
Visão geral da modelagem de regressão linear
Quando você começa a aprender sobre algoritmos de aprendizado de máquina, começa a aprender sobre várias maneiras de algoritmos de ML, como aprendizado supervisionado, não supervisionado, semi-supervisionado e de reforço. Neste artigo, trataremos do aprendizado supervisionado e de um dos algoritmos básicos, porém poderosos: Regressão Linear.

Portanto, o aprendizado supervisionado é o aprendizado em que treinamos a máquina para entender o relacionamento entre os valores de entrada e saída fornecidos no conjunto de dados de treinamento e, em seguida, usamos o mesmo modelo para prever os valores de saída para o conjunto de dados de teste. Portanto, basicamente, se já temos a saída ou a rotulagem fornecida em nosso conjunto de dados de treinamento e temos certeza de que a saída fornecida faz sentido correspondente à entrada, usamos o Aprendizado Supervisionado. Os algoritmos de aprendizado supervisionado são classificados em Regressão e Classificação.
Os algoritmos de regressão são usados quando você percebe que a saída é uma variável contínua, enquanto os algoritmos de classificação são usados quando a saída é dividida em seções como Aprovado / Reprovado, Bom / Médio / Ruim, etc. Temos vários algoritmos para executar a regressão ou classificação ações com o algoritmo de regressão linear sendo o algoritmo básico em regressão.
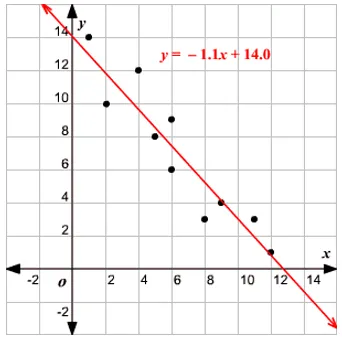
Chegando a essa regressão, antes de entrar no algoritmo, deixe-me definir a base para você. Na escola, espero que você se lembre do conceito de equação de linha. Deixe-me falar um pouco sobre isso. Você recebeu dois pontos no plano XY, ou seja, (x1, y1) e (x2, y2), onde y1 é a saída de x1 e y2 é a saída de x2, então a equação da linha que passa pelos pontos é (y- y1) = m (x-x1) onde m é a inclinação da reta. Agora, depois de encontrar a equação da linha, se você receber um ponto, digamos (x3, y3), poderá facilmente prever se o ponto está na linha ou a distância do ponto da linha. Essa foi a regressão básica que eu havia feito na escola sem perceber que isso teria uma importância tão grande no Machine Learning. O que geralmente fazemos nisso é tentar identificar a linha ou curva da equação que possa ajustar a entrada e a saída do conjunto de dados do trem corretamente e, em seguida, usar a mesma equação para prever o valor de saída do conjunto de dados de teste. Isso resultaria em um valor desejado contínuo.
Definição de regressão linear
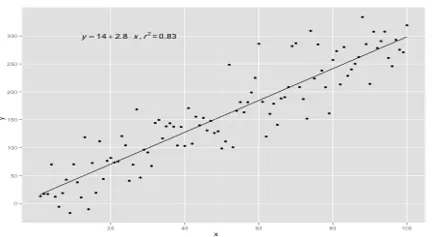
A regressão linear já existe há muito tempo (cerca de 200 anos). É um modelo linear, isto é, assume uma relação linear entre as variáveis de entrada (x) e uma única variável de saída (y). Oy aqui é calculado pela combinação linear das variáveis de entrada.
Temos dois tipos de regressão linear
Regressão linear simples
Quando existe uma única variável de entrada, ou seja, a equação da linha é c
considerado como y = mx + c, então é regressão linear simples.
Regressão linear múltipla
Quando existem múltiplas variáveis de entrada, isto é, a equação da linha é considerada como y = ax 1 + bx 2 +… nx n, então é regressão linear múltipla. Várias técnicas são utilizadas para preparar ou treinar a equação de regressão a partir dos dados, e a mais comum dentre elas é denominada Mínimos Quadrados Ordinários. O modelo criado usando o método mencionado é chamado de regressão linear de mínimos quadrados ordinários ou apenas regressão de mínimos quadrados. O modelo é usado quando os valores de entrada e o valor de saída a serem determinados são valores numéricos. Quando houver apenas uma entrada e uma saída, a equação formada é uma equação de linha, ou seja
y = B0x+B1
onde os coeficientes da linha devem ser determinados usando métodos estatísticos.
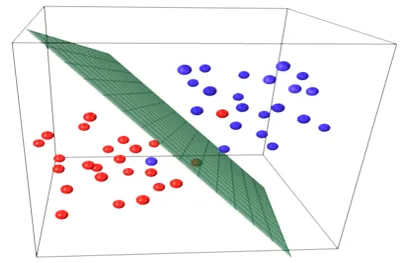
Modelos de regressão linear simples são muito raros no ML, porque geralmente teremos vários fatores de entrada para determinar o resultado. Quando existem vários valores de entrada e um valor de saída, a equação formada é a de um plano ou hiperplano.
y = ax 1 +bx 2 +…nx n
A idéia central no modelo de regressão é obter uma equação de linha que melhor se ajuste aos dados. A melhor linha de ajuste é aquela em que o erro de previsão total para todos os pontos de dados considerados o menor possível. O erro é a distância entre o ponto no plano e a linha de regressão.
Exemplo
Vamos começar com um exemplo de regressão linear simples.

A relação entre a altura e o peso de uma pessoa é diretamente proporcional. Um estudo foi realizado com os voluntários para determinar a altura e o peso ideal da pessoa e os valores foram registrados. Isso será considerado como nosso conjunto de dados de treinamento. Usando os dados de treinamento, é calculada uma equação de linha de regressão que fornecerá um erro mínimo. Essa equação linear é usada para fazer previsões em novos dados. Ou seja, se dermos a altura da pessoa, o peso correspondente deve ser previsto pelo modelo desenvolvido por nós com erro mínimo ou zero.
Y(pred) = b0 + b1*x
Os valores b0 e b1 devem ser escolhidos para minimizar o erro. Se a soma do erro quadrático for tomada como uma métrica para avaliar o modelo, o objetivo é obter uma linha que melhor reduz o erro.
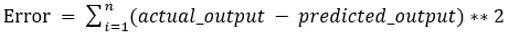
Estamos corrigindo o erro para que valores positivos e negativos não se cancelem. Para modelo com um preditor:
O cálculo da interceptação (b0) na equação da linha é feito por:
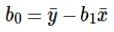
O cálculo do coeficiente para o valor de entrada x é feito por:
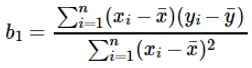
Entendendo o coeficiente b 1 :
- Se b 1 > 0, x (entrada) e y (saída) são diretamente proporcionais. Ou seja, um aumento em x aumentará y, como aumentos de altura e de peso.
- Se b 1 <0, x (preditor) e y (alvo) são inversamente proporcionais. Ou seja, um aumento em x diminuirá y, como a velocidade de um veículo, o tempo gasto diminui.
Entendendo o coeficiente b 0 :
- B 0 assume o valor residual do modelo e garante que a previsão não seja tendenciosa. Se não tivermos o termo B 0, a equação da linha (y = B 1 x) é forçada a passar pela origem, ou seja, os valores de entrada e saída colocados no modelo resultam em 0. Mas isso nunca será o caso, se tivermos 0 na entrada, então B 0 será a média de todos os valores previstos quando x = 0. Definir todos os valores do preditor como 0 no caso de x = 0 resultará em perda de dados e geralmente é impossível.
Além dos coeficientes mencionados acima, este modelo também pode ser calculado usando equações normais. Discutirei ainda mais o uso de equações normais e projetarei um modelo de regressão simples / multilinear no meu próximo artigo.
Artigos recomendados
Este é um guia para modelagem de regressão linear. Aqui discutimos a definição, tipos de regressão linear, que inclui regressão linear simples e múltipla, juntamente com alguns exemplos. Você também pode consultar os seguintes artigos para saber mais:
- Regressão linear em R
- Regressão linear no Excel
- Modelagem Preditiva
- Como criar GLM em R?
- Comparação entre regressão linear e regressão logística