
Introdução ao ciclo de vida da ciência de dados
O Ciclo de Vida da Ciência de Dados gira em torno do uso de aprendizado de máquina e outros métodos analíticos para produzir insights e previsões a partir dos dados, a fim de alcançar um objetivo de negócios. Todo o processo envolve várias etapas, como limpeza de dados, preparação, modelagem, avaliação de modelos etc. É um processo longo e pode levar vários meses para ser concluído. Portanto, é muito importante ter uma estrutura geral a seguir para cada problema em questão. A estrutura reconhecida globalmente na solução de qualquer problema analítico é chamada de estrutura padrão de processo entre indústrias para mineração de dados ou CRISP-DM.
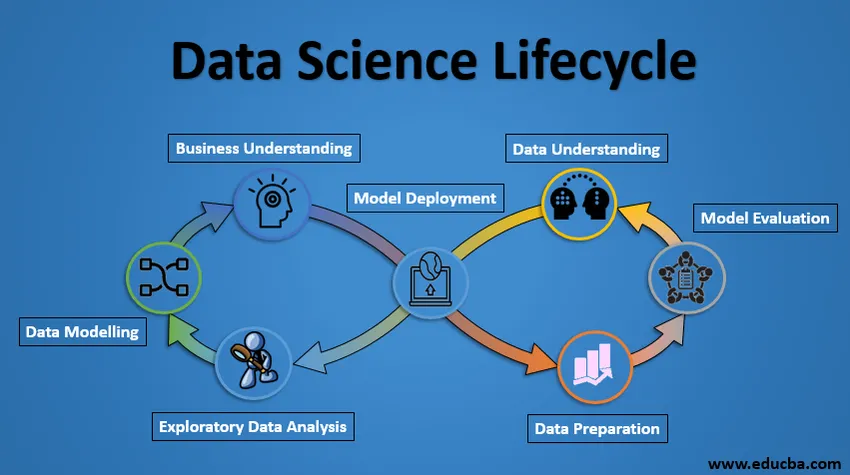
Ciclo de vida da ciência de dados
Abaixo está o projeto Lifecycle of Data Science.
1. Entendimento comercial
Todo o ciclo gira em torno da meta de negócios. O que você resolverá se não tiver um problema preciso? É extremamente importante entender claramente o objetivo do negócio, porque esse será seu objetivo final da análise. Após o entendimento adequado, apenas podemos definir o objetivo específico da análise que está sincronizado com o objetivo do negócio. Você precisa saber se o cliente deseja reduzir a perda de crédito ou se deseja prever o preço de uma mercadoria, etc.
2. Compreensão dos dados
Após o entendimento dos negócios, o próximo passo é o entendimento dos dados. Isso envolve a coleta de todos os dados disponíveis. Aqui, você precisa trabalhar em estreita colaboração com a equipe de negócios, pois eles estão realmente cientes de quais dados estão presentes, quais dados podem ser usados para esse problema de negócios e outras informações. Esta etapa envolve a descrição dos dados, sua estrutura, relevância, tipo de dados. Explore os dados usando gráficos. Basicamente, extrair qualquer informação que você possa obter sobre os dados apenas explorando os dados.
3. Preparação de Dados
Em seguida, vem o estágio de preparação dos dados. Isso inclui etapas como selecionar os dados relevantes, integrar os dados mesclando os conjuntos de dados, limpando-os, tratando os valores ausentes, removendo-os ou imputando-os, tratando dados errados, removendo-os, verifique também se há discrepâncias usando gráficos de caixa e lide com eles . Construindo novos dados, obtenha novos recursos dos já existentes. Formate os dados na estrutura desejada, remova colunas e recursos indesejados. A preparação de dados é a etapa que consome mais tempo e, sem dúvida, é a etapa mais importante de todo o ciclo de vida. Seu modelo será tão bom quanto seus dados.
4. Análise Exploratória de Dados
Esta etapa envolve ter uma idéia sobre a solução e os fatores que a afetam, antes de criar o modelo real. A distribuição de dados dentro de diferentes variáveis de um recurso é explorada graficamente usando gráficos de barras. As relações entre diferentes recursos são capturadas através de representações gráficas, como gráficos de dispersão e mapas de calor. Muitas outras técnicas de visualização de dados são amplamente utilizadas para explorar todos os recursos individualmente e combiná-los com outros recursos.
5. Modelagem de Dados
A modelagem de dados é o coração da análise de dados. Um modelo toma os dados preparados como entrada e fornece a saída desejada. Esta etapa inclui a escolha do tipo apropriado de modelo, se o problema é de classificação, de regressão ou de cluster. Após escolher a família do modelo, dentre os vários algoritmos dentre essa família, precisamos escolher cuidadosamente os algoritmos para implementá-los e implementá-los. Precisamos ajustar os hiperparâmetros de cada modelo para alcançar o desempenho desejado. Também precisamos garantir que haja um equilíbrio correto entre desempenho e generalização. Não queremos que o modelo aprenda os dados e tenha um desempenho ruim em novos dados.
6. Avaliação do Modelo
Aqui, o modelo é avaliado para verificar se está pronto para ser implementado. O modelo é testado em dados não vistos, avaliados em um conjunto de métricas de avaliação cuidadosamente pensadas. Também precisamos garantir que o modelo esteja em conformidade com a realidade. Se não obtivermos um resultado satisfatório na avaliação, devemos reiterar todo o processo de modelagem até que o nível desejado de métricas seja alcançado. Qualquer solução de ciência de dados, um modelo de aprendizado de máquina, como um humano, deve evoluir, deve ser capaz de melhorar a si mesmo com novos dados, adaptar-se a uma nova métrica de avaliação. Podemos construir vários modelos para um determinado fenômeno, mas muitos deles podem ser imperfeitos. A avaliação do modelo nos ajuda a escolher e construir um modelo perfeito.
7. Implantação do modelo
O modelo após uma avaliação rigorosa é finalmente implantado no formato e no canal desejados. Esta é a etapa final do ciclo de vida da ciência de dados. Cada etapa do ciclo de vida da ciência de dados explicada acima deve ser trabalhada com cuidado. Se qualquer etapa for executada incorretamente, ela afetará a próxima etapa e todo o esforço será desperdiçado. Por exemplo, se os dados não forem coletados corretamente, você perderá informações e não criará um modelo perfeito. Se os dados não forem limpos corretamente, o modelo não funcionará. Se o modelo não for avaliado adequadamente, ele falhará no mundo real. Desde o entendimento dos negócios até a implantação do modelo, cada etapa deve receber atenção, tempo e esforço adequados.
Artigos recomendados
Este é um guia para o Ciclo de Vida da Ciência de Dados. Aqui discutimos uma visão geral do ciclo de vida da ciência de dados e as etapas que compõem um ciclo de vida da ciência de dados. Você também pode ler nossos artigos relacionados para saber mais -
- Introdução aos algoritmos de ciência de dados
- Ciência de dados versus engenharia de software | Top 8 Comparações úteis
- Tipos de diferença de técnicas de ciência de dados
- Habilidades de ciência de dados com tipos