
Introdução à eliminação reversa
À medida que o homem e a máquina avançam em direção à evolução digital, diversas máquinas técnicas estão respondendo não apenas a serem treinadas, mas também treinadas de maneira inteligente para obter um melhor reconhecimento dos objetos do mundo real. Essa técnica, introduzida anteriormente, denominada "Eliminação reversa", pretendia favorecer recursos indispensáveis enquanto erradicava recursos nugatórios para proporcionar melhor otimização em uma máquina. Toda a proficiência no reconhecimento de objetos pelo Machine é proporcional às características que ele considera.
Os recursos que não têm referência na saída prevista devem ser descarregados da máquina e são concluídos com a eliminação para trás. A boa precisão e complexidade de tempo do reconhecimento de qualquer objeto de palavra real pela Machine dependem de seu aprendizado. Portanto, eliminar para trás desempenha seu papel rígido na seleção de recursos. Ele calcula a taxa de dependência de recursos para a variável dependente e encontra a importância de pertencer ao modelo. Para credenciar isso, ele verifica a taxa calculada com um nível de significância padrão (por exemplo, 0, 06) e toma uma decisão para a seleção de recursos.
Por que adotamos a eliminação reversa ?
Características não essenciais e redundantes impulsionam a complexidade da lógica da máquina. Ele consome tempo e recursos do modelo desnecessariamente. Portanto, a técnica mencionada desempenha um papel competente para forjar o modelo de maneira simples. O algoritmo cultiva a melhor versão do modelo, otimizando seu desempenho e truncando seus recursos designados dispensáveis.
Reduz as características menos notáveis do modelo que causa ruído na decisão da linha de regressão. Características de objeto irrelevantes podem gerar erros de classificação e previsão. Características irrelevantes de uma entidade podem constituir um desequilíbrio no modelo em relação a outras características significativas de outros objetos. A eliminação para trás promove o melhor ajuste do modelo. Portanto, recomenda-se a eliminação para trás em um modelo.
Como aplicar a eliminação para trás?
A eliminação para trás começa com todas as variáveis de recurso, testando-a com a variável dependente sob um critério de ajuste de modelo selecionado. Começa a erradicar as variáveis que deterioram a linha de regressão adequada. Repita essa exclusão até que o modelo atinja um bom ajuste. Abaixo estão as etapas para praticar a eliminação para trás:
Etapa 1: escolha o nível de significância apropriado para residir no modelo da máquina. (Tome S = 0, 06)
Etapa 2: Alimente todas as variáveis independentes disponíveis ao modelo em relação à variável dependente e calcule a inclinação e intercepte para desenhar uma linha de regressão ou linha de ajuste.
Etapa 3: Percorra todas as variáveis independentes que possuem o valor mais alto (Take I), uma por uma e prossiga com a seguinte notificação: -
a) Se I> S, execute o quarto passo.
b) Caso contrário, o modelo é perfeito.
Etapa 4: remova a variável escolhida e aumente o percurso.
Etapa 5: forje novamente o modelo novamente e calcule a inclinação e a interceptação da linha de ajuste novamente com variáveis residuais.
As etapas acima mencionadas são resumidas na rejeição das características cuja taxa de significância está acima do valor de significância selecionado (0, 06) para evitar a superclassificação e a superutilização de recursos observados como de alta complexidade.
Méritos e Deméritos da Eliminação Reversa
Aqui estão alguns méritos e deméritos da eliminação atrasada, dados abaixo em detalhes:
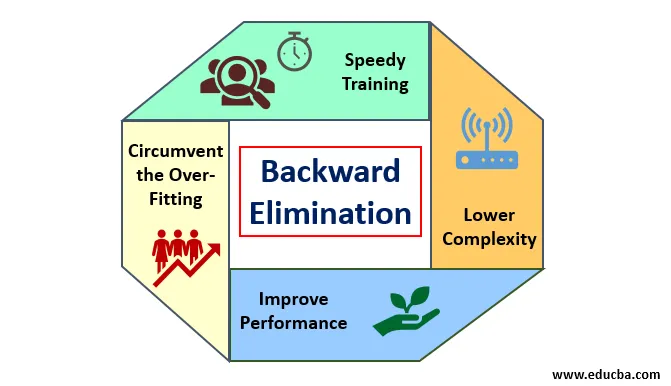
1. Méritos
Os méritos da eliminação para trás são os seguintes:
- Treinamento rápido: a máquina é treinada com um conjunto de recursos disponíveis do padrão, que são executados em um período muito curto de tempo, se os recursos não essenciais forem removidos do modelo. O treinamento rápido do conjunto de dados só aparece quando o modelo lida com recursos significativos e exclui todas as variáveis de ruído. Desenha uma complexidade simples para o treinamento. Mas o modelo não deve sofrer ajustes inadequados, o que ocorre devido à falta de recursos ou amostras inadequadas. O recurso de amostra deve ser abundante em um modelo para a melhor classificação. O tempo necessário para treinar o modelo deve ser menor, mantendo a precisão da classificação e deixado sem variável de sub-previsão.
- Menor complexidade: a complexidade do modelo será alta se o modelo contemplar a extensão de recursos, incluindo ruído e recursos não relacionados. O modelo consome muito espaço e tempo para processar essa extensão de recursos. Isso pode aumentar a taxa de precisão do reconhecimento de padrões, mas a taxa também pode conter ruído. Para se livrar de uma complexidade tão alta do modelo, o algoritmo de eliminação para trás desempenha um papel necessário, reduzindo os recursos indesejados do modelo. Simplifica a lógica de processamento do modelo. Apenas algumas características essenciais são suficientes para definir uma boa adequação à precisão razoável.
- Melhorar o desempenho: O desempenho do modelo depende de muitos aspectos. O modelo passa por otimização usando a eliminação para trás. A otimização do modelo é a otimização do conjunto de dados usado para o treinamento do modelo. O desempenho do modelo é diretamente proporcional à sua taxa de otimização, que depende da frequência de dados significativos. O processo de eliminação para trás não se destina a iniciar a alteração de qualquer predicador de baixa frequência. Mas isso só inicia alterações a partir de dados de alta frequência, porque principalmente a complexidade do modelo depende dessa parte.
- Contornar o ajuste excessivo : A situação de ajuste excessivo ocorre quando o modelo obtém muitos conjuntos de dados e é realizada uma classificação ou previsão na qual alguns predicadores obtêm o ruído de outras classes. Nesse ajuste, o modelo deveria fornecer uma precisão inesperadamente alta. Na adaptação excessiva, o modelo pode falhar ao classificar a variável devido à confusão criada na lógica devido a muitas condições. A técnica de eliminação para trás reduz a característica estranha para contornar a situação de excesso de ajuste.
2. Deméritos
Deméritos de eliminação para trás são os seguintes:
- No método de eliminação para trás, não se pode descobrir qual predicador é responsável pela rejeição de outro predicador devido ao seu alcance para a insignificância. Por exemplo, se o predicador X tiver algum significado que seja bom o suficiente para residir em um modelo após a adição do predicador Y. Mas o significado de X fica desatualizado quando outro predicador Z entra no modelo. Portanto, o algoritmo de eliminação para trás não evidencia nenhuma dependência entre dois preditores que ocorre na "Técnica de seleção direta".
- Após descartar qualquer recurso de um modelo por um algoritmo de eliminação para trás, esse recurso não pode ser selecionado novamente. Em suma, a eliminação para trás não possui uma abordagem flexível para adicionar ou remover recursos / preditores.
- As normas para selecionar o valor de significância (0, 06) no modelo são inflexíveis. A eliminação para trás não possui um procedimento flexível para escolher não apenas mas também alterar o valor insignificante conforme necessário, a fim de buscar o melhor ajuste em um conjunto de dados adequado.
Conclusão
A técnica de eliminação Backward foi realizada para melhorar o desempenho do modelo e otimizar sua complexidade. É vividamente usado em várias regressões, onde o modelo lida com o extenso conjunto de dados. É uma abordagem fácil e simples, em comparação com a seleção direta e a validação cruzada, na qual a sobrecarga de otimização encontrada. A técnica de eliminação para trás inicia a eliminação de características de maior valor de significância. Seu objetivo básico é tornar o modelo menos complexo e proibir situações de excesso de ajuste.
Artigos recomendados
Este é um guia para eliminação para trás. Aqui discutimos como aplicar a eliminação reversa junto com os méritos e deméritos. Você também pode consultar os seguintes artigos para saber mais:
- Aprendizado de máquina com hiperparâmetro
- Clustering no Machine Learning
- Máquina Virtual JAVA
- Aprendizado de máquina não supervisionado