

O que é Kafka?
Para entender o Kafka, é melhor entender o que é a tecnologia 'Processamento de fluxo'. 'O processamento de fluxo é uma tecnologia que permite ao usuário consultar um fluxo de dados contínuo em um micro período para entender melhor as condições subjacentes responsáveis.
Um cenário em tempo real - imagine se o seu sensor de temperatura envia dados que você pode consultar e receber um alerta após o recebimento de um ponto de congelamento. Essa consulta de dados pode ser feita em microssegundos.
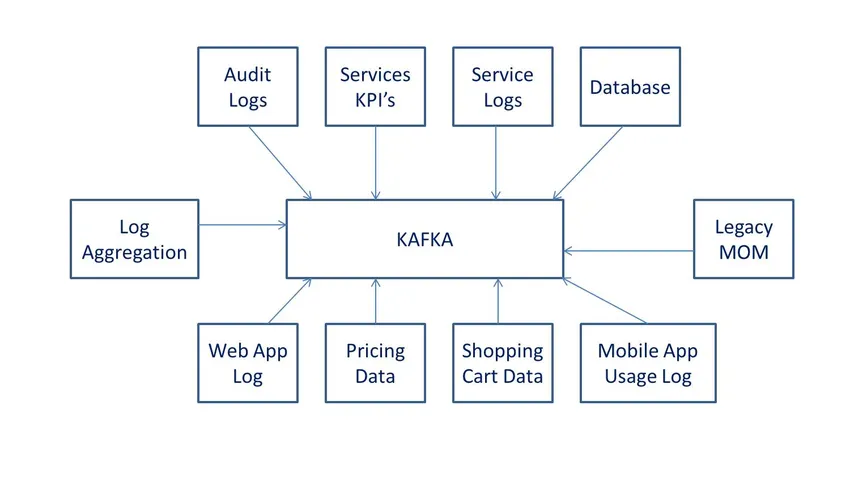
Definições
de acordo com o Wiki, é um software de processamento de dados de código aberto. Foi desenvolvido pelo LinkedIn e posteriormente doado ao software Apache.
Entendendo Kafka
Seu crescimento está explodindo exponencialmente. Vamos ver alguns fatos e estatísticas para sublinhar melhor nosso pensamento. Goza da preferência principal por mais de um terço das Fortune 500 em todo o mundo. Essa distribuição é compartilhada por empresas de viagens, gigantes de telecomunicações, bancos e várias outras. LinkedIn, Microsoft e Netflix processam mensagens de quatro vírgulas por dia com Kafka (quase igual a 1.000.000.000.000).
É usado para fluxos de dados em tempo real, para coletar grandes dados ou para fazer análises em tempo real (ou ambos). O Kafka é usado com microsserviços na memória para fornecer durabilidade e pode ser usado para alimentar eventos nos sistemas de automação no estilo CEP (sistemas de streaming de eventos complexos) e IoT / IFTTT.
Como Kafka funciona tão fácil?
Impulsionado pela simplicidade, seria o caminho certo para definir o desempenho. É fácil descobrir como o Kafka funciona com tanta facilidade a partir de sua configuração e uso. Esse desempenho aprimorado no comportamento é dedicado à sua estabilidade, ao fornecimento de durabilidade confiável, com sua capacidade embutida flexível para publicar ou assinar ou manter a fila de manutenção. É muito importante ter isso, se você precisar lidar com o grupo N de números de clientes, se precisar mostrar uma replicação robusta no mercado, com o objetivo de fornecer a seus clientes uma abordagem consistente (por exemplo, partição de tópicos Kafka). Um comportamento crucial da Kafka que a diferencia dos seus concorrentes é sua compatibilidade com sistemas com fluxos de dados - seu processo e permite que esses sistemas agregem, transformem e carreguem outras lojas para facilitar o trabalho. "Todos os fatos acima mencionados não seriam possíveis se Kafka fosse lento". Seu desempenho excepcional torna isso possível.
Além disso, para facilitar o trabalho de Kafka, precisamos acessar o "Nível do SO". Vamos descobrir como as coisas funcionam para o Kafka no nível do SO -
- Ele conta com kernels do SO para mover os dados mais rapidamente e trabalha com o princípio da cópia zero.
- Ele permite que os registros de dados sejam agrupados em partes que podem ser vistas do sistema de arquivos (também conhecido como log de tópicos Kafka) para os consumidores.
- A facilidade de agrupar dados fornece uma compactação eficiente de dados com redução da latência de E / S.
- Ele tem a capacidade de escalar horizontalmente via sharding. Ele pode compartilhar um log de título em centenas de partições para milhares. Isso permite lidar com a enorme carga de trabalho facilmente.
O que você pode fazer com Kafka?
Se sua empresa joga com enormes conjuntos de dados regularmente, você precisa do Kafka. Há uma longa lista de empresas que o utilizam.
- O LinkedIn usa para rastrear dados e métricas operacionais.
- Twitter para fornecer infraestruturas de processamento de fluxo.
Há uma longa lista de empresas, do Uber ao Spotify e do Goldman Sachs à Cisco.
Vantagens
- Alto rendimento: ele pode lidar facilmente com um grande volume de dados quando gerar em alta velocidade é uma vantagem excepcional em favor do Kafka. Esta aplicação carece de hardware enorme. Com a capacidade de suportar a taxa de transferência de mensagens com uma frequência de milhares de mensagens por segundo.
- Baixa latência: baixa latência que lida com essa geração de mensagens de alto volume.
- Tolerância a falhas: esse recurso é muito útil, pois possui um recurso inerente a ser restringido pelo nó incorporado em um cluster.
- Durável: é muito durável em sua operação e é por isso que muitas empresas multinacionais preferem usar o Kafka. Falando em durabilidade nas operações, as mensagens não podem se perder a longo prazo.
Habilidades necessárias
Não existe um requisito especial para ser um profissional Kafka. Mas destacamos alguns fluxos e profissionais -
- Desenvolvedores que desejam fazer carreira no fluxo de Big Data e desejam acelerar a carreira lá.
- O profissional de teste tem um bom escopo em Kafka em termos de sistemas de enfileiramento de mensagens e
- Arquitetos - já que tudo precisa de alguma estrutura e essa estrutura pode ser atualizada periodicamente. Os arquitetos de Big Data considerariam Kafka como um bom investimento na carreira.
- O gerente de projeto é necessário se o profissional acima estiver presente para um melhor gerenciamento dos recursos. Portanto, posições mais altas também estão disponíveis para os profissionais de gerenciamento no campo de Kafka.
Por que usar Kafka?
Com o objetivo de rastrear e manipular os dados de acordo com a necessidade do negócio, Kafka é o preferido em todo o mundo. Oferece a possibilidade de transmitir dados em tempo real com análises em tempo real. É rápido, escalável e durável e projetado como tolerância a falhas. Existem vários casos de uso presentes na Web, nos quais é possível ver por que o JMS, o RabbitMQ e o AMQP nem sequer são considerados para trabalhar, pois é necessário operar um grande volume e capacidade de resposta.
Possui alto desempenho e configuração confiável com características de replicação, o que torna a escolha preferível para trabalhar em sensores de IoT.
A compatibilidade é outro motivo para usá-lo e o tornou aceitável em todo o mundo. Ele pode ser facilmente configurado para funcionar com o aplicativo listado abaixo. Essa combinação é muito vital para muitas empresas desenvolverem negócios e sobreviverem (pois economizam tempo e dinheiro).
- Flume
- Spark Streaming
- HBase
- Spark para ingestão, processamento e análise de dados em tempo real.
- É usado para alimentar o Hadoop BigData
Escopo
Está indo bem em todo o mundo. Bem, não estamos dizendo isso bastante estatísticas. Vamos dar uma olhada -
Estatísticas de salário dos profissionais Kafka - PayScale
- Engenheiro de software - $ 109.825
- Data Engineer - $ 109.580
- Desenvolvedores - $ 81.182
- Engenheiro de dados sênior - $ 127, 836
Conclusão
Atualmente, o Kafka se tornou o padrão de fato quando se trata de análise de dados em tempo real com a mais alta precisão em microssegundos. Apresentamos nossas idéias em termos de dados e detalhes em suporte às tecnologias Kafka. Existem várias empresas grandes que utilizam dados diariamente; para isso, precisam de profissionais para aproveitar esses enormes conjuntos de dados. Com Kafka, pode-se ter certeza de liderar sua carreira em uma análise BigData
Artigos recomendados
Este foi um guia para o que é Kafka. Aqui discutimos o trabalho, o escopo, o crescimento da carreira e as vantagens da Kafka. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- O que é o Apache?
- O que é Big Data e Hadoop?
- O que é o Azure?
- O que é a tecnologia de Big Data?
- Kafka vs Spark | As 5 principais diferenças
- Visão geral e principais aplicativos do Kafka
- Kafka vs Kinesis | 5 diferenças com infográficos