

Visão geral dos aplicativos Kafka
Um dos campos de tendências do setor de TI é o Big Data, onde a empresa lida com uma grande quantidade de dados de clientes e obtém informações úteis que ajudam seus negócios e fornecem aos clientes um melhor serviço. Um dos desafios é manipular e transferir esses grandes volumes de dados de uma extremidade para outra para análise ou processamento; é aqui que o Kafka (um sistema confiável de mensagens) entra em ação, o que ajuda na coleta e transporte de um grande volume de dados em tempo real. O Kafka foi projetado para sistemas distribuídos de alto rendimento e é adequado para aplicativos de processamento de mensagens em larga escala. Kafka suporta muitas das melhores aplicações comerciais e industriais de hoje. Há uma demanda por profissionais Kafka com fortes habilidades e conhecimentos práticos.
Neste artigo, aprenderemos sobre o Kafka, seus recursos, casos de uso e entenderemos alguns aplicativos notáveis onde ele é usado.
O que é Kafka?
O Apache Kafka foi desenvolvido no LinkedIn e mais tarde se tornou um projeto Apache de código aberto. O Apache Kafka é um sistema de mensagens rápido, tolerante a falhas, escalonável e distribuído que permite a comunicação entre duas entidades, entre produtores (gerador da mensagem) e consumidores (receptor da mensagem) usando tópicos baseados em mensagens e fornece uma plataforma para gerenciar todos os os feeds de dados em tempo real.
Os recursos que tornam o Apache Kafka melhor do que outros sistemas de mensagens e aplicáveis a sistemas em tempo real são sua alta disponibilidade, recuperação imediata e automática de falhas nos nós e suporta a entrega de mensagens de baixa latência. Esses recursos do Apache Kafka ajudam na integração com sistemas de dados em grande escala e o tornam um componente ideal para comunicação. 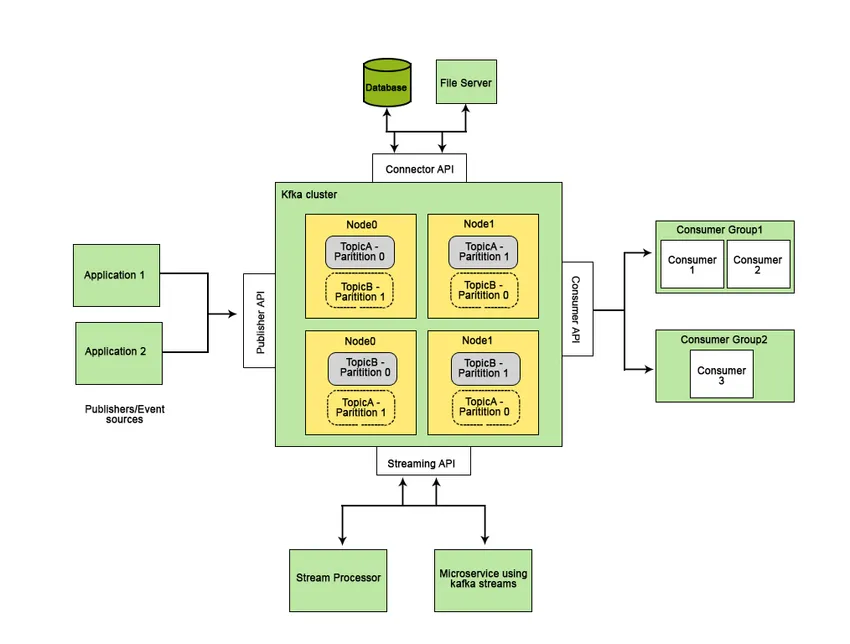
Principais aplicativos Kafka
Nesta seção do artigo, veremos alguns casos de uso populares e amplamente implementados e algumas implementações reais do Kafka.
Aplicativos da vida real
1. Twitter: Atividade de processamento de fluxo
O Twitter é uma plataforma de rede social que usa o Storm-Kafka (ferramenta de processamento de fluxo de código-fonte aberto) como parte de sua infraestrutura de processamento de fluxo, onde dados de entrada (tweets) são consumidos para agregação, transformações e enriquecimento para posterior consumo ou acompanhamento atividades de processamento.
2. LinkedIn: Processamento e métricas de fluxo
O LinkedIn usa o Kafka para transmitir dados e para atividades de métricas operacionais. O LinkedIn usa o Kafka para seus recursos adicionais, como o Newsfeed, para consumir mensagens e realizar análises dos dados recebidos.
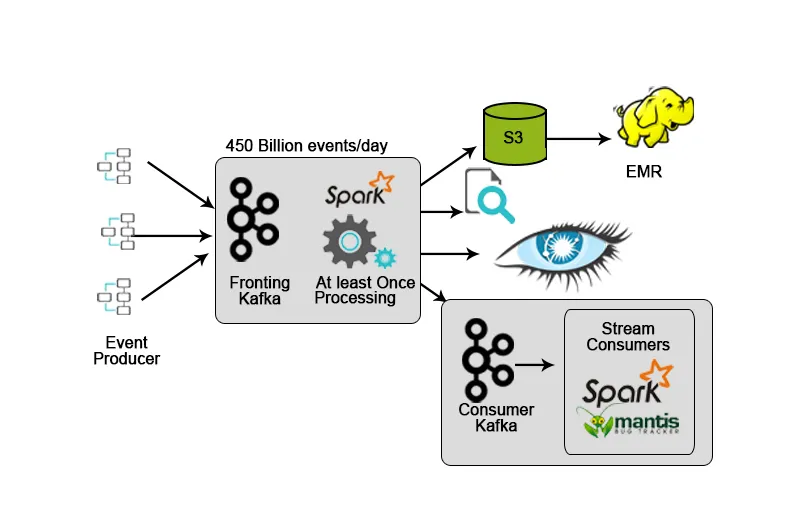
3. Netflix: Monitoramento em Tempo Real e Processamento de Stream
A Netflix tem sua própria estrutura de ingestão que despeja dados de entrada no AWS S3 e usa o Hadoop para executar análises de fluxos de vídeo, atividades de interface do usuário, eventos para aprimorar a experiência do usuário e Kafka para ingestão de dados em tempo real por meio de APIs.
4. Hotstar: Processamento de Stream
A Hotstar lançou sua própria plataforma de gerenciamento de dados - o Bifrost, onde o Kafka é usado para streaming de dados, monitoramento e rastreamento de alvos. Devido à sua escalabilidade, disponibilidade e recursos de baixa latência, o Kafka foi a escolha ideal para lidar com os dados que a plataforma hotstar gera diariamente ou em qualquer ocasião especial (transmissão ao vivo de concertos ou partidas esportivas ao vivo etc.), onde o volume de dados aumenta significativamente.
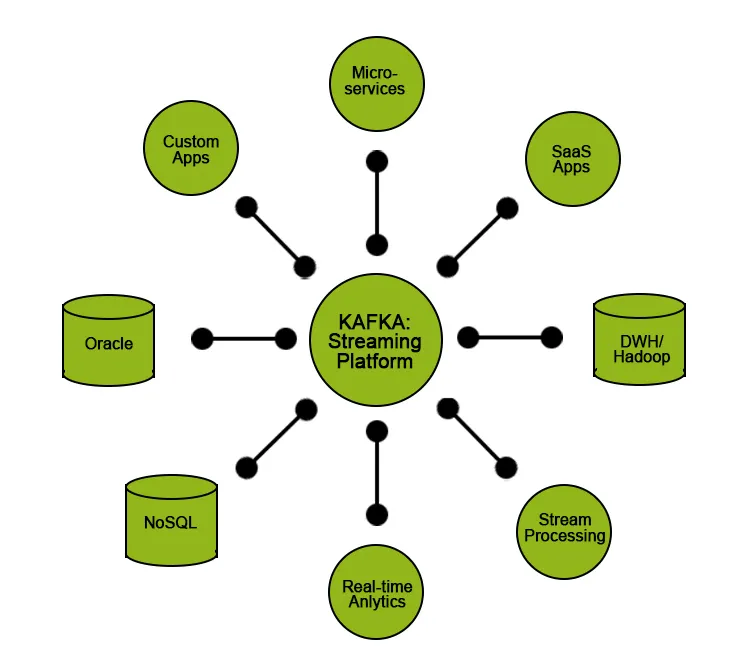
O Apache Kafka na maioria das vezes é usado como um bloco de construção para desenvolver a arquitetura de dados de streaming. Esse tipo de arquitetura é usado em aplicativos como uma coleção de logs de produtos / servidores, análise do fluxo de cliques e informações derivadas de dados gerados por máquina.
Mas, juntamente com o Kafka, precisamos usar recursos ou ferramentas adicionais para converter o fluxo de dados obtido em dados significativos que ajudam a obter insights que podem ser usados nas decisões orientadas por dados. Por exemplo, podemos precisar gerar informações a partir dos dados brutos obtidos dos dispositivos IoT ou dados obtidos das plataformas de mídia social em tempo real e realizar algumas análises ou processamento e mostrá-los aos negócios para tomar melhores decisões ou ajudá-los a melhorar o desempenho de seus serviços.
Para esses tipos de casos de uso, gostaríamos de transmitir nossos dados de entrada / dados brutos para um data lake, onde podemos armazenar nossos dados e garantir a qualidade dos dados sem prejudicar o desempenho.
Uma situação diferente, podemos estar lendo dados diretamente do Kafka, é quando precisamos de latência de ponta a ponta extremamente baixa, como alimentar dados para aplicativos em tempo real.
Kafka apresenta certas funcionalidades para seus usuários:
- Publique e assine dados.
- Armazene os dados na ordem em que foram gerados com eficiência.
- Processamento de dados em tempo real / em tempo real.
Kafka é usado na maioria das vezes para:
- Implementação de pipelines de dados de streaming dinâmicos que obtêm dados de forma confiável entre duas entidades no sistema.
- Implementar aplicativos de streaming dinâmicos que transformam, manipulam ou processam os fluxos de dados.
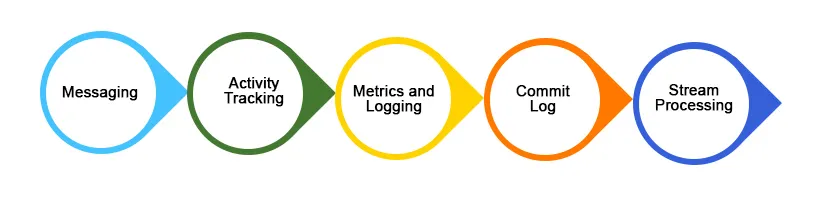
Casos de Uso
Abaixo estão alguns casos de uso amplamente implementados do aplicativo Kafka:
1. Mensagens
O Kafka funciona melhor do que outros sistemas de mensagens tradicionais, como ActiveMQ, RabbitMQ, etc. Em comparação, o Kafka oferece melhores taxas de transferência, facilidade de partição embutida, replicação e recursos de tolerância a falhas, o que o torna um sistema de mensagens melhor para aplicativos de processamento em larga escala. .
2. Rastreamento de atividade do site
As atividades do usuário (visualizações de página, pesquisas ou qualquer ação realizada) podem ser rastreadas e alimentadas para monitoramento ou análise em tempo real via Kafka ou usar o Kafka para armazenar esses tipos de dados no Hadoop ou no data warehouse para processamento ou manipulação posterior. O rastreamento de atividades gera uma enorme quantidade de dados que precisam ser transferidos para o local desejado sem nenhum tipo de perda de dados.
3. Agregação de Log
A agregação de log é um processo de coleta / mesclagem de arquivos de log físicos de diferentes servidores de um aplicativo em um único repositório (servidor de arquivos ou HDFS) para processamento. Kafka oferece bom desempenho, menor latência de ponta a ponta quando comparado ao Flume.

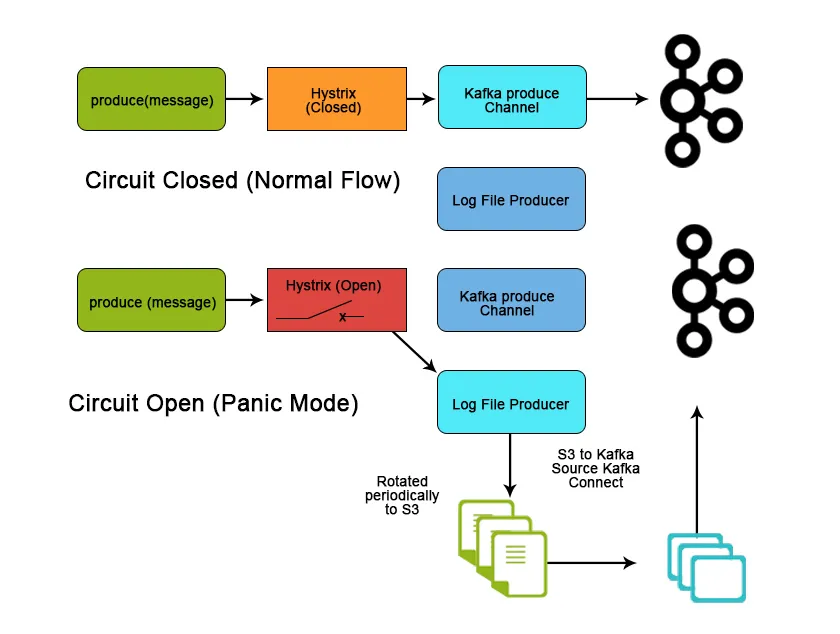
Conclusão
O Kafka é muito usado no espaço de big data como uma maneira de ingerir e mover grandes quantidades de dados muito rapidamente devido às suas características e recursos de desempenho que ajudam a alcançar escalabilidade, confiabilidade e sustentabilidade. Neste artigo, discutimos o Apache Kafka sobre seus recursos, casos de uso e aplicativo e o que o torna uma ferramenta melhor para o fluxo de dados.
Artigos recomendados
Este é um guia para aplicativos Kafka. Aqui discutimos o que é Kafka, juntamente com os principais aplicativos do Kafka, que incluem casos de uso amplamente implementados e alguma implementação na vida real. Você também pode consultar os seguintes artigos para saber mais:
- O que é Kafka?
- Como instalar o Kafka?
- Kafka Interview Questions
- Apache Kafka vs Flume
- Os 8 principais dispositivos da IoT que você deve conhecer
- Kafka vs Kinesis | Diferenças com infográficos
- Diferentes tipos de ferramentas Kafka com componentes
- Aprenda as principais diferenças de ActiveMQ vs Kafka