
Introdução às Técnicas de Conjunto
O aprendizado por conjunto é uma técnica de aprendizado de máquina que leva a ajuda de vários modelos básicos e combina sua saída para produzir um modelo otimizado. Esse tipo de algoritmo de aprendizado de máquina ajuda a melhorar o desempenho geral do modelo. Aqui, o modelo base mais comumente usado é o classificador da árvore de Decisão. Uma árvore de decisão trabalha basicamente em várias regras e fornece uma saída preditiva, onde as regras são os nós e suas decisões serão seus filhos e os nós folha constituirão a decisão final. Como mostrado no exemplo de uma árvore de decisão.
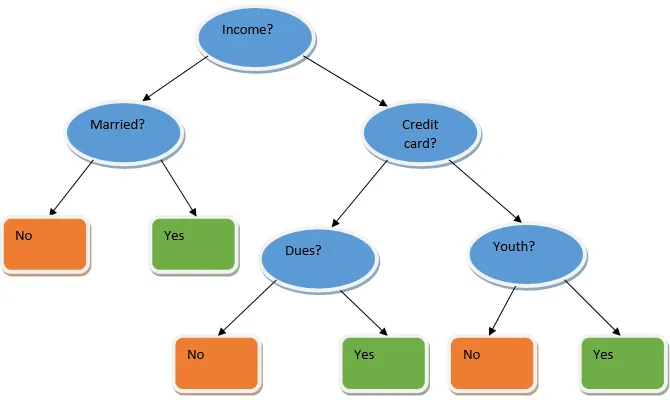
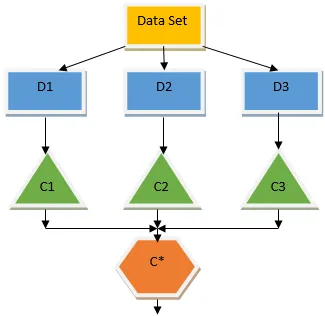
A árvore de decisão acima fala basicamente sobre se uma pessoa / cliente pode receber um empréstimo ou não. Uma das regras para a elegibilidade do empréstimo sim é que, se (renda = Sim && Casado = Não) Então Empréstimo = Sim, então é assim que um classificador da árvore de decisão funciona. Incorporaremos esses classificadores como um modelo de base múltipla e combinaremos sua saída para criar um modelo preditivo ideal. A Figura 1.b mostra a imagem geral de um algoritmo de aprendizado de conjunto.
Tipos de técnicas de conjuntos
Diferentes tipos de conjuntos, mas nosso foco principal será nos dois tipos abaixo:
- Ensacamento
- Impulsionar
Esses métodos ajudam a reduzir a variação e o viés em um modelo de aprendizado de máquina. Agora vamos tentar entender o que é preconceito e variação. Viés é um erro que ocorre devido a suposições incorretas em nosso algoritmo; um viés alto indica que nosso modelo é muito simples / não adequado. Variação é o erro causado devido à sensibilidade do modelo a flutuações muito pequenas no conjunto de dados; uma alta variação indica que nosso modelo é altamente complexo / superajustado. Um modelo ideal de ML deve ter um equilíbrio adequado entre viés e variância.
Agregação / Ensacamento de Bootstrap
Ensacamento é uma técnica de ensemble que ajuda a reduzir a variação no nosso modelo e, portanto, evita o excesso de ajuste. O ensacamento é um exemplo do algoritmo de aprendizado paralelo. O ensacamento funciona com base em dois princípios.
- Bootstrapping: No conjunto de dados original, diferentes populações de amostra são consideradas com a substituição.
- Agregando: calculando a média dos resultados de todos os classificadores e fornecendo uma saída única, para isso, utiliza o voto majoritário no caso de classificação e a média no caso do problema de regressão. Um dos famosos algoritmos de aprendizado de máquina que usam o conceito de ensacamento é uma floresta aleatória.
Random Forest
Na floresta aleatória da amostra aleatória retirada da população com substituição e um subconjunto de recursos é selecionado no conjunto de todos os recursos que uma árvore de decisão é construída. A partir desses subconjuntos de recursos, o que fornecer a melhor divisão é selecionado como raiz da árvore de decisão. O subconjunto de recursos deve ser escolhido aleatoriamente a qualquer custo, caso contrário, produziremos apenas árvores correlatas e a variação do modelo não será aprimorada.
Agora que construímos nosso modelo com as amostras retiradas da população, a questão é como validamos o modelo? Como estamos considerando as amostras com substituição, portanto, todas as amostras não serão consideradas e algumas delas não serão incluídas em nenhum saco, que são chamadas de amostras fora do saco. Podemos validar nosso modelo com essas amostras OOB (fora do saco). Os parâmetros importantes a serem considerados em uma floresta aleatória são o número de amostras e o número de árvores. Vamos considerar 'm' como o subconjunto de recursos e 'p' é o conjunto completo de recursos; agora, como regra geral, é sempre ideal escolher
- m as√ e um tamanho mínimo de nó como 1 para um problema de classificação.
- m como P / 3 e tamanho mínimo do nó para 5 para um problema de regressão.
O ep devem ser tratados como parâmetros de ajuste quando lidamos com um problema prático. O treinamento pode ser encerrado quando o erro OOB se estabilizar. Uma desvantagem da floresta aleatória é que, quando temos 100 recursos em nosso conjunto de dados e apenas alguns são importantes, esse algoritmo apresenta um desempenho ruim.
Impulsionar
O impulso é um algoritmo de aprendizado sequencial que ajuda a reduzir o viés em nosso modelo e a variação em alguns casos de aprendizado supervisionado. Também ajuda na conversão de alunos fracos em alunos fortes. O impulso funciona com o princípio de colocar os alunos fracos sequencialmente e atribui um peso a cada ponto de dados após cada rodada; mais peso é atribuído ao ponto de dados classificado incorretamente na rodada anterior. Esse método ponderado sequencial de treinamento de nosso conjunto de dados é a principal diferença do ensacamento.
A Fig3.a mostra a abordagem geral para impulsionar
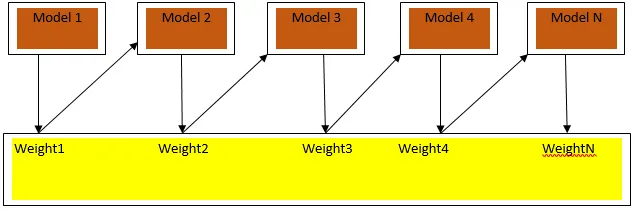
As previsões finais são combinadas com base na votação por maioria ponderada no caso de classificação e soma ponderada no caso de regressão. O algoritmo de reforço mais utilizado é o reforço adaptativo (Adaboost).
Reforço adaptável
As etapas envolvidas no algoritmo Adaboost são as seguintes:
- Para os n pontos de dados fornecidos, definimos a classe de destino e inicializamos todos os pesos para 1 / n.
- Ajustamos os classificadores ao conjunto de dados e escolhemos a classificação com o erro de classificação menos ponderado
- Atribuímos pesos para o classificador por uma regra geral baseada na precisão, se a precisão for superior a 50%, o peso será positivo e vice-versa.
- Atualizamos os pesos dos classificadores no final da iteração; atualizamos mais peso para o ponto classificado incorretamente, para que na próxima iteração o classifiquemos corretamente.
- Após toda a iteração, obtemos o resultado final da previsão com base na votação majoritária / média ponderada.
O Adaboosting trabalha eficientemente com alunos fracos (menos complexos) e com classificadores de alto viés. As principais vantagens do Adaboosting são que ele é rápido, não há parâmetros de ajuste semelhantes ao caso do ensacamento e não fazemos suposições sobre alunos fracos. Esta técnica falha em fornecer um resultado preciso quando
- Existem mais discrepâncias em nossos dados.
- O conjunto de dados é insuficiente.
- Os alunos fracos são altamente complexos.
Eles são suscetíveis ao ruído também. As árvores de decisão que são produzidas como resultado do aumento terão profundidade limitada e alta precisão.
Conclusão
As técnicas de aprendizado de conjuntos são amplamente usadas para melhorar a precisão do modelo; precisamos decidir sobre qual técnica usar com base em nosso conjunto de dados. Mas essas técnicas não são preferidas em alguns casos em que a interpretabilidade é importante, pois perdemos a interpretabilidade à custa da melhoria do desempenho. Eles têm um significado tremendo no setor de assistência médica, onde uma pequena melhoria no desempenho é muito valiosa.
Artigos recomendados
Este é um guia para técnicas de conjunto. Aqui discutimos a introdução e dois tipos principais de técnicas de conjunto. Você também pode consultar nossos outros artigos relacionados para saber mais.
- Técnicas de esteganografia
- Técnicas de aprendizado de máquina
- Técnicas de Team Building
- Algoritmos de ciência de dados
- Técnicas mais usadas de aprendizagem por conjuntos