

Diferenças entre Sqoop e Flume
Sqoop é um produto do software Apache. O Sqoop extrai informações úteis do Hadoop e depois passa para os repositórios de dados externos. Com a ajuda do Sqoop, podemos importar dados de um RDBMS ou mainframe para o HDFS. O Flume também é do software Apache. Ele coleta e move os dados recursivos que são gerados. O Apache Flume não se restringe apenas à agregação de dados de log, mas as fontes de dados são personalizáveis e, portanto, o Flume pode ser usado para transportar grandes quantidades de dados. A melhor maneira de coletar, agregar e mover grandes quantidades de dados entre o Hadoop Distributed File System e o RDBMS é através do uso de ferramentas como Sqoop ou Flume.
Vamos discutir essas duas ferramentas comumente usadas para o objetivo acima mencionado.
O que é o Sqoop
Para usar o Sqoop, um usuário precisa especificar a ferramenta que o usuário deseja usar e os argumentos que controlam a ferramenta específica. Você também pode exportar os dados de volta para um RDBMS usando o Sqoop. A funcionalidade de exportação do Sqoop é usada para extrair informações úteis do Hadoop e exportá-las para os armazenamentos de dados estruturados externos. Ele funciona com diferentes bancos de dados como Teradata, MySQL, Oracle, HSQLDB.
- Arquitetura Sqoop: -
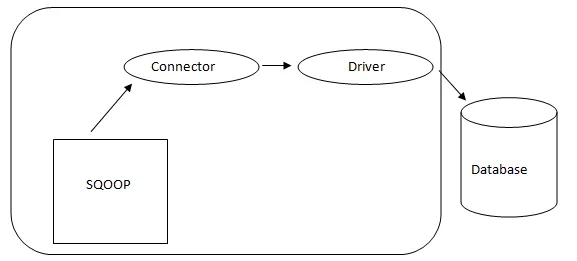
Arquitetura do Sqoop
O conector em um Sqoop é um plug-in para uma fonte de banco de dados específica, portanto, é fundamental que seja uma parte do estabelecimento do Sqoop. Apesar de os drivers serem partes específicas do banco de dados e distribuídos por vários fornecedores de banco de dados, o próprio Sqoop vem com diferentes tipos de conectores utilizados para o sistema predominante de banco de dados e armazenamento de informações. Assim, o Sqoop também é enviado com uma variedade de conectores. O Sqoop fornece um componente conectável para uma rede ideal e um sistema externo. A API do Sqoop fornece uma estrutura útil para a montagem de novos conectores e, portanto, qualquer conector de banco de dados pode ser descartado na instalação do Sqoop para fornecer conectividade a diferentes sistemas de dados.
O que é o Flume
O Apache Flume não se restringe apenas à agregação de dados de log, mas as fontes de dados são personalizáveis e, portanto, o Flume pode ser usado para transportar grandes quantidades de dados, incluindo, entre outros, mensagens de email, dados gerados pelas mídias sociais, dados de tráfego de rede e praticamente qualquer possível fonte de dados.
Arquitetura do Flume: - A arquitetura do Flume é baseada em conceitos de vários núcleos:
- Flume Event - é representada como a unidade de dados que flui, que possui uma carga útil de bytes e um conjunto de strings com cabeçalhos de strings opcionais. Flume considera um evento apenas um blob genérico de bytes.
- Flume Agent - É um processo da JVM que hospeda os componentes, como canais, coletor e fontes. Tem potencial para receber, armazenar e encaminhar os eventos de uma fonte externa para o próximo nível.
- Flume Flow - é o momento em que o evento está sendo gerado.
- Cliente Flume - refere-se à interface em que o cliente opera no ponto de origem do evento e a entrega ao agente Flume.
- Origem - Uma fonte é aquela que consome eventos com um formato específico e a entrega por meio de um mecanismo específico.
- Canal - é uma loja passiva onde os eventos são realizados até que a pia o remova para posterior transporte.
- Pia - remove o evento de um canal e o coloca em um repositório externo como o HDFS. Atualmente, ele suporta a criação de arquivos de texto e sequência e suporta a compactação nos dois tipos de arquivo.
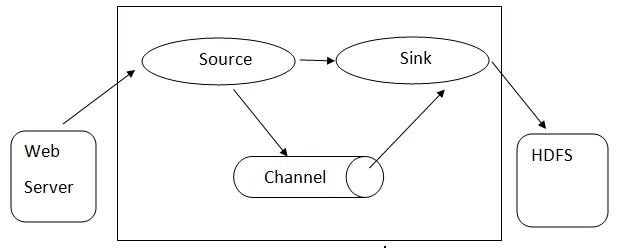
Arquitetura do Flume
Comparação cara a cara entre Sqoop vs Flume (Infográficos)
Abaixo está a top 7 comparação entre Sqoop e Flume

Principais diferenças entre Sqoop e Flume
Agora sabemos que existem muitas diferenças entre Sqoop e Flume. Aqui estão as diferenças mais importantes entre elas, abaixo:
1. O Sqoop foi projetado para trocar informações em massa entre o Hadoop e o Banco de Dados Relacional.
Visto que o Flume é usado para coletar dados de diferentes fontes que estão gerando dados sobre um caso de uso específico e transferindo essa grande quantidade de dados de recursos distribuídos para um único repositório centralizado.
2. O Sqoop também inclui um conjunto de comandos que permitem inspecionar o banco de dados com o qual você está trabalhando. Assim, podemos considerar o Sqoop como uma coleção de ferramentas relacionadas.
Ao coletar a data, o Flume dimensiona os dados horizontalmente e vários agentes do Flume podem ser acionados para coletar a data e agregá-los. Posteriormente, os logs de dados são movidos para um armazenamento de dados centralizado, isto é, HDFS (Hadoop Distributed File System).
3. O fator principal para o uso do Flume é que os dados devem ser gerados de maneira contínua e em fluxo contínuo. Da mesma forma, o Sqoop é o mais adequado para situações em que seus dados residem em sistemas de banco de dados como MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Tabela de comparação)
| Base para Comparação | SQOOP | FLUME |
|
Natureza básica | O Sqoop funciona bem com qualquer RDBMS que possua JDBC (Java Database Connectivity) como Oracle, MySQL, Teradata, etc. | O Flume funciona bem para a fonte de dados Streaming, que está gerando continuamente, como logs, JMS, diretório, relatórios de falhas, etc. |
| Fluxo de dados | Sqoop usado especificamente para transferência de dados paralela. Por esse motivo, a saída pode estar em vários arquivos | O Flume é usado para coletar e agregar dados devido à sua natureza distribuída. |
| Eventos Impulsionados | Sqoop não é conduzido por eventos. | O Flume é completamente orientado a eventos. |
| Arquitetura | O Sqoop segue a arquitetura baseada em conectores, o que significa conectores, sabe como se conectar a uma fonte de dados diferente. | O Flume segue a arquitetura baseada em agente, onde o código escrito nele é conhecido como um agente responsável pela busca de dados. |
| Onde usar | Usado principalmente para copiar dados mais rapidamente e depois usá-los para gerar resultados analíticos. | Geralmente usado para extrair dados quando as empresas desejam analisar padrões, causas raiz ou análise de sentimentos usando logs e mídias sociais. |
| atuação | Reduz cargas excessivas de armazenamento e processamento, transferindo-as para outros sistemas e apresenta desempenho rápido. | O Flume é tolerante a falhas, robusto e possui um mecanismo confiável de confiabilidade para failover e recuperação. |
| Histórico de Lançamentos | A primeira versão do Apache Sqoop foi lançada em março de 2012. A versão estável atual é 1.4.7 | A primeira versão estável 1.2.0 do Apache Flume foi lançada em junho de 2012. A versão estável atual é o Apache Flume Versão 1.8.0. |
Conclusão - Sqoop vs Flume
Como você aprendeu acima, o Sqoop e o Flume, são principalmente duas ferramentas usadas para ingestão de dados: o mundo do Big Data. Se você precisar inserir dados de log textuais no Hadoop / HDFS, o Flume é a escolha certa para fazer isso. Se seus dados não forem gerados regularmente, o Flume ainda funcionará, mas será um exagero para essa situação. Da mesma forma, o Sqoop não é o melhor ajuste para manipulação de dados orientada a eventos.
Artigos recomendados
Este foi um guia para as diferenças entre Sqoop e Flume, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. este artigo consiste em todas as diferenças úteis entre o Sqoop e o Flume. Você também pode consultar os seguintes artigos para saber mais
- Hadoop vs Teradata - diferenças úteis a aprender
- 5 diferença mais importante entre Apache Kafka e Flume
- Big Data vs Apache Hadoop - As 4 principais comparações que você deve aprender
- 5 diferença mais importante entre Apache Kafka e Flume
- Mineração de texto importante vs processamento de idiomas naturais - As 5 principais comparações