
Introdução à Regressão de Poisson em R
A regressão de Poisson é um tipo de regressão semelhante à regressão linear múltipla, exceto que a resposta ou a variável dependente (Y) é uma variável de contagem. A variável dependente segue a distribuição de Poisson. O preditor ou variáveis independentes podem ser de natureza contínua ou categórica. De certa forma, é semelhante à Regressão Logística, que também possui uma variável de resposta discreta. O entendimento prévio da distribuição de Poisson e sua forma matemática é muito essencial para alavancá-la para a previsão. Em R, a regressão de Poisson pode ser implementada de uma maneira muito eficaz. O R oferece um conjunto abrangente de funcionalidades para sua implementação.
Implementando a regressão de Poisson
Agora, vamos entender como o modelo é aplicado. A seção a seguir fornece um procedimento passo a passo para o mesmo. Para esta demonstração, estamos considerando o conjunto de dados "gala" do pacote "faraway". Diz respeito à diversidade de espécies nas Ilhas Galápagos. Existem sete variáveis no conjunto de dados. Usaremos a regressão de Poisson para definir uma relação entre o número de espécies de plantas (Espécies) com outras variáveis no conjunto de dados.
1. Primeiro carregue a embalagem “distante”. Caso o pacote não esteja presente, faça o download usando a função install.packages ().
2. Depois que o pacote for carregado, carregue o conjunto de dados "gala" no R usando a função data () como mostrado abaixo.
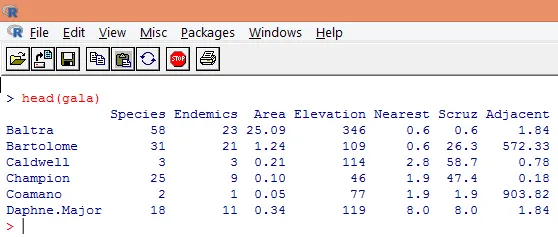
3. Os dados carregados devem ser visualizados para estudar a variável e verificar se há alguma discrepância. Podemos visualizar os dados completos ou apenas as primeiras linhas usando a função head (), como mostrado na captura de tela abaixo.
4. Para obter mais informações sobre o conjunto de dados, podemos usar a funcionalidade de ajuda em R, como abaixo. Ele gera a documentação do R, conforme mostrado na captura de tela subsequente à captura de tela abaixo.


5. Se estudarmos o conjunto de dados conforme mencionado nas etapas anteriores, podemos descobrir que Espécie é uma variável de resposta. Vamos agora estudar um resumo básico das variáveis preditivas.
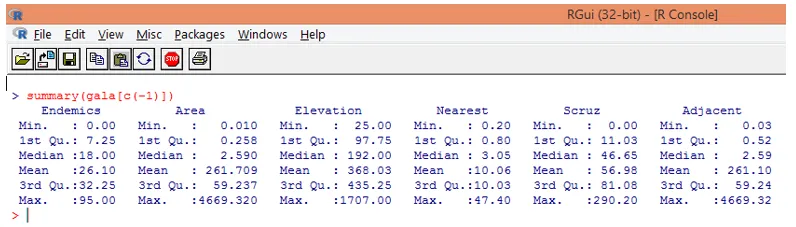
Observe que, como pode ser visto acima, excluímos a variável Species. A função de resumo fornece informações básicas. Apenas observe os valores medianos para cada uma dessas variáveis, e podemos descobrir que existe uma enorme diferença, em termos da faixa de valores, entre a primeira metade e a segunda metade, por exemplo, para o valor mediano da variável Area é 2, 59, mas o máximo o valor é 4669.320.
6. Agora que terminamos a análise básica, geraremos um histograma para Espécies, a fim de verificar se a variável segue a distribuição de Poisson. Isso é ilustrado abaixo.

O código acima gera um histograma para a variável Species, juntamente com uma curva de densidade sobreposta.
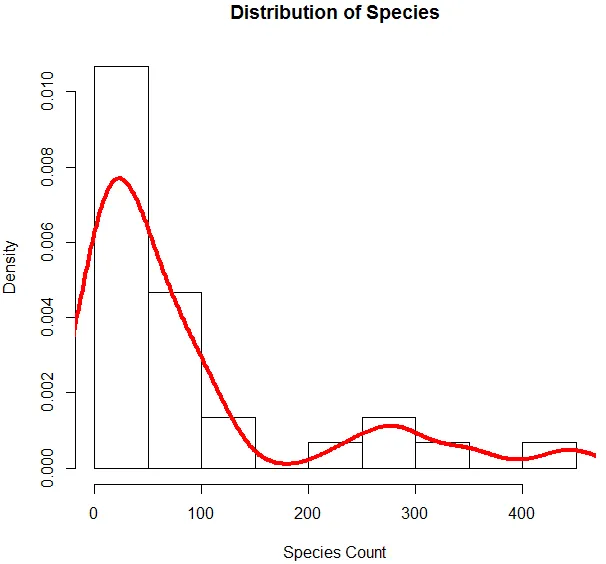
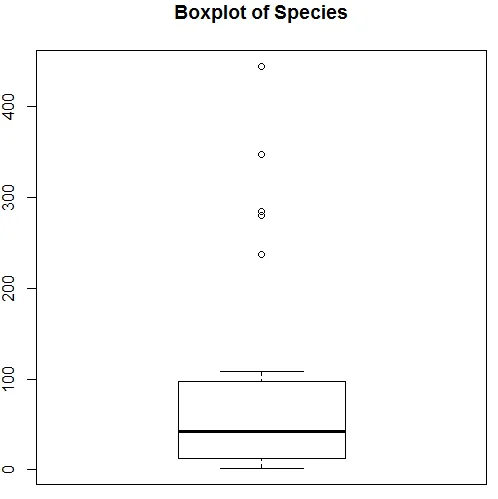
A visualização acima mostra que o Species segue uma distribuição de Poisson, pois os dados estão no sentido correto. Também podemos gerar um boxplot, para obter mais informações sobre o padrão de distribuição, como mostrado abaixo.
7. Após concluir a análise preliminar, aplicaremos agora a regressão de Poisson, como mostrado abaixo
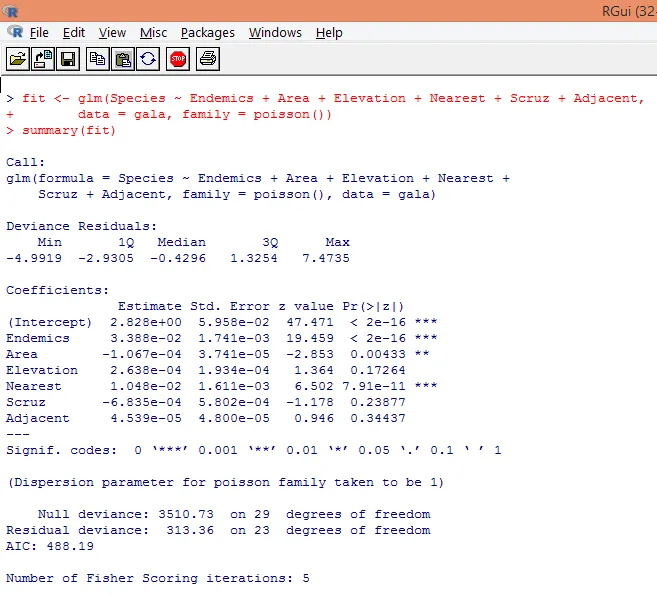
Com base na análise acima, descobrimos que as variáveis Endêmicas, Área e Mais Próxima são significativas e apenas sua inclusão é suficiente para construir o modelo de regressão de Poisson correto.
8. Construiremos um modelo de regressão de Poisson modificado, levando em consideração três variáveis apenas viz. Endemias, Área e Mais Próxima. Vamos ver quais resultados obtemos.
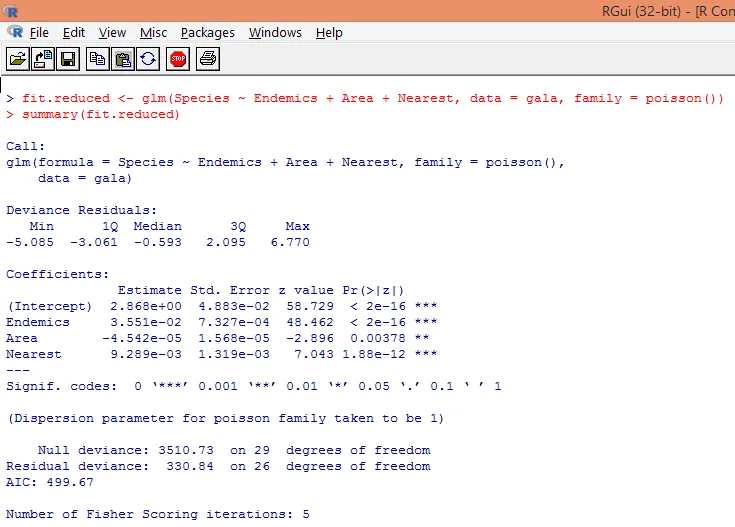
A saída produz desvios, parâmetros de regressão e erros padrão. Podemos ver que cada um dos parâmetros é significativo no nível p <0, 05.
9. O próximo passo é interpretar os parâmetros do modelo. Os coeficientes do modelo podem ser obtidos examinando os coeficientes na saída acima ou usando a função coef ().
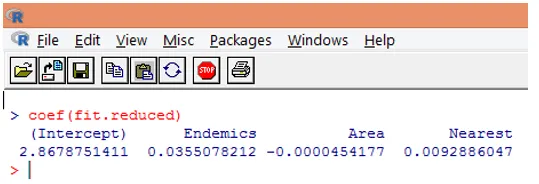
Na regressão de Poisson, a variável dependente é modelada como o log do loge médio condicional (l). O parâmetro de regressão de 0, 0355 para Endêmicas indica que um aumento de uma unidade na variável está associado a um aumento de 0, 04 no número médio logarítmico de Espécies, mantendo outras variáveis constantes. A interceptação é um número médio de log de espécies quando cada um dos preditores é igual a zero.
10. No entanto, é muito mais fácil interpretar os coeficientes de regressão na escala original da variável dependente (número de espécies, em vez do número de log de espécies). A exponenciação dos coeficientes permitirá uma interpretação fácil. Isto se faz do seguinte modo.
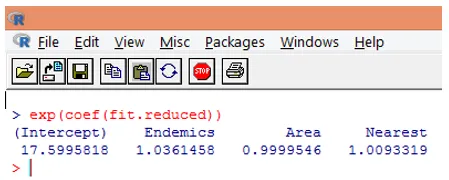
A partir das descobertas acima, podemos dizer que um aumento unitário em Área multiplica o número esperado de espécies por 0, 9999 e um aumento unitário no número de espécies endêmicas representadas por Endêmicas multiplica o número de espécies por 1, 0361. O aspecto mais importante da regressão de Poisson é que os parâmetros exponenciados têm um efeito multiplicativo em vez de aditivo na variável resposta.
11. Usando as etapas acima, obtivemos um modelo de regressão de Poisson para prever o número de espécies de plantas nas Ilhas Galápagos. No entanto, é muito importante verificar se há sobredispersão. Na regressão de Poisson, a variância e as médias são iguais.
A superdispersão ocorre quando a variância observada da variável resposta é maior do que seria previsto pela distribuição de Poisson. A análise de superdispersão se torna importante, pois é comum nos dados da contagem e pode afetar negativamente os resultados finais. Em R, a sobredispersão pode ser analisada usando o pacote "qcc". A análise é ilustrada abaixo.
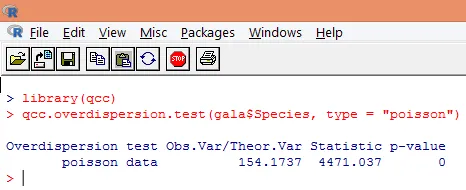
O teste significativo acima mostra que o valor de p é menor que 0, 05, o que sugere fortemente a presença de super-dispersão. Vamos tentar ajustar um modelo usando a função glm (), substituindo family = "Poisson" por family = "quasipoisson". Isso é ilustrado abaixo.
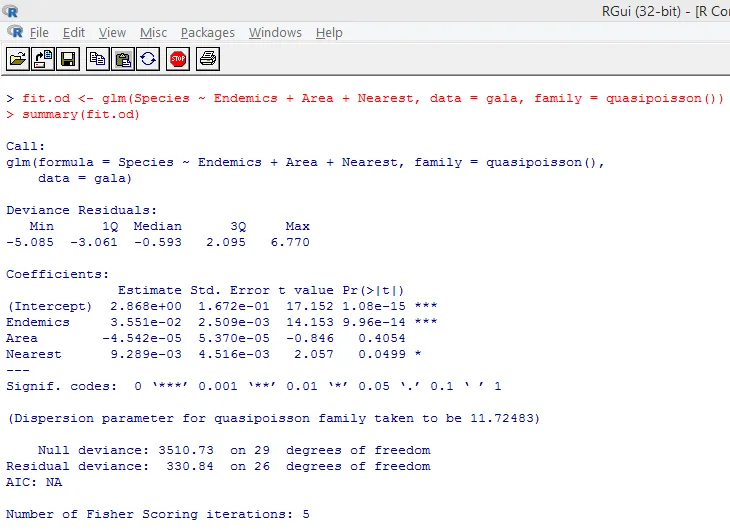
Estudando de perto a saída acima, podemos ver que as estimativas de parâmetros na abordagem quase-Poisson são idênticas às produzidas pela abordagem de Poisson, embora os erros padrão sejam diferentes para ambas as abordagens. Além disso, neste caso, para Área, o valor de p é maior que 0, 05, devido a um erro padrão maior.
Importância da regressão de Poisson
- A regressão de Poisson em R é útil para previsões corretas da variável discreta / contagem.
- Isso nos ajuda a identificar as variáveis explicativas que têm um efeito estatisticamente significativo na variável resposta.
- A regressão de Poisson em R é mais adequada para eventos de natureza "rara", pois eles tendem a seguir uma distribuição de Poisson em comparação com eventos comuns que geralmente seguem uma distribuição normal.
- É adequado para aplicação nos casos em que a variável de resposta é um número inteiro pequeno.
- Possui amplas aplicações, pois a previsão de variáveis discretas é crucial em muitas situações. Na medicina, pode ser usado para prever o impacto do medicamento na saúde. É muito usado em análises de sobrevivência, como a morte de organismos biológicos, falha de sistemas mecânicos, etc.
Conclusão
A regressão de Poisson é baseada no conceito de distribuição de Poisson. É outra categoria pertencente ao conjunto de técnicas de regressão que combina as propriedades das regressões linear e logística. No entanto, diferentemente da regressão logística, que gera apenas saída binária, ela é usada para prever uma variável discreta.
Artigos recomendados
Este é um guia para a Regressão de Poisson em R. Aqui discutimos a introdução Implementando a Regressão de Poisson e a Importância da Regressão de Poisson. Você também pode consultar nossos outros artigos sugeridos para saber mais:
- GLM em R
- Gerador de número aleatório em R
- Fórmula de regressão
- Regressão logística em R
- Regressão linear vs regressão logística | Principais diferenças