
Introdução ao Hive Group por
Agrupar por, como o nome sugere, agrupará o registro que satisfaz certos critérios. Neste artigo, veremos o grupo da HIVE. No RDBMS legado, como MySQL, SQL, etc, agrupar por é uma das cláusulas mais antigas que estão sendo usadas. Agora, ele encontrou seu lugar de maneira semelhante no armazenamento de dados baseado em arquivos, conhecido como HIVE.
Sabemos que o Hive ultrapassou muitos RDBMS legados no tratamento de grandes dados sem gastar um centavo em fornecedores para manter os bancos de dados e servidores. Nós apenas precisamos configurar o HDFS para lidar com a seção. Geralmente, passamos para as tabelas porque o usuário final pode interpretar a partir de sua estrutura e pode consultar, pois os arquivos serão desajeitados para eles. Mas tivemos que fazer isso pagando aos fornecedores para fornecer servidores e manter nossos dados no formato de tabelas. Portanto, o Hive fornece o mecanismo econômico em que tira proveito dos sistemas baseados em arquivos (a maneira como o hive salva seus dados) e também das tabelas (estrutura da tabela para consulta dos usuários finais).
Agrupar por
Agrupar por usa as colunas definidas da tabela Hive para agrupar os dados. Por exemplo, considere que você tem uma tabela com os dados do censo de cada cidade de todos os estados em que o nome da cidade e o nome do estado são uma das colunas. Agora, na consulta, se agruparmos por estados, todos os dados de diferentes cidades de um determinado estado serão agrupados e é possível visualizar facilmente os dados agora antes da forma como o grupo foi aplicado.
Sintaxe do Hive Group por
A sintaxe geral do grupo por cláusula é a seguinte:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
ou para consultas mais simples,
from Group By
Select department, count(*) from the university.college Group By department;
Aqui, o departamento se refere a uma das colunas da tabela da faculdade, que está presente no banco de dados da universidade e seu valor é variado em departamentos como artes, matemática, engenharia, etc. Agora, vamos ver alguns exemplos para demonstrar o agrupamento.
Eu criei uma tabela de exemplo deck_of_cards para demonstrar o grupo por. Sua instrução create table é a seguinte:
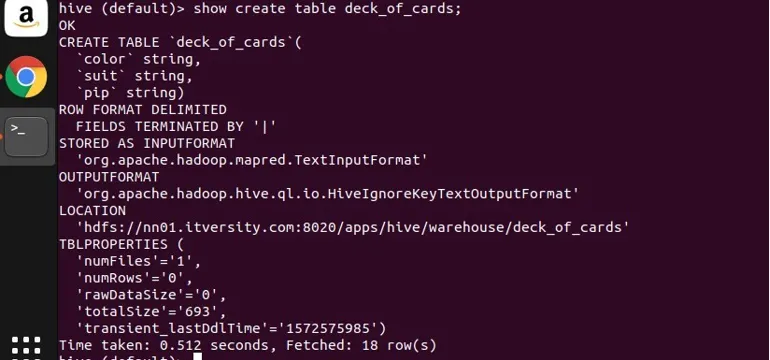
Você pode ver de cima que ele tem três colunas de cor, naipe e pip. Deixe-me escrever uma consulta para agrupar os dados por sua cor e obter sua contagem.
select color, count(*) from deck_of_cards group by color;
O Hive basicamente leva a consulta acima para convertê-la no programa de redução de mapa, gerando o código java e o arquivo jar correspondentes e, em seguida, é executado. Esse processo pode demorar um pouco, mas definitivamente pode lidar com o big data em comparação com o RDBMS tradicional. Veja a captura de tela abaixo com o log detalhado para executar a consulta acima.
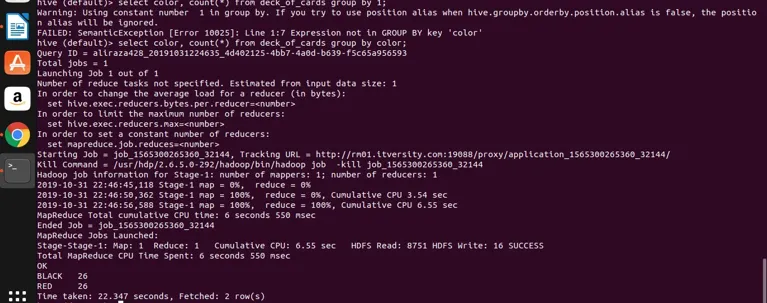
você pode ver que PRETO é 26 e VERMELHO é 26.
Agora, vamos aplicar o agrupamento em duas colunas (cor e naipe e obter a contagem do grupo) e ver o resultado abaixo.
Select color, suit, count(*) from deck_of_cards group by color, suit
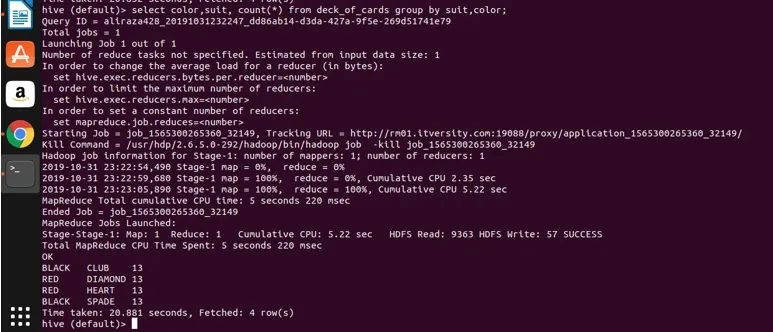
Basicamente, existem quatro grupos distintos acima do Club, Spade, que têm a cor preta e Diamond e coração, que são da cor vermelha.
Armazenando o resultado do grupo por causa em outra tabela
O Hive, como qualquer outro RDBMS, fornece o recurso de inserir os dados com instruções de criação de tabela. Vejamos como armazenar o resultado de uma expressão selecionada usando um grupo by em outra tabela. Deixe-me usar a consulta acima em si, onde usei duas colunas no grupo por.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
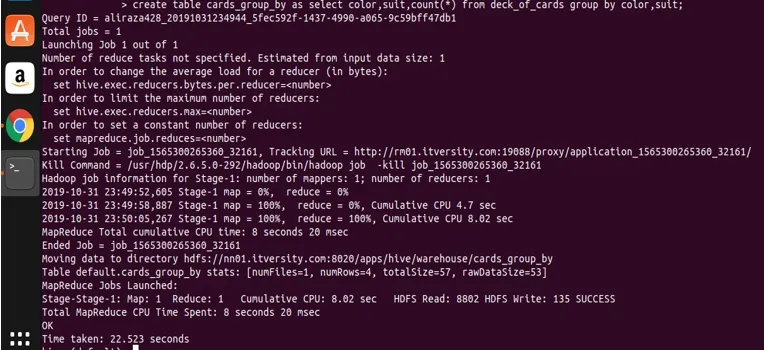
Agora, vamos consultar a tabela criada para ver e validar os dados.

Agora vamos restringir o resultado do grupo usando a cláusula having. Conforme mostrado na sintaxe genérica, podemos aplicar restrições ao grupo, usando having. Aqui, estou usando a tabela ordser_items e sua estrutura é a seguinte na instrução de descrição.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
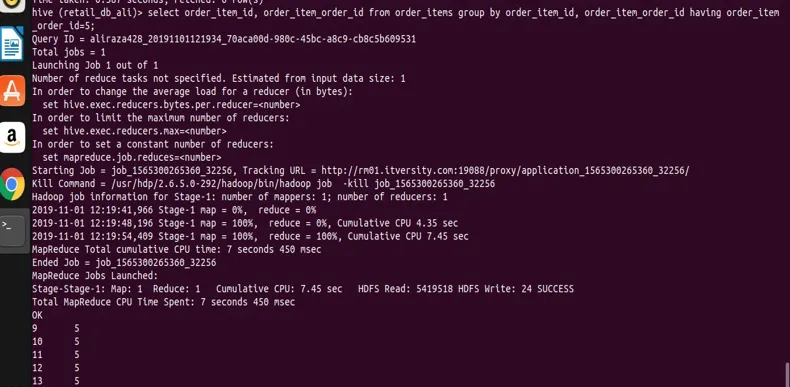
você pode ver no resultado a captura de tela de que temos registros apenas com o valor order_item_order_id 5.
Agrupar por junto com a declaração de caso
Agora, vejamos consultas um pouco complexas envolvendo as instruções CASE com o grupo por. Aplicaremos isso à tabela order_items. Veremos abaixo que podemos categorizar as colunas não agregadoras nas quais não podemos aplicar o grupo por cláusula diretamente.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
vamos executá-lo na colméia para obter resultados
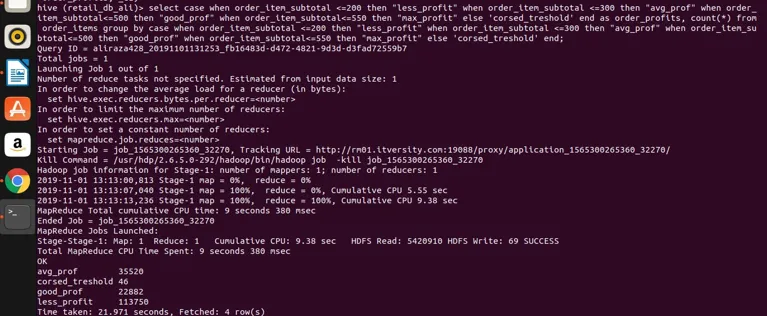
Conclusão - Hive Group By
para que possamos ver que agrupamos o order_item_subtotal em quatro categorias diferentes (se você observar que order_item_subtotal é uma coluna não agregadora e um grupo direto não pode ser aplicado a ele), nós os agrupamos e obtivemos suas contagens também para os valores que satisfazem o intervalo, conforme definido na expressão de seleção. Aqui a regra simples, se a coluna não é agregadora e nossa expressão de seleção é complexa, qualquer que seja a expressão de seleção que também deve estar presente no grupo pela expressão de cláusula. Portanto, vimos como uma cláusula famosa de grupo de cláusulas RDBMS também pode ser aplicada no Hive sem nenhuma restrição. Pode ser aplicado a expressões simples de seleção. Expressões agregadas e de filtragem, expressões de junção e expressões CASE complexas também.
Artigos recomendados
Este é um guia para o Hive Group By. Aqui discutimos o grupo, sintaxe, exemplos do grupo de colméias, com diferentes condições e implementação. Você também pode consultar os seguintes artigos para saber mais -
- Junta-se ao Hive
- O que é uma colméia?
- Arquitetura do Hive
- Função Hive
- Hive Order By
- Instalação do Hive
- Os 6 principais tipos de junções no MySQL com exemplos