, SQL. |
| Suporte SQL | O Map Reduce executa consultas usando o Hive Query Language. | O Spark possui sua própria linguagem de consulta, conhecida como Spark SQL. |
| Escalabilidade | No Map Reduce, podemos adicionar até n número de nós. O maior Hadoop Cluster possui 14000 nós. | No Spark também podemos adicionar n número de nós. O maior cluster Spark possui 8000 nós. |
| Machine Learning | O Map Reduce suporta a ferramenta Apache Mahout para aprendizado de máquina. | O Spark suporta a ferramenta MLlib para aprendizado de máquina. |
| Armazenamento em cache | A redução de mapa não pode armazenar em cache os dados da memória, portanto, não é tão rápido em comparação com o Spark. | O Spark armazena em cache os dados na memória para iterações adicionais, portanto é muito rápido em comparação com o Map Reduce. |
| Segurança | O Map Reduce suporta mais projetos e recursos de segurança em comparação com o Spark | A segurança do Spark ainda não está madura como a do Map Reduce |
Conclusão - MapReduce vs Spark
De acordo com a diferença acima entre o MapReduce e o Spark, é bastante claro que o SPARK é um mecanismo de computação muito mais avançado em comparação com o Map Reduce. O Spark é compatível com qualquer tipo de formato de arquivo e também muito mais rápido que o Map Reduce. Além disso, a centelha também possui recursos de processamento de gráficos e aprendizado de máquina.
Por um lado, o Map Reduce é limitado ao processamento em lote e, por outro, o Spark é capaz de executar qualquer tipo de processamento (lote, interativo, iterativo, streaming, gráfico). Devido à grande compatibilidade, o Spark é o favorito do Data Scientist e, portanto, substitui o Map Reduce e cresce rapidamente. Mas ainda precisamos armazenar os dados no HDFS e, às vezes, também precisamos do HBase. Portanto, precisamos executar o Spark e o Hadoop para obter o melhor.
Artigos recomendados:
Este foi um guia para o MapReduce vs Spark, seu significado, comparação direta, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- 7 coisas importantes sobre o Apache Spark (Guia)
- Hadoop vs Apache Spark - coisas interessantes que você precisa saber
- Apache Hadoop vs Apache Spark | As 10 melhores comparações que você deve saber!
- Como o MapReduce funciona?
- Confluência da tecnologia e análise de negócios