

Introdução às técnicas de ciência de dados
No mundo de hoje, onde os dados são o novo ouro, existem diferentes tipos de análise disponíveis para uma empresa fazer. O resultado de um projeto de ciência de dados varia muito com o tipo de dados disponível e, portanto, o impacto também é uma variável. Como há muitos tipos diferentes de análises disponíveis, torna-se imperativo entender o que algumas técnicas de linha de base precisam ser selecionadas. O objetivo essencial das técnicas de ciência de dados não é apenas procurar informações relevantes, mas também detectar elos fracos que tendem a fazer um mau desempenho do modelo.
O que é ciência de dados?
A ciência de dados é um campo que se espalha por várias disciplinas. Ele incorpora métodos científicos, processos, algoritmos e sistemas para reunir conhecimento e trabalhar sobre o mesmo. Este campo inclui uma variedade de gêneros e é uma plataforma comum para a unificação de conceitos de estatística, análise de dados e aprendizado de máquina. Nesse sentido, o conhecimento teórico das estatísticas, juntamente com os dados e as técnicas em tempo real do aprendizado de máquina, trabalham lado a lado para obter resultados frutíferos para os negócios. Usando diferentes técnicas empregadas na ciência de dados, nós, no mundo de hoje, podemos implicar em melhores tomadas de decisão que, de outra forma, poderiam faltar no olho e na mente humanos. Lembre-se de que a máquina nunca esquece! Para maximizar o lucro em um mundo baseado em dados, a magia da Ciência de Dados é uma ferramenta necessária.
Diferentes tipos de técnica de ciência de dados
Nos parágrafos a seguir, abordaremos técnicas comuns de ciência de dados usadas em todos os outros projetos. Embora às vezes a técnica de ciência de dados possa ser específica de um problema de negócios e não se enquadrar nas categorias abaixo, é perfeitamente aceitável denominá-las como tipos diversos. Em um nível alto, dividimos as técnicas em Supervisionado (sabemos o impacto da meta) e Não Supervisionado (Não sabemos sobre a variável da meta que estamos tentando alcançar). No próximo nível, as técnicas podem ser divididas em termos de
- A saída que obteríamos ou qual é a intenção do problema de negócios
- Tipo de dados utilizados.
Vamos primeiro olhar para a segregação com base na intenção.
1. Aprendizagem não supervisionada
- Detecção de anomalia
Nesse tipo de técnica, identificamos qualquer ocorrência inesperada em todo o conjunto de dados. Como o comportamento difere da ocorrência real de um dado, as premissas subjacentes são:
- A ocorrência dessas instâncias é muito pequena em número.
- A diferença de comportamento é significativa.
Os algoritmos de anomalia são explicados, como a Floresta de Isolamento, que fornece uma pontuação para cada registro em um conjunto de dados. Este algoritmo é um modelo baseado em árvore. Usando esse tipo de técnica de detecção e sua popularidade, eles são usados em vários casos comerciais, por exemplo, exibições de páginas da Web, taxa de rotatividade, receita por clique etc. No gráfico abaixo, podemos explicar como é a anomalia.
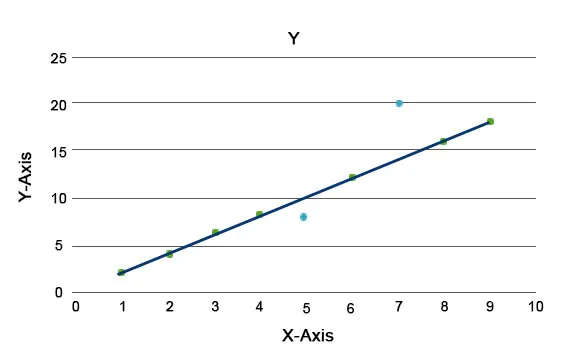
Aqui os em azul representam uma anomalia no conjunto de dados. Eles variam da linha de tendência regular e ocorrem menos.
- Análise de Cluster
Por meio dessa análise, a principal tarefa é segregar todo o conjunto de dados em grupos para que a tendência ou os traços nos pontos de dados de um grupo sejam bastante semelhantes entre si. Na terminologia da ciência de dados, chamamos isso de cluster. Por exemplo, no negócio de varejo, existe um plano para escalonar o negócio e torna-se imperativo saber como os novos clientes se comportariam em uma nova região com base nos dados anteriores que possuímos. Torna-se impossível conceber uma estratégia para cada indivíduo em uma população, mas será útil agrupar a população em grupos para que a estratégia seja eficaz em um grupo e seja escalável.
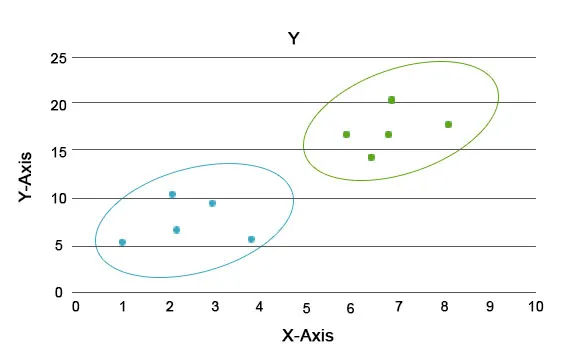
Aqui, as cores azul e laranja são diferentes aglomerados com características únicas dentro de si.
- Análise de Associação
Essa análise nos ajuda a construir relacionamentos interessantes entre itens em um conjunto de dados. Essa análise descobre relacionamentos ocultos e ajuda a representar itens do conjunto de dados na forma de regras de associação ou conjuntos de itens frequentes. A regra de associação é dividida em 2 etapas:
- Geração frequente de conjuntos de itens: nesse caso, um conjunto é gerado onde itens frequentes são configurados juntos.
- Geração de regras: o conjunto construído acima é passado por diferentes camadas de formação de regras para criar um relacionamento oculto entre si. Por exemplo, o conjunto pode se enquadrar em problemas conceituais ou de implementação ou em aplicativos. Estes são ramificados nas respectivas árvores para criar as regras de associação.
Por exemplo, APRIORI é um algoritmo de criação de regras de associação.
2. Aprendizado supervisionado
- Análise de regressão
Na análise de regressão, definimos a variável dependente / alvo e as demais variáveis como variáveis independentes e, eventualmente, levantamos a hipótese de como uma / mais variáveis independentes influenciam a variável alvo. A regressão com uma variável independente é denominada univariada e com mais de uma é conhecida como multivariada. Vamos entender o uso de univariado e depois escalar para multivariado.
Por exemplo, y é a variável de destino ex 1 é a variável independente. Assim, a partir do conhecimento da reta, podemos escrever a equação como y = mx 1 + c. Aqui "m" determina quão fortemente y é influenciado por x 1 . Se "m" estiver muito próximo de zero, significa que, com uma mudança em x 1, y não será afetado fortemente. Com um número maior que 1, o impacto fica mais forte e a pequena mudança em x 1 leva a uma grande variação em y. Semelhante ao univariado, no multivariado pode ser escrito como y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Aqui o impacto de cada variável independente é determinado pelo seu correspondente “m”.
- Análise de Classificação
Semelhante à análise de agrupamento, os algoritmos de classificação são criados com a variável de destino na forma de classes. A diferença entre agrupamento e classificação reside no fato de que, no agrupamento, não sabemos a que grupo os pontos de dados se enquadram, enquanto que, na classificação, sabemos a que grupo ele pertence. E difere da regressão da perspectiva de que o número de grupos deve ser um número fixo, diferentemente da regressão, é contínuo. Existem vários algoritmos na análise de classificação, por exemplo, Máquinas de Vetor de Suporte, Regressão Logística, Árvores de Decisão, etc.
Conclusão
Concluindo, entendemos que cada tipo de análise é vasto em si, mas aqui podemos fornecer um pequeno sabor a diferentes técnicas. Nas próximas anotações, pegaríamos cada um deles separadamente e entraríamos em detalhes sobre as diferentes sub-técnicas empregadas nas técnicas de cada pai.
Artigo recomendado
Este é um guia para técnicas de ciência de dados. Aqui discutimos a introdução e os diferentes tipos de técnicas em ciência de dados. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Ferramentas de ciência de dados | As 12 melhores ferramentas
- Algoritmos de ciência de dados com tipos
- Introdução à carreira em ciência de dados
- Data Science vs Visualização de Dados
- Exemplos de regressão multivariada
- Criar árvore de decisão com vantagens
- Breve visão geral do Ciclo de Vida da Ciência de Dados