

Introdução à análise de regressão linear
Muitas vezes é confuso aprender algum conceito que faz parte do nosso dia a dia. Mas isso não é um problema, podemos ajudar e nos desenvolver para aprender com nossas atividades diárias apenas analisando as coisas e não sentimos medo de fazer perguntas. Por que o preço afeta a demanda pelos bens, por que a mudança na taxa de juros afeta a oferta de moeda. Tudo isso pode ser respondido por uma abordagem simples, conhecida como regressão linear. A única complexidade que se sente ao lidar com a análise de regressão linear é a identificação de variáveis dependentes e independentes.
Temos que descobrir o que afeta o quê e metade do problema está resolvido. Temos que ver se é o preço ou a demanda que afeta o comportamento um do outro. Assim que descobrimos qual é a variável independente e a variável dependente, é bom analisarmos a questão. Existem vários tipos de análise de regressão disponíveis. Essa análise depende das variáveis disponíveis para nós.
Os 3 tipos de análise de regressão
Essas três análises de regressão têm casos de uso máximos no mundo real, caso contrário, existem mais de 15 tipos de análise de regressão. Os tipos de análise de regressão que vamos discutir são:
- Análise de regressão linear
- Análise de regressão linear múltipla
- Regressão logística
Neste artigo, focaremos na análise de regressão linear simples. Essa análise nos ajuda a identificar a relação entre o fator independente e o fator dependente. Em palavras mais simples, o modelo de regressão nos ajuda a descobrir como as mudanças no fator independente afetam o fator dependente. Esse modelo nos ajuda de várias maneiras, como:
- É um modelo estatístico simples e poderoso
- Isso nos ajudará a fazer previsões e previsões
- Isso nos ajudará a tomar uma melhor decisão comercial
- Isso nos ajudará a analisar os resultados e corrigir erros
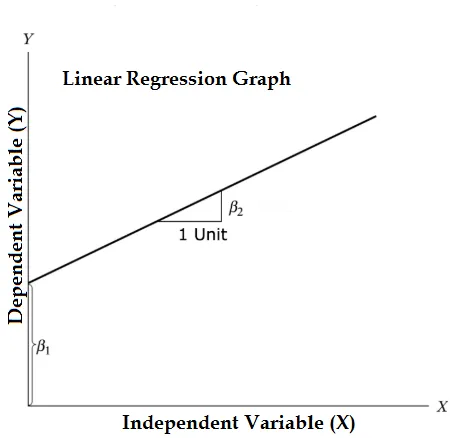
A equação da regressão linear e dividi-la em partes relevantes
Y = β1 + β2X + ϵ
- Onde β1 na terminologia matemática conhecida como interceptação e β2 na terminologia matemática conhecida como inclinação. Eles também são conhecidos como coeficientes de regressão. ϵ é o termo do erro, é a parte de Y que o modelo de regressão não consegue explicar.
- Y é uma variável dependente (outros termos que são usados de maneira intercambiável para variáveis dependentes são variável de resposta, regressão, variável medida, variável observada, variável de resposta, variável explicada, variável explicada, variável de resultado, variável experimental e / ou variável de saída).
- X é uma variável independente (regressores, variável controlada, manipulada uma variável, variável explicativa, variável de exposição e / ou variável de entrada).
Problema: Para entender o que é a análise de regressão linear, estamos usando o conjunto de dados "Carros", que vem por padrão nos diretórios R. Neste conjunto de dados, há 50 observações (basicamente linhas) e 2 variáveis (colunas). Os nomes das colunas são "Dist" e "Speed". Aqui temos que ver o impacto nas variáveis de distância devido à mudança das variáveis de velocidade. Para ver a estrutura dos dados, podemos executar um código Str (conjunto de dados). Esse código nos ajuda a entender a estrutura do conjunto de dados. Essas funcionalidades nos ajudam a tomar melhores decisões, porque temos uma imagem melhor em mente sobre a estrutura do conjunto de dados. Este código nos ajuda a identificar o tipo de conjuntos de dados.
Código:

Da mesma forma, para verificar os pontos de verificação das estatísticas do conjunto de dados, podemos usar o código Resumo (carros). Este Código fornece a média, mediana e faixa do conjunto de dados de uma só vez, que o pesquisador pode usar ao lidar com o problema.
Resultado:
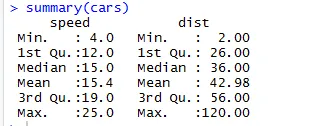
Aqui podemos ver a saída estatística de todas as variáveis que temos em nosso conjunto de dados.
A representação gráfica de conjuntos de dados
Os tipos de representação gráfica que serão abordados aqui são e por que:
- Gráfico de dispersão: Com a ajuda do gráfico, podemos ver em qual direção nosso modelo de regressão linear está indo, se há alguma evidência forte para provar ou não o nosso modelo.
- Box Plot: ajuda-nos a encontrar discrepâncias.
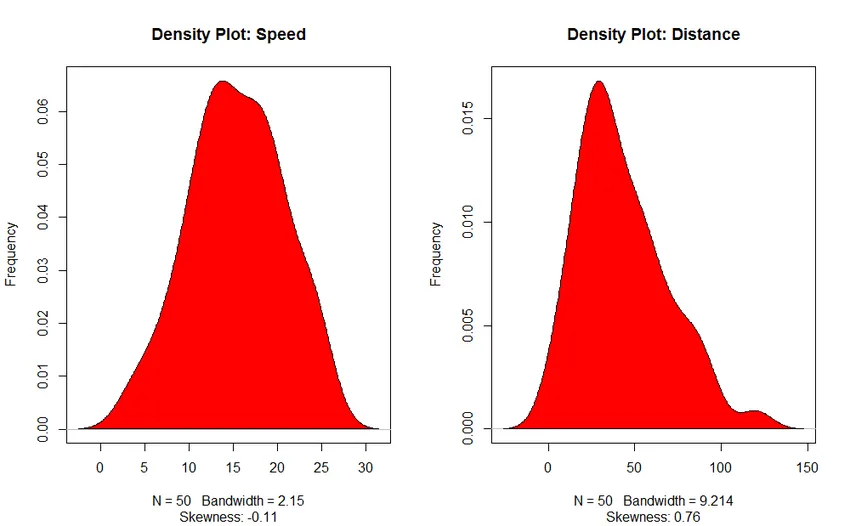
- Gráfico de densidade: Ajude-nos a entender a distribuição da variável independente. No nosso caso, a variável independente é "Velocidade".
Vantagens da representação gráfica
Aqui, as seguintes vantagens são as seguintes:
- Fácil de entender
- Ajuda-nos a tomar decisões rápidas
- Análise comparativa
- Menos esforço e tempo
1. Gráfico de Dispersão: Ajudará a visualizar quaisquer relações entre a variável independente e a variável dependente.
Código:

Resultado:
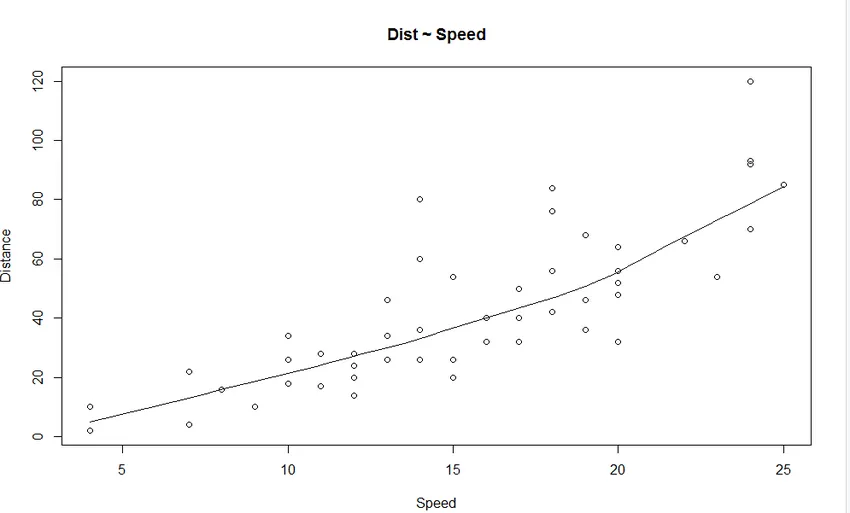
Podemos ver no gráfico uma relação linearmente crescente entre a variável dependente (Distância) e a variável independente (Velocidade).
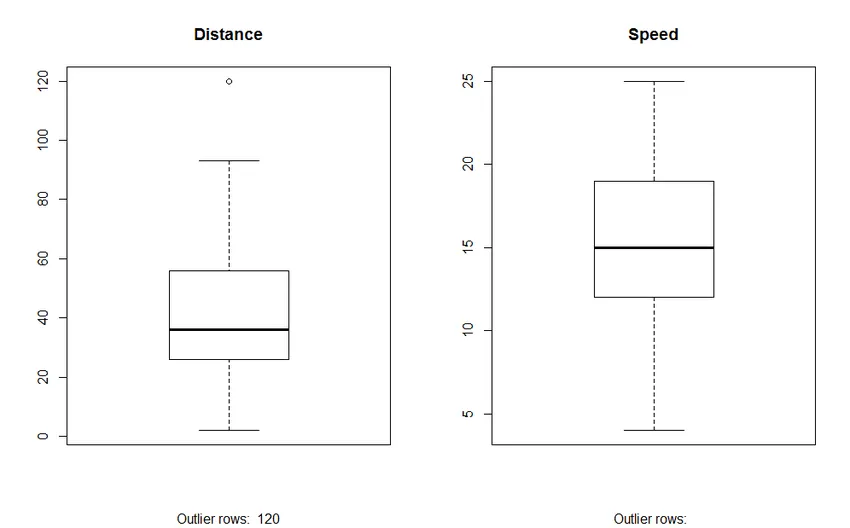
2. Gráfico de caixas: O gráfico de caixas nos ajuda a identificar os valores discrepantes nos conjuntos de dados. As vantagens de usar um gráfico de caixa são:
- Exibição gráfica das variáveis localização e spread.
- Isso nos ajuda a entender a assimetria e simetria dos dados.
Código:

Resultado:
3. Gráfico de Densidade (para verificar a normalidade da distribuição)
Código:
 Resultado:
Resultado:
Análise de correlação
Essa análise nos ajuda a encontrar o relacionamento entre as variáveis. Existem principalmente seis tipos de análise de correlação.
- Correlação positiva (0, 01 a 0, 99)
- Correlação negativa (-0, 99 a -0, 01)
- Nenhuma correlação
- Correlação perfeita
- Correlação forte (valor próximo de ± 0, 99)
- Correlação fraca (um valor mais próximo de 0)
O gráfico de dispersão nos ajuda a identificar quais tipos de conjuntos de dados de correlação têm entre eles e o código para encontrar a correlação é

Resultado:
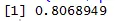
Aqui temos uma forte correlação positiva entre velocidade e distância, o que significa que eles têm uma relação direta entre eles.
Modelo de Regressão Linear
Esse é o componente principal da análise; antes estávamos apenas tentando e testando as coisas, se o conjunto de dados que possuímos é lógico o suficiente para executar ou não essa análise. A função que estamos planejando usar é lm (). Esta função contém dois elementos que são Fórmula e Dados. Antes de atribuir qual variável é dependente ou independente, precisamos ter muita certeza disso, porque toda a nossa fórmula depende disso.
A fórmula fica assim,
Regressão linear <- lm (variável dependente ~ variável independente, data = Date.Frame)
Código:

Resultado:
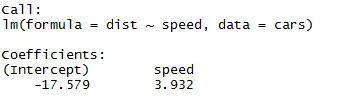
Como podemos lembrar do segmento acima do artigo, a equação da regressão linear é:
Y = β1 + β2X + ϵ
Agora vamos nos encaixar nas informações que obtivemos do código acima nesta equação.
dist = −17.579 + 3.932 ∗ velocidade
Apenas encontrar a equação da regressão linear não é suficiente, temos que verificar também sua estatística significativa. Para isso, precisamos passar um código "Resumo" em nosso modelo de regressão linear.
Código:

Resultado:

Existem várias maneiras de verificar a estatística significativa de um modelo, aqui estamos usando o método do valor-P. Podemos considerar um modelo estatisticamente adequado quando o valor de P for menor que o nível de significância estatística pré-determinado, idealmente 0, 05. Podemos ver em nossa tabela de resumo (regressão_ linear) que o valor P está abaixo do nível 0, 05, para que possamos concluir que nosso modelo é estatisticamente significativo. Quando tivermos certeza do nosso modelo, podemos usar nosso conjunto de dados para prever as coisas.
Artigos recomendados
Este é um guia para a Análise de regressão linear. Aqui discutimos os três tipos de análise de regressão linear, a representação gráfica de conjuntos de dados com vantagens e modelos de regressão linear. Você também pode consultar nossos outros artigos relacionados para saber mais.
- Fórmula de regressão
- Teste de regressão
- Regressão linear em R
- Tipos de técnicas de análise de dados
- O que é análise de regressão?
- Principais diferenças entre regressão e classificação
- As 6 principais diferenças entre regressão linear e regressão logística