

Introdução à técnica de aprendizagem profunda
A técnica de aprendizado profundo é baseada em redes neurais artificiais que agem como um cérebro humano. Imita a maneira como o cérebro humano pensa e atua. Nesse modelo, o sistema aprende e executa a classificação a partir de imagens, texto ou som. Os modelos de Deep Learning são treinados por grandes dados rotulados e de várias camadas para alcançar alta precisão no resultado ainda mais do que o nível humano. O carro sem motorista aplica essa tecnologia para identificar o sinal de parada, o pedestre etc. na locomoção. Aparelhos eletrônicos, como celulares, alto-falantes, TV, computadores etc. têm um recurso de controle de voz por causa do Deep Learning. Essa técnica é nova e eficiente para consumidores e organizações.
Trabalho de Aprendizagem Profunda
Os métodos de aprendizagem profunda usam redes neurais. Portanto, eles são frequentemente chamados de redes neurais profundas. As redes neurais profundas ou ocultas têm várias camadas ocultas de redes profundas. O Deep Learning treina a IA para prever a saída com a ajuda de determinadas entradas ou camadas de rede ocultas. Essas redes são treinadas por grandes conjuntos de dados rotulados e aprendem recursos dos próprios dados. O aprendizado supervisionado e o não supervisionado trabalham no treinamento dos dados e na geração de recursos.
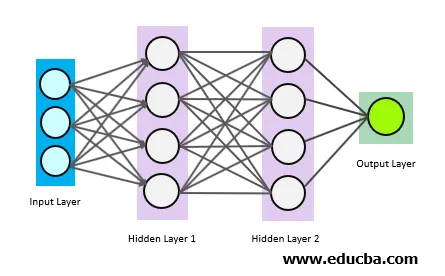
Os círculos acima são neurônios interconectados. Existem 3 tipos de neurônios:
- Camada de entrada
- Camadas ocultas
- Camada de saída
A camada de entrada obtém os dados de entrada e passa a entrada para a primeira camada oculta. Os cálculos matemáticos são realizados nos dados de entrada. Finalmente, a camada de saída fornece as conclusões.
A CNN ou Redes Neurais Convencionais, uma das redes neurais mais populares, reúne recursos aprendidos com os dados de entrada e usa camadas convolucionais 2D para torná-lo adequado para o processamento de dados 2D como imagens. Portanto, a CNN reduz o uso da extração manual de recursos nesse caso. Extrai diretamente os recursos necessários das imagens para classificação. Devido a esse recurso de automação, a CNN é um algoritmo mais preciso e confiável no Machine Learning. Toda CNN aprende recursos de imagens da camada oculta e essas camadas ocultas aumentam a complexidade das imagens aprendidas.
A parte importante é treinar a IA ou redes neurais. Para fazer isso, fornecemos informações do conjunto de dados e, finalmente, fazemos uma comparação das saídas com a ajuda da saída do conjunto de dados. Se o AI não for treinado, a saída pode estar errada.
Para descobrir quão errada é a saída da IA da saída real, precisamos de uma função para o cálculo. A função é chamada de função de custo. Se a função de custo for zero, a saída da AI e a saída real são as mesmas. Para reduzir o valor da função de custo, alteramos os pesos entre os neurônios. Para uma abordagem conveniente, pode ser usada uma técnica chamada Gradient Descent. GD reduz o peso dos neurônios ao mínimo após cada iteração. Este processo é feito automaticamente.
Técnica de aprendizagem profunda
Os algoritmos de Deep Learning percorrem várias camadas da (s) camada (s) oculta (s) ou Redes Neurais. Então, eles aprendem profundamente sobre as imagens para uma previsão precisa. Cada camada aprende e detecta recursos de baixo nível, como arestas e, posteriormente, a nova camada se funde com os recursos da camada anterior para melhor representação. Por exemplo, uma camada intermediária pode detectar qualquer borda do objeto, enquanto a camada oculta detectará o objeto ou a imagem completa.
Essa técnica é eficiente com dados grandes e complexos. Se os dados forem pequenos ou incompletos, o DL se tornará incapaz de trabalhar com novos dados.
Existem algumas redes de aprendizado profundo, como a seguir:
- Rede pré-treinada não supervisionada : é um modelo básico com 3 camadas: camada de entrada, oculta e saída. A rede é treinada para reconstruir a entrada e, em seguida, as camadas ocultas aprendem com as entradas para coletar informações e, finalmente, os recursos são extraídos da imagem.
- Rede Neural Convencional : Como Rede Neural padrão, possui uma convolução interna para detecção de bordas e reconhecimento preciso de objetos.
- Rede Neural Recorrente : Nesta técnica, a saída do estágio anterior é usada como entrada para o estágio seguinte ou atual. A RNN armazena as informações nos nós de contexto para aprender os dados de entrada e produzir a saída. Por exemplo, para completar uma frase, precisamos de palavras. ou seja, para prever a próxima palavra, são necessárias palavras anteriores que precisam ser lembradas. A RNN basicamente resolve esse tipo de problema.
- Redes Neurais Recursivas : É um modelo hierárquico em que a entrada é uma estrutura semelhante a uma árvore. Esse tipo de rede é criado aplicando o mesmo conjunto de pesos sobre a montagem de entradas.
O Deep Learning possui diversas aplicações em áreas financeiras, visão computacional, reconhecimento de áudio e fala, análise de imagens médicas, técnicas de design de medicamentos, etc.
Como criar modelos de aprendizado profundo?
Os algoritmos de Deep Learning são criados conectando camadas entre eles. O primeiro passo acima é a camada de entrada seguida pela (s) camada (s) oculta (s) e a camada de saída. Cada camada é composta por neurônios interligados. A rede consome uma grande quantidade de dados de entrada para operá-los através de várias camadas.
Para criar um modelo de Deep Learning, são necessárias as seguintes etapas:
- Compreendendo o problema
- Identificar dados
- Selecione o algoritmo
- Treine o modelo
- Teste o modelo
O aprendizado ocorre em duas fases
- Aplique uma transformação não linear dos dados de entrada e crie um modelo estatístico como saída.
- O modelo é aprimorado com um método derivativo.
Essas duas fases das operações são conhecidas como iteração. As redes neurais repetem as duas etapas até que a saída e a precisão desejadas sejam geradas.
1. Treinamento de redes: para treinar uma rede de dados, coletamos um grande número de dados e projetamos um modelo que aprenderá os recursos. Mas o processo é mais lento no caso de um número muito grande de dados.
2. Transfer Learning: O Transfer Learning basicamente ajusta um modelo pré-treinado e uma nova tarefa é executada posteriormente. Nesse processo, o tempo de computação se torna menor.
3. Extração de recursos: depois que todas as camadas são treinadas sobre os recursos do objeto, os recursos são extraídos e a saída é prevista com precisão.
Conclusão
Deep Learning é um subconjunto de ML e ML é um subconjunto de IA. Todas as três tecnologias e modelos têm um enorme impacto na vida real. Entidades comerciais, gigantes comerciais estão implementando modelos de Aprendizado Profundo para resultados superiores e comparáveis em automação, inspirada no cérebro humano.
Artigos recomendados
Este é um guia para a técnica de aprendizagem profunda. Aqui discutimos como criar modelos de aprendizado profundo, juntamente com as duas fases da operação. Você também pode consultar os seguintes artigos para saber mais -
- O que é aprendizagem profunda
- Carreiras em Aprendizagem Profunda
- 13 perguntas e respostas úteis da entrevista de aprendizado profundo
- Aprendizado de máquina com hiperparâmetro