

Introdução à arquitetura Hadoop
A arquitetura Hadoop é uma estrutura de código aberto que ajuda no processamento de grandes conjuntos de dados com facilidade. Ajuda na criação de aplicativos que processam dados enormes com mais velocidade. Ele utiliza os conceitos de computação distribuída, onde os dados são espalhados pelos diferentes nós de um cluster. Os aplicativos criados com o Hadoop usam computadores comuns. Esses computadores estão disponíveis facilmente no mercado a preços baratos. Esse resultado está alcançando maior poder computacional a baixo custo. Todos os dados presentes no Hadoop residem no HDFS em vez de em um sistema de arquivos local. O HDFS é um sistema de arquivos distribuídos do Hadoop. Este modelo é baseado na Localidade dos Dados, em que a lógica computacional é enviada aos nós presentes em um cluster que contém os dados. Essa lógica nada mais é do que uma lógica que compila o programa.
Arquitetura Hadoop
A idéia básica dessa arquitetura é que todo o armazenamento e processamento sejam feitos em duas etapas e de duas maneiras. A primeira etapa é o processamento realizado pelo Map reduz a programação e a segunda etapa é armazenar os dados executados no HDFS. Possui uma arquitetura mestre-escravo para armazenamento e processamento de dados. O nó principal para armazenamento de dados no Hadoop é o nó de nome. Há também um nó mestre que realiza o trabalho de monitoramento e paralela o processamento de dados usando o Hadoop Map Reduce. Os escravos são outras máquinas no cluster Hadoop que ajudam no armazenamento de dados e também realizam cálculos complexos. Cada nó escravo foi designado com um rastreador de tarefas e um nó de dados possui um rastreador de tarefas que ajuda na execução dos processos e na sincronização efetiva. Esse tipo de sistema pode ser configurado na nuvem ou no local. O nó Nome é um ponto único de falha quando não está em execução no modo de alta disponibilidade. A arquitetura do Hadoop também possui provisão para manter um nó em espera por Nome, a fim de proteger o sistema contra falhas. Anteriormente, havia nós de nome secundário que agiam como backup quando o nó de nome primário estava inativo.
FSimage e log de edição
O FSimage e o Log de edição garantem a persistência dos metadados do sistema de arquivos para acompanhar todas as informações e o nó de nome armazena os metadados em dois arquivos. Esses arquivos são o FSimage e o log de edição. O trabalho do FSimage é manter um instantâneo completo do sistema de arquivos em um determinado momento. As alterações que estão sendo feitas constantemente em um sistema precisam ser mantidas em registro. Essas alterações incrementais, como renomear ou anexar detalhes ao arquivo, são armazenadas no log de edição. A estrutura fornece uma opção melhor, em vez de criar uma nova FSimage sempre, uma opção melhor para armazenar os dados enquanto um novo arquivo para FSimage. O FSimage cria um novo instantâneo sempre que alterações são feitas. Se o nó Nome falhar, ele poderá restaurar seu estado anterior. O nó do nome secundário também pode atualizar sua cópia sempre que houver alterações no FSimage e editar logs. Portanto, garante que, mesmo que o nó de nome esteja inativo, na presença do nó de nome secundário, não haverá perda de dados. O nó de nome não requer que essas imagens tenham que ser recarregadas no nó de nome secundário.
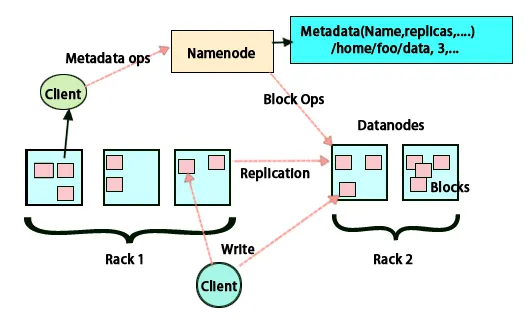
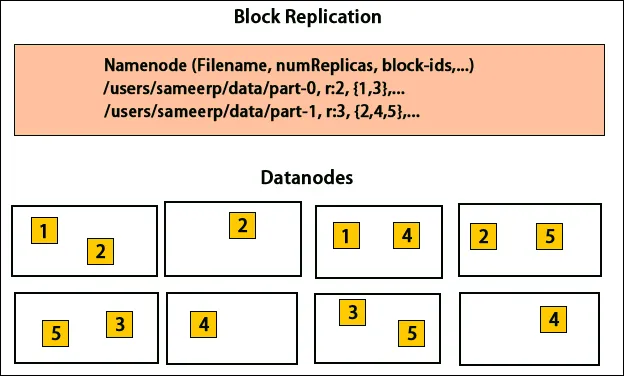
Replicação de Dados
O HDFS foi projetado para processar dados rapidamente e fornecer dados confiáveis. Ele armazena dados em máquinas e em grandes grupos. Todos os arquivos são armazenados em uma série de blocos. Esses blocos são replicados para tolerância a falhas. O tamanho do bloco e o fator de replicação podem ser decididos pelos usuários e configurados conforme os requisitos do usuário. Por padrão, o fator de replicação é 3. O fator de replicação pode ser especificado no momento da criação do arquivo e pode ser alterado posteriormente. Todas as decisões relacionadas a essas réplicas são tomadas pelo nó de nome. O nó de nome continua enviando pulsações e relatório de bloco em intervalos regulares para todos os nós de dados no cluster. O recebimento da pulsação indica que o nó de dados está funcionando corretamente. Relatório de bloco especifica a lista de todos os blocos presentes no nó de dados.
Colocação de réplicas
A colocação de réplicas é uma tarefa muito importante no Hadoop para confiabilidade e desempenho. Todos os diferentes blocos de dados são colocados em diferentes racks. A implementação do posicionamento da réplica pode ser feita de acordo com a confiabilidade, disponibilidade e utilização da largura de banda da rede. O cluster de computadores pode se espalhar por diferentes racks. Não mais que dois nós podem ser colocados no mesmo rack. A terceira réplica deve ser colocada em um rack diferente para garantir maior confiabilidade dos dados. Os dois nós no rack se comunicam através de switches diferentes. O nó do nome tem o ID do rack para cada nó de dados. Mas colocar todos os nós em racks diferentes evita a perda de dados e permite o uso da largura de banda de vários racks. Ele também reduz o tráfego entre rack e melhora o desempenho. Além disso, a chance de falha no rack é muito menor em comparação com a falha no nó. Reduz a largura de banda agregada da rede quando os dados estão sendo lidos em dois racks exclusivos, em vez de três.
Mapa Reduzir
O Map Reduce é usado para o processamento de dados armazenados no HDFS. Ele grava dados distribuídos em aplicativos distribuídos, o que garante um processamento eficiente de grandes quantidades de dados. Eles processam em grandes aglomerados e exigem produtos confiáveis e tolerantes a falhas. O núcleo da Redução de mapa pode ser três operações, como mapeamento, coleta de pares e embaralhamento dos dados resultantes.
Conclusão - Arquitetura Hadoop
O Hadoop é uma estrutura de código aberto que ajuda em um sistema tolerante a falhas. Ele pode armazenar grandes quantidades de dados e ajuda a armazenar dados confiáveis. As duas partes do armazenamento de dados no HDFS e do processamento através do mapa reduzem a ajuda no trabalho adequado e eficiente. Possui uma arquitetura que ajuda no gerenciamento de todos os blocos de dados e também na cópia mais recente, armazenando-a no FSimage e editando logs. O fator de replicação também ajuda a ter cópias de dados e recuperá-las sempre que houver uma falha. O HDFS também move os arquivos removidos para o diretório da lixeira para otimizar o uso do espaço.
Artigos recomendados
Este foi um guia para a arquitetura Hadoop. Aqui discutimos a arquitetura, redução de mapa, posicionamento de réplicas e replicação de dados. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Torne-se um desenvolvedor Hadoop
- Introdução ao Android
- O que é o Tableau? | Uma visão geral
- O que é o MapReduce no Hadoop?