

Introdução ao Python Pandas DataFrame
Várias expansões para a Biblioteca Python, Pandas, podem ser encontradas online. Um deles é o Painel (pan) Dados (das). Esta palavra, * Panel *, sugere sutilmente uma estrutura de dados bidimensional presente nesta biblioteca, capacitando imensamente seus usuários. Essa estrutura é chamada de DataFrame.
É essencialmente uma matriz de linhas e colunas, contendo todo o conjunto de dados, com opções muito elaboradas de indexação do mesmo. O DataFrame (DF) pode ser imaginado pictoricamente muito semelhante a uma planilha do Excel. Mas o que o torna poderoso é a facilidade com que as operações analíticas e transformacionais podem ser executadas nos dados armazenados em um DataFrame.
O que exatamente é um DataFrame do Python Pandas?
A página Pydata pode ser consultada para uma definição oficial.
Se entendido corretamente, ele menciona o DataFrame como uma estrutura colunar, capaz de armazenar qualquer objeto python (incluindo o próprio DataFrame) como um valor de célula. (Uma célula é indexada usando uma combinação única de linha e coluna)
DataFrames consiste em três componentes essenciais: dados, linhas e colunas.
- Dados: refere-se aos objetos / entidades reais armazenados em uma célula no DataFrame e aos valores representados por essas entidades. Um objeto é de qualquer tipo de dados python válido, incorporado ou definido pelo usuário.
- Linhas: as referências usadas para identificar (ou indexar) um conjunto específico de observações dos dados completos armazenados em um DataFrame são chamadas de Linhas. Apenas para deixar claro, ele representa os índices usados e não apenas os dados em uma observação específica.
- Colunas: referências usadas para identificar (ou indexar) um conjunto de atributos para todas as observações em um DataFrame. Como no caso de linhas, elas se referem ao índice da coluna (ou aos cabeçalhos da coluna), em vez de apenas aos dados da coluna.
Portanto, sem mais delongas, vamos tentar algumas maneiras de criar essas estruturas incrivelmente poderosas.
Etapas para criar DataFrames do Python Pandas
Um DataFrame do Python Pandas pode ser criado usando a seguinte implementação de código,
1. Importar pandas
Para criar DataFrames, a biblioteca do pandas precisa ser importada (sem surpresa aqui). Vamos importá-lo com um pseudônimo para referenciar objetos no módulo convenientemente.
Código:
import pandas as pd
2. Criando o primeiro objeto DataFrame
Depois que a biblioteca é importada, todos os métodos, funções e construtores ficam disponíveis no seu espaço de trabalho. Então, vamos tentar criar um DataFrame de baunilha.
Código:
import pandas as pd
df = pd.DataFrame()
print(df)
Resultado:
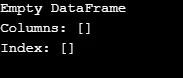
Como mostrado na saída, o construtor retorna um DataFrame vazio.
Vamos agora focar na criação de DataFrames a partir de dados armazenados em algumas das representações prováveis.
- DataFrame de um dicionário: digamos que temos um dicionário que armazena uma lista de empresas no domínio de software e o número de anos em que elas estão ativas.
Código:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Vamos ver a representação do objeto DataFrame retornado, imprimindo-o no console.
Resultado:

Como pode ser visto, cada chave do dicionário é tratada como uma coluna no DataFrame, e os índices de linha são gerados automaticamente a partir de 0. Muito fácil, hein!
Agora, digamos que você queira atribuir um índice personalizado em vez de 0, 1, .. 4. Você só precisa passar a lista desejada como parâmetro para o construtor e os pandas farão o necessário.
Código:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Resultado:
Idade da empresa
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Agora você pode definir os índices de linha para qualquer valor desejado.
- DataFrame de um arquivo CSV: vamos criar um arquivo CSV contendo os mesmos dados que no caso do nosso dicionário. Vamos chamar o arquivo CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
O arquivo pode ser carregado em um quadro de dados (supondo que ele esteja presente no diretório de trabalho atual) da seguinte maneira.
Código:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Resultado:
Idade da empresa
0 Google 21
1 Amazônia 23
2 Infosys 38
3 Diretório 22
Definir os nomes dos parâmetros , ignorando uma lista de valores, os atribui como cabeçalhos de coluna na mesma ordem em que estão presentes na lista. Da mesma forma, os índices de linha podem ser configurados passando uma lista para o parâmetro index, como mostrado na seção anterior. O cabeçalho = Nenhum indica os cabeçalhos de coluna ausentes no arquivo de dados.
Agora, digamos que os nomes das colunas faziam parte do arquivo de dados. A configuração do cabeçalho = False fará o trabalho necessário.
3. CompanyAgeWithHeader.csv
Empresa, Idade
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
O código mudará para
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Resultado:
Idade da empresa
0 Google 21
1 Amazônia 23
2 Infosys 38
3 Diretório 22
- DataFrame de um arquivo do Excel: geralmente os dados são compartilhados em arquivos do Excel, pois continuam sendo a ferramenta mais popular usada por pessoas comuns para rastreamento Adhoc. Portanto, não deve ser ignorado por nossa discussão.
Vamos supor que os dados, assim como em CompanyAgeWithHeader.csv, agora estão armazenados em CompanyAgeWithHeader.xlsx, em uma planilha com o nome Company Age. O mesmo DataFrame como acima será criado pelo código a seguir.
Código:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Resultado:
Idade da empresa
0 Google 21
1 Amazônia 23
2 Infosys 38
3 Diretório 22
Como você pode ver, o mesmo DataFrame pode ser criado passando o nome do arquivo e o nome da planilha.
Leitura adicional e próximas etapas
Os métodos mostrados constituem um subconjunto muito pequeno em comparação com todas as diferentes formas de criação de DataFrames. Estes foram criados com a intenção de iniciar um. Você definitivamente deve explorar as referências listadas e tentar explorar outras maneiras, incluindo conectar-se a um banco de dados para ler dados diretamente em um DataFrame.
Conclusão
O Pandas DataFrame provou ser um divisor de águas no mundo da Data Science e Data Analytics, além de ser conveniente para projetos ad-hoc de curto prazo. Ele vem com um exército de ferramentas capazes de cortar e cortar os dados com extrema facilidade. Felizmente, isso servirá como um trampolim em sua jornada à frente.
Artigos recomendados
Este é um guia para o DataFrame do Python-Pandas. Aqui discutimos as etapas para criar o quadro de dados python-pandas junto com sua implementação de código. Você também pode consultar os seguintes artigos para saber mais -
- Os 15 principais recursos do Python
- Diferentes tipos de conjuntos de Python
- Os 4 principais tipos de variáveis em Python
- Os 6 principais editores do Python
- Matrizes na estrutura de dados