

Como instalar o Apache
Antes de digitar como instalar a parte do Apache, primeiro teríamos uma visão geral do Apache e como ele é usado na ciência de dados.
O que é o Apache?

O Apache Web Server é um servidor HTTP que apresenta sites para visitantes que chegam ao seu servidor. Portanto, se você deseja implantar um site para uma empresa ou organização, provavelmente usará o Apache para isso.
Existem outros servidores HTTP por aí, como o IIS, mas o Apache é o padrão usado pela maioria das pessoas, seja no Linux, Windows ou Mac. O Apache é o padrão que a maioria das pessoas acessa porque é bem conhecido, é muito confiável e é gratuito.
No entanto, uma coisa a ser percebida com o Apache é que, como é um servidor HTTP, se você instalá-lo no Linux ou Windows ou Mac, tudo o que você pode fazer é apresentar sites estáticos aos visitantes que chegam ao seu servidor. Portanto, se você codificar um site em HTML sem outras linguagens de programação além do JavaScript, poderá usá-lo com apenas um servidor Apache. Você pode conectar todas as suas tags ao servidor Apache e apresentá-las aos seus visitantes.
Como o Apache usou na Data Science?
A ciência de dados é o campo de estudo mais procurado no mundo moderno. O Data Scientist é considerado o trabalho mais sexy do século 21, com profissionais de várias disciplinas que desejam aprender e se tornar um Data Scientist. O Apache desempenha um papel crucial em qualquer entusiasta da ciência de dados, pois eles precisam de conhecimento suficiente do ecossistema Apache Hadoop.
Ecossistema Apache Hadoop
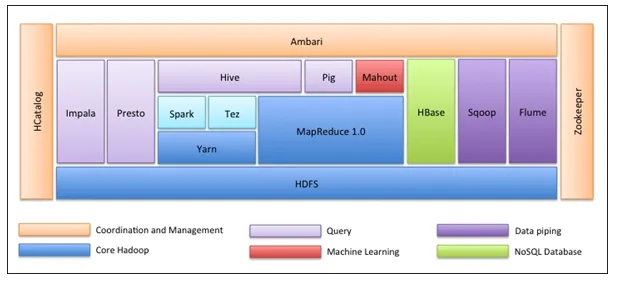
A primeira coisa é que o ecossistema Hadoop não é uma ferramenta. Não é uma linguagem de programação ou uma estrutura única. É um grupo de ferramentas que são usadas juntas por várias empresas em domínios diferentes para várias tarefas. Analisaremos cada ferramenta uma a uma abaixo: -
- O Apache HDFS (Sistema de Arquivos Distribuídos Hadoop) é a unidade de armazenamento do Hadoop que pode armazenar dados estruturados, semiestruturados e não estruturados. O HDFS possui metadados que mantêm o arquivo de log sobre os dados armazenados. Possui dois componentes - NameNode e DataNode.
- O Apache Yarn é o negociador de recursos que executa todas as atividades de processamento, como agendamento de tarefas, alocação de recursos etc. Ele possui dois serviços - Primeiro é o Gerenciador de Recursos que agenda os aplicativos em execução no Yarn. O segundo é o gerenciador de nós, que monitora a utilização de recursos .
- O Apache Map Reduce é o componente de processamento de dados do Hadoop que processa grandes conjuntos de dados usando computação distribuída e paralela com base nas funções Map, Sort and Shuffle e Reduce. A função de mapa filtra os dados e, em seguida, a classificação e a reprodução aleatória são feitas. No final, a função Reduzir agrega e resume o resultado.
- O Apache Pig é usado principalmente em ETL. Ele tem duas partes - Pig Latin e o tempo de execução do Pig. O Pig Latin é o idioma usado para o processamento de dados usando uma consulta, enquanto o Pig runtime é o ambiente de execução. Uma linha do Pig Latin é quase igual a 100 linhas do código Map Reduce. O processo envolve primeiro carregar os dados e, em seguida, agrupar, classificar, filtrar e armazená-los no HDFS.
- O Apache Hive usa uma consulta semelhante ao SQL para analisar dados em um ambiente distribuído. Ele possui dois componentes - a Linha de Comando do Hive e o servidor JDBC / ODBC e a linguagem usada é chamada HiveQL.
- O Apache Mahout é a biblioteca de aprendizado de máquina escrita em Java e usada para criar aplicativos de aprendizado de máquina, como cluster, classificação ou regressão. Possui algoritmos diferentes embutidos para diferentes casos de uso.
- O Apache HBase é um banco de dados NoSQL escrito em Java que roda sobre o Hadoop. Ele foi desenvolvido com base no BigTable do Google e é capaz de lidar com todos os tipos de dados.
- O Apache Sqoop é uma ferramenta de ingestão de dados usada para transferência de dados estruturados em massa entre RDBMS e Hadoop.
- O Apache Flume é outra ferramenta de ingestão de dados usada para transferência de dados semiestruturada e não estruturada entre o Hadoop e outras fontes de dados.
- O ZooKeeper é o coordenador que garante a coordenação entre várias ferramentas no ecossistema Hadoop.
- O Apache Ambari é um gerente de cluster que provisiona, gerencia clusters do Hadoop e também monitora sua saúde e status.
- O Apache Tez é uma nova ferramenta no ecossistema do Hadoop que acelera o processamento de consultas do Hadoop.
- O Apache Presto é um mecanismo de consulta SQL distribuído de código aberto que permite a capacidade de consulta em várias plataformas.
- O Apache HCatalog é um sistema de gerenciamento de metadados e tabelas do Hadoop que permite a interoperabilidade entre as ferramentas de processamento de dados. Também ajuda os usuários a escolher as melhores ferramentas para seus ambientes.
- O Apache Spark é a estrutura mais usada e popular entre os cientistas de dados. É um sistema de computação em cluster de alta velocidade que otimiza a utilização de recursos no caso de muitas tarefas iterativas. Ele oferece flexibilidade para processamento em lote e análise de dados em tempo real.
Abaixo estão as etapas para instalar o Apache
Até agora, aprendemos sobre o Apache e como ele é útil para quem deseja aprender Data Science ou Big Data Analytics. Agora, vamos nos aprofundar e instalar o apache no Windows, com base nas etapas abaixo.
- Vá para https://httpd.apache.org/ e clique no link Download na seção Apache httpd 2.4.38 Lançado.

- Você será levado à página seguinte e, em seguida, clique em Arquivos para Microsoft Windows.
- Clique no Apache Lounge.

- Você pode baixar 32 ou 64 bits do arquivo zip com base no sistema operacional Windows. Vamos baixar a versão de 64 bits aqui. Clique no link .zip correspondente para fazer o download.

- Agora, ele requer o C ++ Redistributable Visual Studio 2017. Portanto, faremos o download no link correspondente de 32 ou 64 bits.

- Após o download dos dois arquivos, iremos para o local baixado e instalaremos o C ++ Redistributable Visual Studio 2017 primeiro. Clique duas vezes no arquivo .exe.

- Marque 'Concordo' e clique em Instalar.

- A instalação do Apache está em andamento.
- Uma vez concluído, você receberá uma mensagem como esta. Clique em Fechar para finalizar a instalação.
- Agora, vá para a pasta em que você baixou o arquivo zip do Apache. Clique com o botão direito do mouse e selecione extrair aqui.
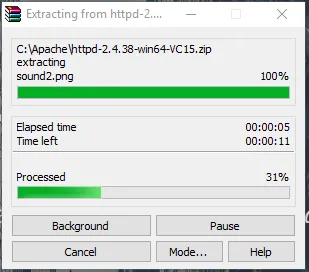
- Agora, teremos uma pasta Apache24 criada. Copie esta pasta para a unidade C e, em seguida, adicionaremos um caminho para as variáveis de ambiente do sistema.
Vá para Propriedades do sistema -> guia Avançado -> Clique no botão Variáveis de ambiente abaixo.
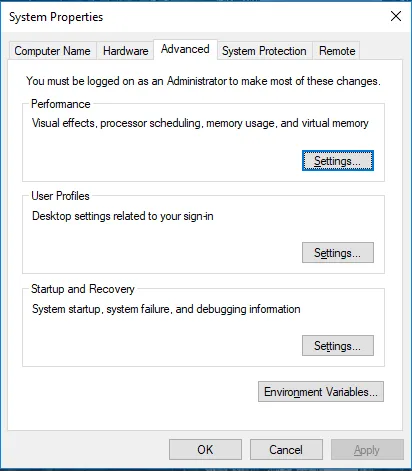
- Em Variáveis, localize Caminho e clique em Editar.
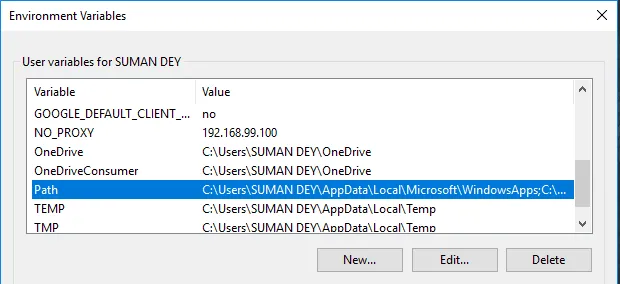
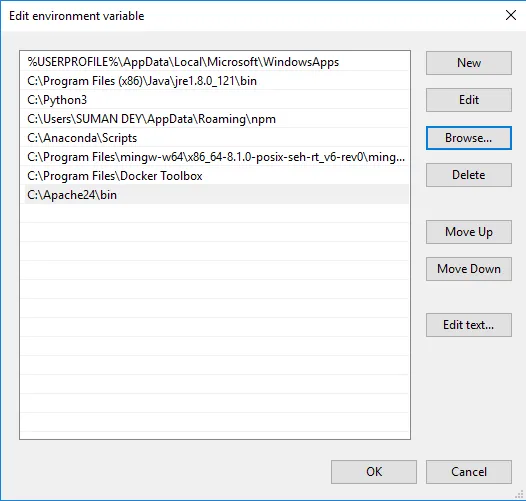
- Clique em Procurar -> Vá para a pasta Apache24 da unidade C -> Selecionar pasta bin -> Clique em OK.
- Instalaremos o Apache como um serviço do Windows. Execute o prompt de comando como administrador. Digite httpd –k install e pressione enter.
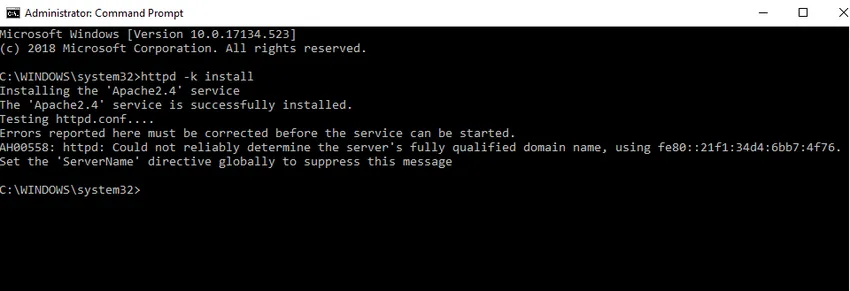
- Vamos verificar o serviço de instalação do Apache. Clique no ícone do Windows e digite serviços. Clique no aplicativo Serviços e encontre um serviço com o nome Apache24.

- Para iniciar o servidor Apache, clique com o botão direito do mouse e clique em Iniciar. O status mudará para 'Em execução'.
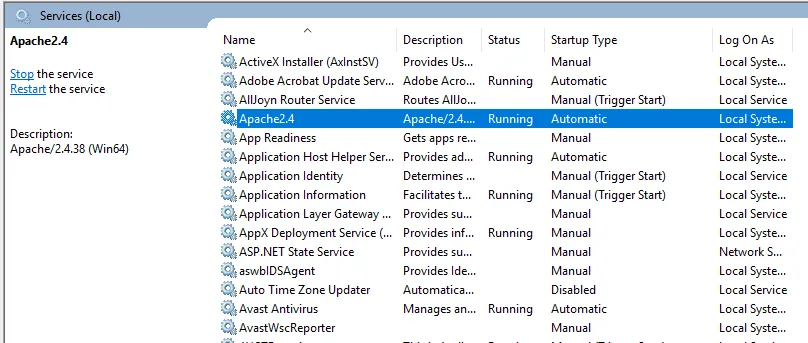
- Podemos testar com um navegador. Abra um navegador e navegue até http: // localhost e pressione enter. Uma mensagem informando 'Funciona!' irá aparecer para confirmar a instalação bem-sucedida do Apache.
Artigos recomendados
Este foi um guia sobre como instalar o Apache. Aqui discutimos as instruções e as diferentes etapas para instalar o Apache. Você também pode consultar o seguinte artigo para saber mais -
- Perguntas da entrevista do Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Principais diferenças