
O que é o algoritmo SVM?
SVM significa Support Vector Machine. O SVM é um algoritmo de aprendizado de máquina supervisionado que é comumente usado para desafios de classificação e regressão. Aplicações comuns do algoritmo SVM são: Sistema de detecção de intrusão, reconhecimento de manuscrito, previsão de estrutura de proteínas, detecção de esteganografia em imagens digitais etc.
No algoritmo SVM, cada ponto é representado como um item de dados no espaço n-dimensional em que o valor de cada recurso é o valor de uma coordenada específica.
Após a plotagem, a classificação foi realizada encontrando o plano de hype que diferencia duas classes. Consulte a imagem abaixo para entender esse conceito.
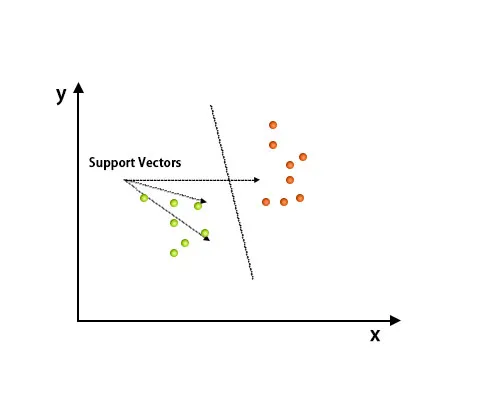
O algoritmo de máquina de vetores de suporte é usado principalmente para resolver problemas de classificação. Os vetores de suporte nada mais são do que as coordenadas de cada item de dados. A Support Vector Machine é uma fronteira que diferencia duas classes usando o hiperplano.
Como o algoritmo SVM funciona?
Na seção acima, discutimos a diferenciação de duas classes usando o hiperplano. Agora vamos ver como esse algoritmo SVM realmente funciona.
Cenário 1: identificar o hiperplano direito
Aqui pegamos três hiperplanos, isto é, A, B e C. Agora temos que identificar o hiperplano certo para classificar estrela e círculo.
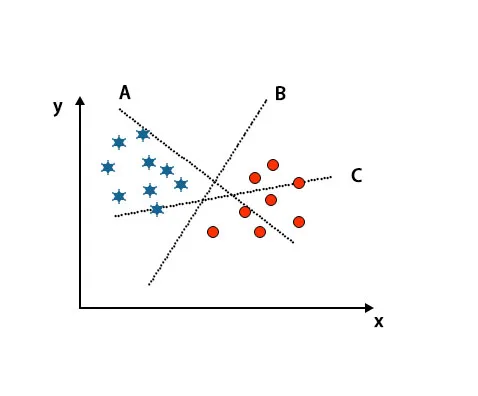
Para identificar o hiperplano certo, devemos conhecer a regra do polegar. Selecione o hiperplano que diferencia duas classes. Na imagem acima mencionada, o hiperplano B diferencia muito bem duas classes.
Cenário 2: identifique o hiperplano certo
Aqui pegamos três hiperplanos, isto é, A, B e C. Esses três hiperplanos já estão diferenciando muito bem as classes.
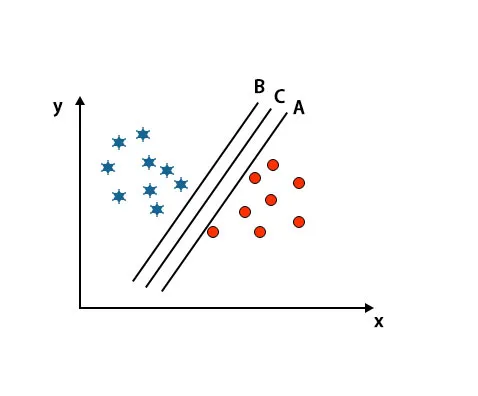
Nesse cenário, para identificar o hiperplano correto, aumentamos a distância entre os pontos de dados mais próximos. Essa distância não passa de uma margem. Consulte a imagem abaixo.
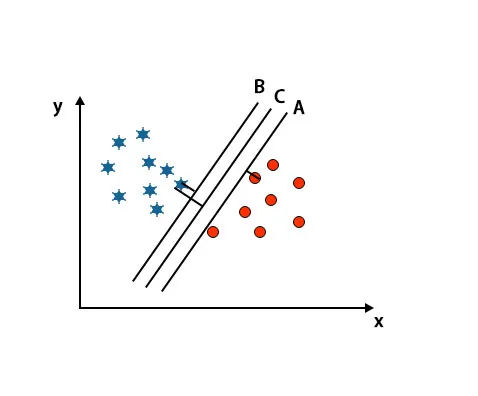
Na imagem acima mencionada, a margem do hiperplano C é maior que o hiperplano A e o hiperplano B. Portanto, nesse cenário, C é o hiperplano correto. Se escolhermos o hiperplano com uma margem mínima, isso poderá levar a erros de classificação. Por isso, escolhemos o hiperplano C com margem máxima devido à robustez.
Cenário 3: Identifique o Hiperplano Direito
Nota: Para identificar o hiperplano, siga as mesmas regras mencionadas nas seções anteriores.
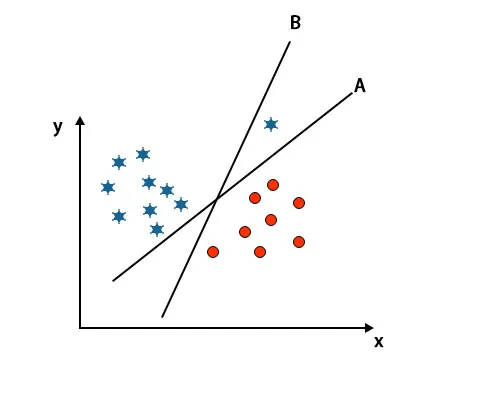
Como você pode ver na imagem acima mencionada, a margem do hiperplano B é maior que a margem do hiperplano A, e é por isso que alguns selecionam o hiperplano B à direita. Mas no algoritmo SVM, ele seleciona o hiperplano que classifica as classes precisas antes de maximizar a margem. Nesse cenário, o hiperplano A classificou tudo com precisão e há algum erro com a classificação de hiperplano B. Portanto, A é o hiperplano correto.
Cenário 4: Classifique duas Classes
Como você pode ver na imagem abaixo mencionada, não podemos diferenciar duas classes usando uma linha reta, porque uma estrela está como uma exceção na outra classe de círculo.
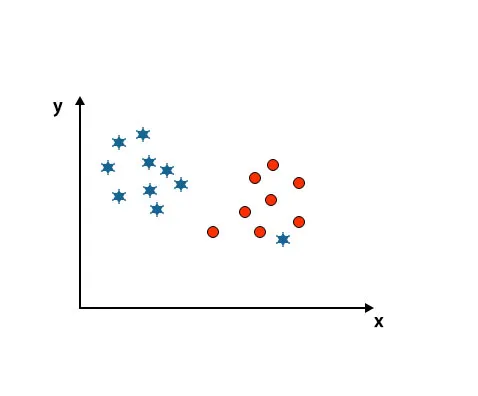
Aqui, uma estrela está em outra classe. Para a classe de estrelas, essa estrela é a mais estranha. Por causa da propriedade de robustez do algoritmo SVM, ele encontrará o hiperplano certo com a margem mais alta ignorando um erro externo.
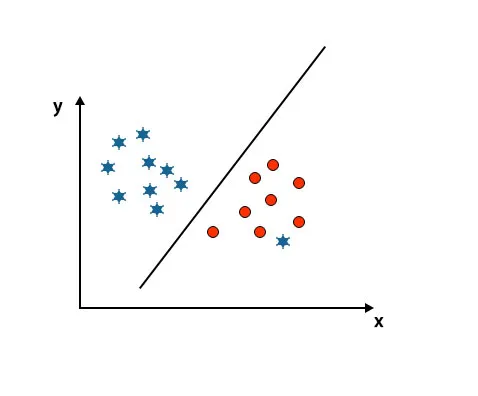
Cenário 5: Hiperplano fino para diferenciar classes
Até agora, vimos o hiperplano linear. Na imagem abaixo mencionada, não temos hiperplano linear entre classes.
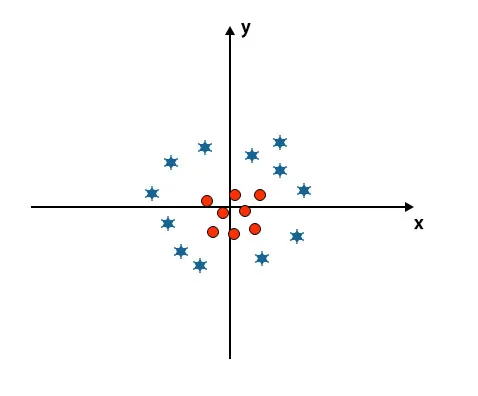
Para classificar essas classes, o SVM apresenta alguns recursos adicionais. Nesse cenário, vamos usar esse novo recurso z = x 2 + y 2.
Plota todos os pontos de dados nos eixos xe z.

Nota
- Todos os valores no eixo z devem ser positivos porque z é igual à soma de x ao quadrado e y ao quadrado.
- No gráfico acima mencionado, os círculos vermelhos são fechados à origem do eixo xe do eixo y, levando o valor de z a mais baixo e a estrela é exatamente o oposto do círculo, e está longe da origem do eixo x e eixo y, levando o valor de z a alto.
No algoritmo SVM, é fácil classificar usando hiperplano linear entre duas classes. Mas a questão que se coloca aqui é se devemos adicionar esse recurso do SVM para identificar o hiperplano. Portanto, a resposta é não, para resolver esse problema, o SVM possui uma técnica conhecida como truque do kernel.
O truque do kernel é a função que transforma os dados em um formato adequado. Existem vários tipos de funções do kernel usadas no algoritmo SVM, isto é, polinomial, linear, não linear, função de base radial, etc. Aqui, usando o truque do kernel, o espaço de entrada de baixa dimensão é convertido em um espaço de maior dimensão.
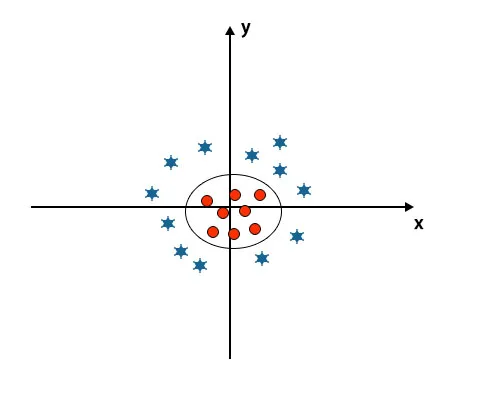
Quando olhamos para o hiperplano, a origem do eixo e do eixo y, ele se parece com um círculo. Consulte a imagem abaixo.
Prós do algoritmo SVM
- Mesmo que os dados de entrada sejam não lineares e não separáveis, os SVMs geram resultados de classificação precisos devido à sua robustez.
- Na função de decisão, ele usa um subconjunto de pontos de treinamento chamados vetores de suporte, portanto, é eficiente em termos de memória.
- É útil resolver qualquer problema complexo com uma função de kernel adequada.
- Na prática, os modelos SVM são generalizados, com menos risco de sobreajuste no SVM.
- Os SVMs funcionam muito bem para classificação de texto e para encontrar o melhor separador linear.
Contras do algoritmo SVM
- Demora muito tempo de treinamento ao trabalhar com grandes conjuntos de dados.
- É difícil entender o modelo final e o impacto individual.
Conclusão
Ele foi orientado a oferecer suporte ao algoritmo de máquina vetorial, que é um algoritmo de aprendizado de máquina. Neste artigo, discutimos o que é o algoritmo SVM, como ele funciona e quais são suas vantagens em detalhes.
Artigos recomendados
Este foi um guia para o algoritmo SVM. Aqui discutimos seu trabalho com um cenário, prós e contras do algoritmo SVM. Você também pode consultar os seguintes artigos para saber mais -
- Algoritmos de mineração de dados
- Técnicas de mineração de dados
- O que é aprendizado de máquina?
- Ferramentas de aprendizado de máquina
- Exemplos de algoritmo C ++