

Introdução ao algoritmo AdaBoost
O algoritmo AdaBoost pode ser usado para aumentar o desempenho de qualquer algoritmo de aprendizado de máquina. O Machine Learning se tornou uma ferramenta poderosa que pode fazer previsões com base em uma grande quantidade de dados. Tornou-se tão popular nos últimos tempos que a aplicação do aprendizado de máquina pode ser encontrada em nossas atividades diárias. Um exemplo comum disso é obter sugestões de produtos enquanto faz compras on-line com base nos itens anteriores comprados pelo cliente. O Machine Learning, geralmente chamado de análise preditiva ou modelagem preditiva, pode ser definido como a capacidade dos computadores aprenderem sem serem programados explicitamente. Ele usa algoritmos programados para analisar os dados de entrada e prever a saída dentro de um intervalo aceitável.
O que é o algoritmo AdaBoost?
No aprendizado de máquina, o impulso surgiu da questão de saber se um conjunto de classificadores fracos poderia ser convertido em um classificador forte. O aluno ou classificador fraco é um aluno que é melhor do que a adivinhação aleatória e isso será robusto em excesso de ajuste, como em um grande conjunto de classificadores fracos, sendo cada classificador fraco melhor que o aleatório. Como um classificador fraco, geralmente é usado um limite simples em um único recurso. Se o recurso estiver acima do limite que o previsto, ele pertence ao positivo, caso contrário, pertence ao negativo.
AdaBoost significa 'Adaptive Boosting', que transforma aprendizes ou preditores fracos em preditores fortes para resolver problemas de classificação.
Para classificação, a equação final pode ser apresentada como abaixo: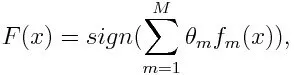
Aqui f m designa o mésimo classificador fraco e m representa seu peso correspondente.
Como o algoritmo AdaBoost funciona?
O AdaBoost pode ser usado para melhorar o desempenho dos algoritmos de aprendizado de máquina. É melhor usado com alunos fracos e esses modelos atingem alta precisão acima do acaso em um problema de classificação. Os algoritmos comuns com o AdaBoost usados são árvores de decisão com o nível um. Um aluno fraco é um classificador ou preditor que apresenta desempenho relativamente baixo em termos de precisão. Além disso, pode estar implícito que os alunos fracos são simples de calcular e muitas instâncias de algoritmos são combinadas para criar um classificador forte por meio do aumento.
Se pegarmos um conjunto de dados contendo n número de pontos e considerarmos o abaixo
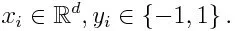
-1 representa classe negativa e 1 indica positivo. É inicializado como abaixo, o peso para cada ponto de dados como:
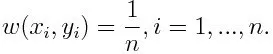
Se considerarmos a iteração de 1 a M para m, obteremos a expressão abaixo:
Primeiro, precisamos selecionar o classificador fraco com o menor erro de classificação ponderada, ajustando os classificadores fracos ao conjunto de dados.
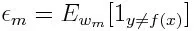
Em seguida, calcule o peso para o mésimo classificador fraco como abaixo:
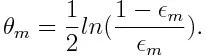
O peso é positivo para qualquer classificador com precisão superior a 50%. O peso se torna maior se o classificador for mais preciso e negativo se o classificador tiver precisão menor que 50%. A previsão pode ser combinada invertendo o sinal. Ao inverter o sinal da previsão, um classificador com uma precisão de 40% pode ser convertido em uma precisão de 60%. Portanto, o classificador contribui para a previsão final, mesmo que tenha um desempenho pior do que a adivinhação aleatória. No entanto, a previsão final não terá nenhuma contribuição ou obterá informações do classificador com precisão de 50%. O termo exponencial no numerador é sempre maior que 1 para um caso mal classificado do classificador ponderado positivo. Após a iteração, os casos mal classificados são atualizados com pesos maiores. Os classificadores ponderados negativos se comportam da mesma maneira. Mas há uma diferença que depois que o sinal é invertido; as classificações corretas originalmente seriam convertidas em erros de classificação. A previsão final pode ser calculada levando em consideração cada classificador e, em seguida, executando a soma da previsão ponderada.
Atualizando o peso para cada ponto de dados como abaixo:
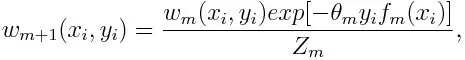
Z m é aqui o fator de normalização. Ele garante que a soma total de todos os pesos de instância se torne igual a 1.
Para que é utilizado o algoritmo AdaBoost?
O AdaBoost pode ser usado para detecção de rosto, pois parece ser o algoritmo padrão para detecção de rosto em imagens. Ele usa uma cascata de rejeição que consiste em muitas camadas de classificadores. Quando a janela de detecção não é reconhecida em nenhuma camada como uma face, ela é rejeitada. O primeiro classificador na janela descarta a janela negativa, mantendo o custo computacional no mínimo. Embora o AdaBoost combine os classificadores fracos, os princípios do AdaBoost também são usados para encontrar os melhores recursos a serem usados em cada camada da cascata.
Prós e contras do algoritmo AdaBoost
Uma das muitas vantagens do algoritmo AdaBoost é que é rápido, simples e fácil de programar. Além disso, possui flexibilidade para ser combinada com qualquer algoritmo de aprendizado de máquina e não há necessidade de ajustar os parâmetros, exceto T. Ele foi estendido para problemas de aprendizado além da classificação binária e é versátil, pois pode ser usado com texto ou numérico dados.
O AdaBoost também tem poucas desvantagens, como é o caso das evidências empíricas e particularmente vulnerável ao ruído uniforme. Classificadores fracos sendo muito fracos podem levar a margens baixas e superajustes.
Exemplo de algoritmo AdaBoost
Podemos considerar um exemplo de admissão de estudantes em uma universidade onde eles serão admitidos ou negados. Aqui os dados quantitativos e qualitativos podem ser encontrados sob diferentes aspectos. Por exemplo, o resultado da admissão que pode ser sim / não pode ser quantitativo, enquanto qualquer outra área, como habilidades ou hobbies dos alunos, pode ser qualitativa. Podemos chegar facilmente à classificação correta dos dados de treinamento, melhor do que a chance de condições como, por exemplo, se o aluno é bom em um determinado assunto, é admitido. Mas é difícil encontrar previsões altamente precisas e, em seguida, alunos fracos entram em cena.
Conclusão
O AdaBoost ajuda na escolha do conjunto de treinamento para cada novo classificador treinado com base nos resultados do classificador anterior. Também enquanto combina os resultados; determina quanto peso deve ser dado à resposta proposta de cada classificador. Ele combina os alunos fracos para criar um forte para corrigir erros de classificação, que também é o primeiro algoritmo de aumento bem-sucedido para problemas de classificação binária.
Artigos recomendados
Este foi um guia para o algoritmo AdaBoost. Aqui discutimos o conceito, usos, trabalho, prós e contras com o exemplo. Você também pode acessar nossos outros artigos sugeridos para saber mais -
- Algoritmo Naive Bayes
- Perguntas da entrevista sobre marketing de mídia social
- Estratégias de Link Building
- Plataforma de Marketing em Mídias Sociais