

Introdução à mineração de dados
Este é um método de mineração de dados usado para colocar elementos de dados em seus grupos semelhantes. Cluster é o procedimento de dividir objetos de dados em subclasses. A qualidade do cluster depende do método que usamos. O cluster também é chamado de segmentação de dados, pois grandes grupos de dados são divididos por sua similaridade.
O que é clustering na mineração de dados?
Clustering é o agrupamento de objetos específicos com base em suas características e semelhanças. Quanto à mineração de dados, essa metodologia divide os dados que melhor se adaptam à análise desejada usando um algoritmo de junção especial. Essa análise permite que um objeto não faça parte ou estritamente parte de um cluster, chamado de particionamento físico desse tipo. No entanto, partições suaves sugerem que cada objeto no mesmo grau pertence a um cluster. Divisões mais específicas podem ser criadas como objetos de vários clusters, um único cluster pode ser forçado a participar ou mesmo árvores hierárquicas podem ser construídas em relações de grupo. Este sistema de arquivos pode ser implementado de diferentes maneiras, com base em vários modelos. Esses algoritmos distintos se aplicam a todo e qualquer modelo, distinguindo suas propriedades e seus resultados. Um bom algoritmo de armazenamento em cluster é capaz de identificar o cluster independentemente da forma do cluster. Existem três estágios básicos do algoritmo de agrupamento, que são mostrados abaixo
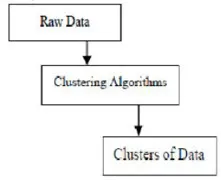
Algoritmos de cluster na mineração de dados
Dependendo dos modelos de cluster descritos recentemente, muitos clusters podem ser usados para particionar informações em um conjunto de dados. Deve-se dizer que cada método tem suas próprias vantagens e desvantagens. A seleção de um algoritmo depende das propriedades e da natureza do conjunto de dados.
Os métodos de cluster para mineração de dados podem ser mostrados abaixo
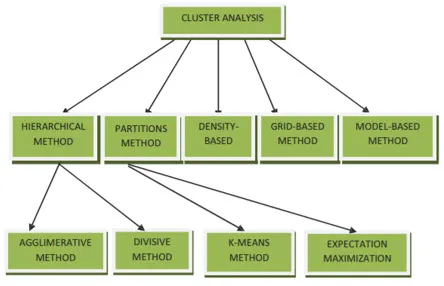
- Método baseado em particionamento
- Método baseado em densidade
- Método baseado em centróide
- Método hierárquico
- Método baseado em grade
- Método Baseado em Modelo
1. Método baseado em particionamento
O algoritmo de partição divide dados em muitos subconjuntos.
Vamos supor que o algoritmo de particionamento construa a partição de dados, pois objetos estão presentes no banco de dados. Portanto, cada partição será representada como k ≤ n.
Isso dá uma ideia de que a classificação dos dados está em k grupos, que podem ser mostrados abaixo
A Figura 1 mostra pontos originais no cluster

A Figura 2 mostra o agrupamento de partições após aplicar um algoritmo
Isso indica que cada grupo tem pelo menos um objeto, assim como todo objeto, deve pertencer a exatamente um grupo.
2. Método Baseado em Densidade
Esses algoritmos produzem clusters em um local determinado, com base na alta densidade de participantes do conjunto de dados. Ele agrega alguma noção de intervalo para membros do grupo em clusters para um nível padrão de densidade. Esses processos podem ter menos desempenho na detecção das áreas de superfície do grupo.
3. Método baseado em centróide
Quase todo cluster é referenciado por um vetor de valores nesse tipo de técnica de agrupamento de sistemas operacionais. Em comparação com outros clusters, cada objeto faz parte do cluster com uma diferença mínima de valor. O número de clusters deve ser predefinido e esse é o maior problema de algoritmo desse tipo. Essa metodologia é a mais próxima do assunto de identificação e é amplamente utilizada para problemas de otimização.
4. Método hierárquico
O método criará uma decomposição hierárquica de um determinado conjunto de objetos de dados. Com base em como a decomposição hierárquica é formada, podemos classificar métodos hierárquicos. Este método é dado da seguinte maneira
- Abordagem Aglomerativa
- Abordagem Divisiva
A Abordagem Aglomerativa também é conhecida como Abordagem de Botão. Aqui começamos com todo objeto que constitui um grupo separado. Ele continua a fundir objetos ou grupos próximos
A abordagem divisiva também é conhecida como abordagem de cima para baixo. Começamos com todos os objetos no mesmo cluster. Esse método é rígido, ou seja, nunca pode ser desfeito depois que uma fusão ou divisão é concluída
5. Método Baseado em Grade
Os métodos baseados em grade funcionam no espaço do objeto em vez de dividir os dados em uma grade. Grade é dividida com base nas características dos dados. Usando esse método, dados não numéricos são fáceis de gerenciar. A ordem dos dados não afeta o particionamento da grade. Uma vantagem importante de um modelo baseado em grade, fornece velocidade de execução mais rápida.
As vantagens do cluster hierárquico são as seguintes
- É aplicável a qualquer tipo de atributo.
- Ele fornece flexibilidade relacionada ao nível de granularidade.
6. Método Baseado em Modelo
Este método usa um modelo hipotético baseado na distribuição de probabilidade. Ao agrupar a função de densidade, esse método localiza os clusters. Ele reflete a distribuição espacial dos pontos de dados.
Aplicação de clustering em Data Mining
O clustering pode ajudar em muitos campos, como em biologia, plantas e animais classificados por suas propriedades, bem como no marketing. O clustering ajudará a identificar clientes de um determinado registro de cliente com conduta semelhante. Em muitas aplicações, como pesquisa de mercado, reconhecimento de padrões, processamento de dados e imagens, a análise de agrupamento é usada em grandes números. O cluster também pode ajudar os anunciantes em sua base de clientes a encontrar grupos diferentes. E seus grupos de clientes podem ser definidos por padrões de compra. Em biologia, é usado para a determinação de taxonomias de plantas e animais, para a categorização de genes com funcionalidade semelhante e para a compreensão de estruturas inerentes à população. Em um banco de dados de observação da Terra, o agrupamento também facilita a localização de áreas de uso semelhante na terra. Ajuda a identificar grupos de casas e apartamentos por tipo, valor e destino das casas. O agrupamento de documentos na web também é útil para a descoberta de informações. A análise de cluster é uma ferramenta para obter informações sobre a distribuição de dados para observar as características de cada cluster como uma função de mineração de dados.
Conclusão
O clustering é importante na mineração de dados e em sua análise. Neste artigo, vimos como o cluster pode ser feito aplicando vários algoritmos de cluster, bem como sua aplicação na vida real.
Artigo recomendado
Este foi um guia para o que é clustering em mineração de dados. Aqui discutimos os conceitos, definição, recursos, aplicação de Clustering em Data Mining. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- O que é processamento de dados?
- Como se tornar um analista de dados?
- O que é injeção de SQL?
- Definição do que é o SQL Server?
- Visão geral da arquitetura de mineração de dados
- Clustering no Machine Learning
- Algoritmo de cluster hierárquico
- Clustering hierárquico | Clustering Aglomerativo e Divisivo