
Introdução aos modelos de aprendizado de máquina
Uma visão geral de vários modelos de aprendizado de máquina usados na prática. Seguindo a definição, um modelo de aprendizado de máquina é uma configuração matemática obtida após a aplicação de metodologias específicas de aprendizado de máquina. Usando a ampla variedade de APIs, a construção de um modelo de aprendizado de máquina é bastante simples hoje em dia, com menos linhas de códigos. Mas a verdadeira habilidade de um profissional de ciência de dados aplicada reside na escolha do modelo correto com base na declaração do problema e na validação cruzada, em vez de lançar dados para algoritmos sofisticados aleatoriamente. Neste artigo, discutiremos vários modelos de aprendizado de máquina e como usá-los efetivamente com base no tipo de problemas que eles abordam.
Tipos de modelos de aprendizado de máquina
Com base no tipo de tarefas, podemos classificar os modelos de aprendizado de máquina nos seguintes tipos:
- Modelos de Classificação
- Modelos de regressão
- Agrupamento
- Redução de dimensionalidade
- Aprendizagem profunda etc.
1) Classificação
Com relação ao aprendizado de máquina, a classificação é a tarefa de prever o tipo ou a classe de um objeto dentro de um número finito de opções. A variável de saída para classificação é sempre uma variável categórica. Por exemplo, prever um email como spam ou não é uma tarefa de classificação binária padrão. Agora vamos anotar alguns modelos importantes para problemas de classificação.
- Algoritmo K-vizinhos mais próximos - simples, mas computacionalmente exaustivo.
- Naive Bayes - Baseado no teorema de Bayes.
- Regressão logística - Modelo linear para classificação binária.
- SVM - pode ser usado para classificações binárias / de várias classes.
- Árvore de decisão - classificador baseado em ' If Else ', mais robusto para outliers.
- Conjuntos - Combinação de vários modelos de aprendizado de máquina reunidos para obter melhores resultados.
2) Regressão
Na máquina, a regressão de aprendizado é um conjunto de problemas em que a variável de saída pode assumir valores contínuos. Por exemplo, prever o preço da companhia aérea pode ser considerado como uma tarefa de regressão padrão. Vamos anotar alguns importantes modelos de regressão usados na prática.
- Regressão linear - O modelo de linha de base mais simples para tarefas de regressão, funciona bem apenas quando os dados são linearmente separáveis e muito menos ou nenhuma multicolinearidade está presente.
- Regressão de Lasso - Regressão linear com regularização de L2.
- Regressão de Ridge - Regressão linear com regularização de L1.
- Regressão SVM
- Regressão em árvore de decisão etc.
3) Agrupamento
Em palavras simples, o agrupamento é a tarefa de agrupar objetos semelhantes. Os modelos de aprendizado de máquina ajudam a identificar objetos semelhantes automaticamente, sem intervenção manual. Não podemos construir modelos eficazes de aprendizado de máquina supervisionado (modelos que precisam ser treinados com dados manualmente selecionados ou com curadoria) sem dados homogêneos. O agrupamento nos ajuda a conseguir isso de maneira mais inteligente. A seguir, estão alguns dos modelos de cluster amplamente usados:
- K significa - Simples, mas sofre de alta variação.
- K significa ++ - Versão modificada de K significa.
- K medoids.
- Cluster aglomerado - Um modelo hierárquico de clustering.
- DBSCAN - Algoritmo de clustering baseado em densidade etc.
4) Redução de dimensionalidade
Dimensionalidade é o número de variáveis preditoras usadas para prever a variável ou o alvo independente. Muitas vezes, nos conjuntos de dados do mundo real, o número de variáveis é muito alto. Variáveis demais também trazem a maldição do excesso de ajuste nos modelos. Na prática, entre esse grande número de variáveis, nem todas as variáveis contribuem igualmente para a meta e, em um grande número de casos, podemos preservar as variações com um número menor de variáveis. Vamos listar alguns modelos comumente usados para redução de dimensionalidade.
- PCA - Cria um número menor de novas variáveis a partir de um grande número de preditores. As novas variáveis são independentes uma da outra, mas menos interpretáveis.
- TSNE - fornece incorporação de dimensões mais baixas de pontos de dados de dimensões mais altas.
- SVD - A decomposição de valor singular é usada para decompor a matriz em partes menores para um cálculo eficiente.
5) Aprendizagem Profunda
O aprendizado profundo é um subconjunto de aprendizado de máquina que lida com redes neurais. Com base na arquitetura das redes neurais, vamos listar importantes modelos de aprendizado profundo:
- Perceptron de várias camadas
- Redes neurais de convolução
- Redes Neurais Recorrentes
- Máquina Boltzmann
- Autoencoders etc.
Qual modelo é o melhor?
Acima, tiramos idéias sobre vários modelos de aprendizado de máquina. Agora, surge uma pergunta óbvia: "Qual é o melhor modelo entre eles?" Depende do problema em questão e de outros atributos associados, como discrepantes, volume de dados disponíveis, qualidade dos dados, engenharia de recursos etc. Na prática, é sempre preferível começar com o modelo mais simples aplicável ao problema e aumentar a complexidade. gradualmente pelo ajuste adequado dos parâmetros e validação cruzada. Existe um provérbio no mundo da ciência de dados - 'A validação cruzada é mais confiável que o conhecimento de domínio'.
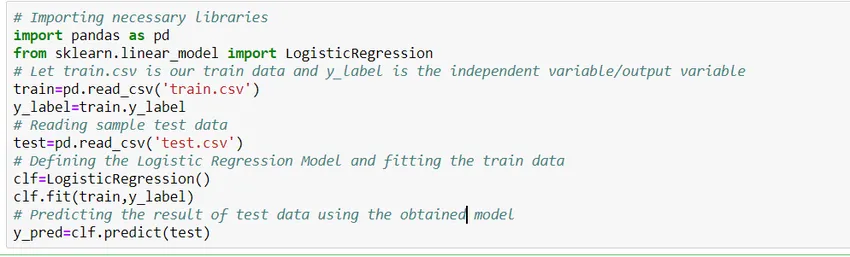
Como construir um modelo?
Vamos ver como criar um modelo de regressão logística simples usando a biblioteca Scikit Learn de python. Por simplicidade, estamos assumindo que o problema é um modelo de classificação padrão e 'train.csv' é o train e 'test.csv' são os dados do train e test respectivamente.
Conclusão
Neste artigo, discutimos os importantes modelos de aprendizado de máquina usados para fins práticos e como construir um modelo simples de aprendizado de máquina em python. A escolha de um modelo adequado para um caso de uso específico é muito importante para obter o resultado adequado de uma tarefa de aprendizado de máquina. Para comparar o desempenho entre vários modelos, são definidas métricas de avaliação ou KPIs para problemas de negócios específicos e o melhor modelo é escolhido para produção após a aplicação da verificação estatística de desempenho.
Artigos recomendados
Este é um guia para modelos de aprendizado de máquina. Aqui discutimos os 5 principais tipos de modelos de aprendizado de máquina com sua definição. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Métodos de aprendizado de máquina
- Tipos de aprendizado de máquina
- Algoritmos de aprendizado de máquina
- O que é aprendizado de máquina?
- Aprendizado de máquina com hiperparâmetro
- KPI no Power BI
- Algoritmo de cluster hierárquico
- Clustering hierárquico | Clustering Aglomerativo e Divisivo