

Introdução aos métodos de mineração de dados
Os dados estão aumentando diariamente em uma escala enorme. Mas todos os dados coletados ou coletados não são úteis. Dados significativos devem ser separados de dados ruidosos (dados sem sentido). Esse processo de separação é feito pela mineração de dados.
O que é mineração de dados?
A mineração de dados é um processo de extração de informações ou conhecimentos úteis de uma enorme quantidade de dados (ou big data). A diferença entre dados e informações foi reduzida usando várias ferramentas de mineração de dados. A mineração de dados também pode ser chamada de descoberta de conhecimento a partir de dados ou KDD .
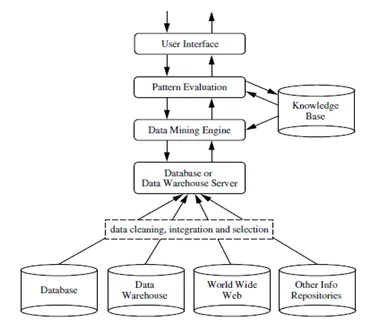
Fontes: - www.ques10.com
A mineração de dados pode ser realizada em vários tipos de bancos de dados e repositórios de informações, como bancos de dados relacionais, data warehouses, bancos de dados transacionais, fluxos de dados e muito mais.
Diferentes métodos de mineração de dados:
Existem muitos métodos usados para mineração de dados, mas a etapa crucial é selecionar o método apropriado deles de acordo com a empresa ou a declaração do problema. Esses métodos de mineração de dados ajudam a prever o futuro e a tomar decisões em conformidade. Isso também ajuda na análise da tendência do mercado e no aumento da receita da empresa.
Alguns métodos de mineração de dados são:
- Associação
- Classificação
- Análise de Cluster
- Predição
- Padrões seqüenciais ou rastreamento de padrões
- Árvores de decisão
- Análise de Outlier ou Anomaly Analysis
- Rede neural
Vamos entender todos os métodos de mineração de dados, um por um.
1. Associação:
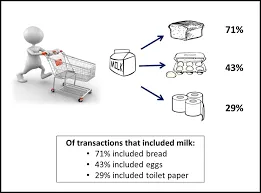
É um método usado para encontrar uma correlação entre dois ou mais itens, identificando o padrão oculto no conjunto de dados e, portanto, também chamado de análise de relação . Este método é usado na análise da cesta de mercado para prever o comportamento do cliente.
Suponha que o gerente de marketing de um supermercado queira determinar quais produtos são frequentemente comprados juntos.
Como um exemplo,
Compras (x, "cerveja") -> compras (x, "batatas fritas") (suporte = 1%, confiança = 50%)
- Aqui x representa um cliente que compra cerveja e batatas fritas juntos.
- A confiança mostra certeza de que, se um cliente compra uma cerveja, há 50% de chance de comprar as batatas também.
- Suporte significa que 1% de todas as transações analisadas mostraram que cerveja e batatas fritas foram compradas juntas.
Muitos exemplos semelhantes, como pão e manteiga ou computador e software, podem ser considerados.
Existem dois tipos de regras de associação:
- Regra de associação unidimensional: essas regras contêm um único atributo que é repetido.
- Regra de associação multidimensional: essas regras contêm vários atributos que são repetidos.
https://bit.ly/2N61gzR
2. Classificação:
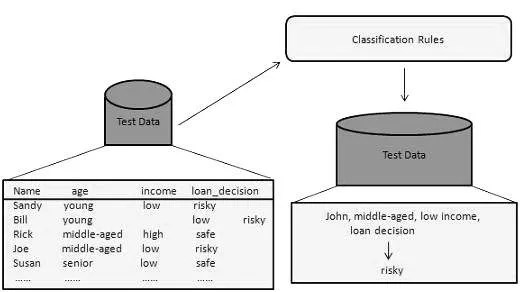
Esse método de mineração de dados é usado para distinguir os itens nos conjuntos de dados em classes ou grupos. Ajuda a prever com precisão o comportamento dos itens dentro do grupo. É um processo de duas etapas:
- Etapa de aprendizado (fase de treinamento): nesse caso, um algoritmo de classificação cria o classificador analisando um conjunto de treinamento.
- Etapa de classificação: Os dados de teste são usados para estimar a exatidão ou precisão das regras de classificação.
Por exemplo, uma empresa bancária usa para identificar candidatos a empréstimos com riscos de crédito baixos, médios ou altos. Da mesma forma, um pesquisador médico analisa os dados do câncer para prever qual remédio prescrever ao paciente.
Fontes: - www.tutorialspoint.com
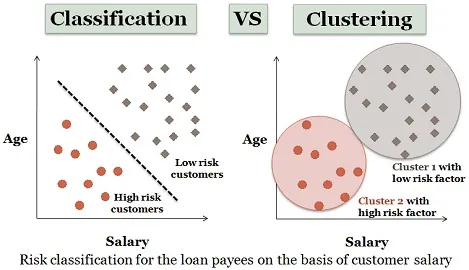
3. Análise de Clustering:
O agrupamento é quase semelhante à classificação, mas nesses agrupamentos são feitos dependendo das semelhanças dos itens de dados. Clusters diferentes têm objetos diferentes ou não relacionados. Também é chamado de segmentação de dados, pois divide grandes conjuntos de dados em clusters de acordo com as semelhanças.
Existem vários métodos de cluster usados:
- Métodos Aglomerativos Hierárquicos
- Métodos baseados em grade
- Métodos de particionamento
- Métodos baseados em modelo
- Métodos baseados em densidade
Exemplo semelhante de solicitantes de empréstimo também pode ser considerado aqui. Existem algumas diferenças descritas na figura abaixo.
https://bit.ly/2N6aZpP
4. Previsão:
Este método é usado para prever o futuro com base nas tendências ou no conjunto de dados passados e presentes. A previsão é usada principalmente com a combinação de outros métodos de mineração de dados, como classificação, correspondência de padrões, análise de tendências e relação.
Por exemplo, se o gerente de vendas de um supermercado gostaria de prever a quantidade de receita que cada item geraria com base nos dados de vendas anteriores. Ele modela a função com valor contínuo que prevê valores de dados numéricos ausentes.

Fontes: - data-mining.philippe-fournier
A análise de regressão é a melhor opção para realizar previsões. Pode ser usado para definir um relacionamento entre variáveis independentes e variáveis dependentes.
5. Padrões seqüenciais ou rastreamento de padrões:
Esse método de mineração de dados é usado para identificar padrões que ocorrem com frequência durante um determinado período de tempo.
Por exemplo, o gerente de vendas da empresa de roupas vê que as vendas de jaquetas parecem aumentar pouco antes da temporada de inverno, ou as vendas de padarias aumentam durante o Natal ou o Ano Novo.
Vejamos um exemplo com um gráfico
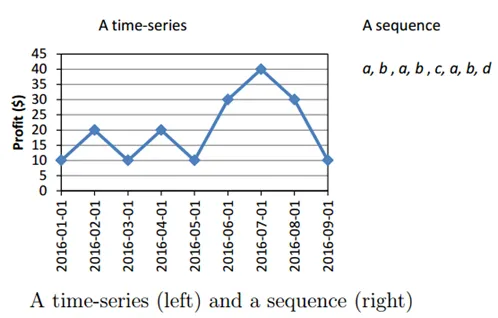
Fontes: - data-mining.philippe-fournier-viger
6. árvores de decisão:
Uma árvore de decisão é uma estrutura de árvore (como o nome sugere), em que
- Cada nó interno representa um teste no atributo.
- Ramificação indica o resultado do teste.
- Os nós do terminal mantêm o rótulo da classe.
- O nó superior é o nó raiz que possui a pergunta simples que possui duas ou mais respostas. Consequentemente, a árvore cresce e um fluxograma como estrutura é gerado.
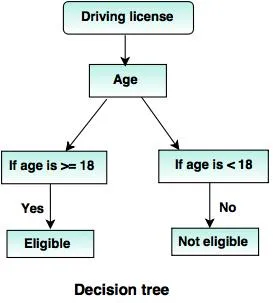
Fontes: - www.tutorialride.com
Nesta decisão, o governo da árvore classifica os cidadãos com menos de 18 anos ou acima dos 18 anos. Isso os ajudaria a decidir se uma licença deve ser emitida para um determinado cidadão ou não.
Análise 7.Outlier ou Anomaly Analysis:
Esse método de mineração de dados é usado para identificar os itens de dados que não estão em conformidade com o padrão ou o comportamento esperado. Esses itens de dados inesperados são considerados outliers ou ruído. Eles são úteis em muitos domínios, como detecção de fraude com cartão de crédito, detecção de intrusão, detecção de falhas etc. Isso também é chamado de Mineração Outlier .
Por exemplo, vamos supor que o gráfico abaixo seja plotado usando alguns conjuntos de dados em nosso banco de dados.
Portanto, a melhor linha de ajuste é desenhada. Os pontos próximos à linha mostram o comportamento esperado, enquanto o ponto distante da linha é um Outlier.
Isso ajudaria a detectar as anomalias e tomar as possíveis ações em conformidade.
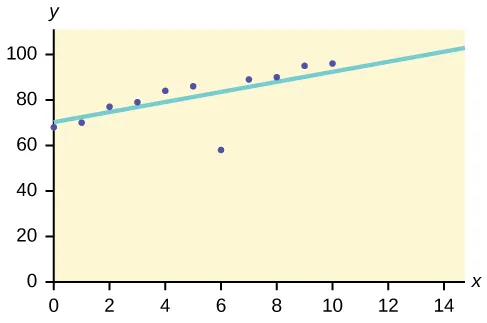
https://bit.ly/2GrgjDP
8. Rede Neural:
Esse método ou modelo de mineração de dados é baseado em redes neurais biológicas. É uma coleção de neurônios como unidades de processamento com conexões ponderadas entre eles. Eles são usados para modelar o relacionamento entre entradas e saídas. É usado para classificação, análise de regressão, processamento de dados etc. Esta técnica funciona em três pilares:
- Modelo
- Algoritmo de aprendizado (supervisionado ou não supervisionado)
- Função de ativação
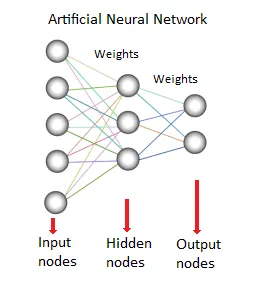
Fontes: - www.saedsayad.com
Artigos recomendados
Este foi um guia para os métodos de mineração de dados Aqui discutimos o que é mineração de dados e os diferentes tipos de método de mineração de dados com o exemplo. Você também pode consultar os seguintes artigos para saber mais -
- Software de Análise de Big Data
- Perguntas da entrevista sobre estrutura de dados
- Técnicas importantes de mineração de dados
- Arquitetura de mineração de dados