

Visão geral dos tipos de cluster
Antes de aprender os tipos de cluster, vamos entender o que é cluster e por que é tão importante no setor de aprendizado de máquina no momento.
O que é clustering? O clustering é um processo em que o algoritmo divide os pontos de dados em um número definido de grupos com base no princípio de que pontos de dados semelhantes permanecem próximos um do outro e se enquadram no mesmo grupo.
Por que isso é tão importante agora? Vamos entender que, vendo um exemplo, por exemplo, existe uma loja de roupas on-line e eles querem entender melhor seus clientes para que possam tornar sua estratégia de publicidade mais eficaz. Não é possível que eles tenham um tipo único de estratégia para cada cliente. Em vez disso, o que eles podem fazer é dividir os clientes em um determinado número de grupos (com base nas compras anteriores) e ter uma estratégia separada de grupos separados. Isso torna os negócios mais eficazes, e é por esse motivo que o clustering é importante no setor agora.
Tipos de cluster
Em geral, os métodos de técnicas de agrupamento são classificados em dois tipos: métodos Hard e soft. No método de cluster rígido, cada ponto ou observação de dados pertence a apenas um cluster. No método de agrupamento dinâmico, cada ponto de dados não pertencerá completamente a um cluster; em vez disso, ele poderá ser membro de mais de um cluster e possuir um conjunto de coeficientes de associação correspondentes à probabilidade de estar em um determinado cluster.
Atualmente, existem diferentes tipos de métodos de clustering em uso. Neste artigo, vamos ver alguns dos mais importantes, como cluster hierárquico, clustering de particionamento, clustering difuso, cluster baseado em densidade e cluster baseado em modelo de distribuição. Agora vamos discutir cada uma delas com um exemplo:
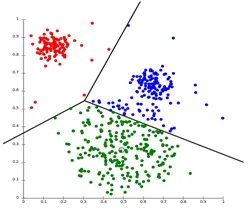
1. Particionando em cluster
O particionamento em cluster é um tipo de técnica de cluster, que divide o conjunto de dados em um número definido de grupos. (Por exemplo, o valor de K em KNN e será decidido antes de treinarmos o modelo). Também pode ser chamado de método baseado no centróide. Nesta abordagem, o centro de cluster (centróide) é formado de modo que a distância dos pontos de dados nesse cluster seja mínima quando calculada com outros centróides de cluster. Um exemplo mais popular desse algoritmo é o algoritmo KNN. É assim que um algoritmo de agrupamento de particionamento se parece
2. Clustering hierárquico
O cluster hierárquico é um tipo de técnica de cluster, que divide esse conjunto de dados em vários clusters, nos quais o usuário não especifica o número de clusters a serem gerados antes do treinamento do modelo. Esse tipo de técnica de cluster também é conhecido como métodos baseados em conectividade. Nesse método, o particionamento simples do conjunto de dados não será realizado, enquanto nos fornece a hierarquia dos clusters que se fundem após uma certa distância. Depois que o cluster hierárquico for feito no conjunto de dados, o resultado será uma representação em árvore de pontos de dados (Dendograma), que são divididos em clusters. É assim que um cluster hierárquico se parece após a conclusão do treinamento
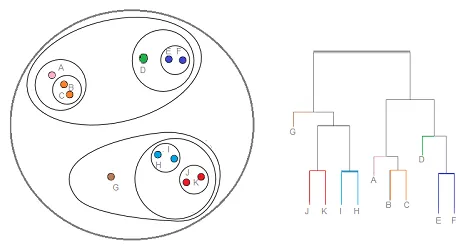
Link da fonte: Clustering hierárquico
No cluster de particionamento e no cluster hierárquico, uma diferença principal que podemos notar é que, no cluster de particionamento, especificaremos previamente o valor de quantos clusters queremos que o conjunto de dados seja dividido e não pré-especificaremos esse valor no cluster hierárquico .
3. Clustering Baseado em Densidade
Nesse agrupamento, os agrupamentos de técnicas serão formados por segregação de várias regiões de densidade com base em diferentes densidades no gráfico de dados. O Clustering espacial e a aplicação com base em densidade com ruído (DBSCAN) é o algoritmo mais utilizado nesse tipo de técnica. A idéia principal por trás desse algoritmo é que deve haver um número mínimo de pontos que contenham na vizinhança de um determinado raio para cada ponto no cluster. Até agora, nas técnicas de agrupamento discutidas acima, se você observar cuidadosamente, podemos notar uma coisa comum em todas as técnicas que são a forma de agrupamentos formados: são esféricas, ovais ou côncavas. O DBSCAN pode formar clusters em diferentes formas; esse tipo de algoritmo é mais adequado quando o conjunto de dados contém ruído ou outliers. É assim que um algoritmo de cluster espacial baseado em densidade se parece após o término do treinamento.
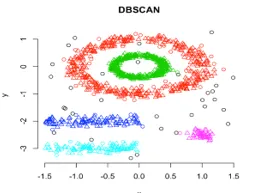
Link da fonte: Clustering Baseado em Densidade
4. Clustering baseado em modelo de distribuição
Nesse tipo de cluster, os clusters de técnica são formados pela identificação pela probabilidade de todos os pontos de dados no cluster serem da mesma distribuição (Normal, Gaussiana). O algoritmo mais popular nesse tipo de técnica é o clustering de Maximização de Expectativas (EM) usando Modelos de Mistura Gaussiana (GMM).
Técnicas normais de cluster, como cluster hierárquico e clustering de particionamento, não se baseiam em modelos formais; o KNN no clustering de particionamento gera resultados diferentes com valores K diferentes. Como o KNN e o KMN consideram a média para o centro do cluster, não é melhor adequado em alguns casos com os Modelos de Mistura Gaussiana, presumimos que os pontos de dados sejam distribuídos gaussianos, dessa forma, temos dois parâmetros para descrever a forma da média dos clusters e o desvio padrão. Dessa maneira, para cada cluster, é atribuída uma distribuição Gaussiana, para obter os valores ótimos desses parâmetros (média e desvio padrão), um algoritmo de otimização chamado Expectation Maximization está sendo usado. É assim que o EM - GMM se parece após o treinamento.
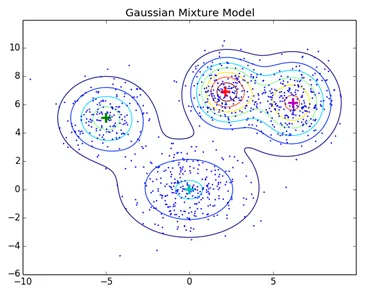
Link de origem: Clustering baseado em modelo de distribuição
5. Clustering Difuso
Pertence a um ramo das técnicas de clustering de método simples, enquanto todas as técnicas de clustering mencionadas acima pertencem a técnicas de clustering de método rígido. Nesse tipo de técnica de agrupamento, pontos próximos ao centro, talvez uma parte do outro agrupamento em maior grau do que os pontos na borda do mesmo agrupamento. A probabilidade de um ponto pertencente a um determinado cluster é um valor que varia entre 0 e 1. O algoritmo mais popular nesse tipo de técnica é FCM (Algoritmo de C-Fuzzy C) Aqui, o centróide de um cluster é calculado como a média de todos os pontos, ponderados pela probabilidade de pertencer ao cluster.
Conclusão - Tipos de Clustering
Essas são algumas das diferentes técnicas de clustering atualmente em uso e, neste artigo, abordamos um algoritmo popular em cada técnica de clustering. Temos que escolher o tipo de tecnologia que usamos, com base em nosso conjunto de dados e requisitos que precisamos cumprir.
Artigos recomendados
Este foi um guia para tipos de cluster. Aqui discutimos diferentes tipos de cluster com seus exemplos. Você também pode consultar os seguintes artigos para saber mais -
- Algoritmo de cluster hierárquico
- Clustering no Machine Learning
- Tipos de algoritmos de aprendizado de máquina
- Tipos de técnicas de análise de dados
- Como usar e remover a hierarquia no Tableau?
- Guia completo para tipos de análise de dados