
Introdução ao AWS Data Pipeline
Os dados crescem exponencialmente dia a dia e se tornam difíceis de gerenciar em comparação com o passado. Precisamos de ferramentas e serviços para gerenciar nossos dados com eficiência e a um custo mais barato; é aí que o AWS Data Pipeline se refere. Não se trata apenas de armazenar dados, mas você precisa analisar, processar, transformar os dados no formulário desejado no mesmo local, tudo isso pode ser alcançado com o AWS Data Pipeline.
Necessidade de pipeline de dados
Vamos tentar entender a necessidade de pipeline de dados com o exemplo:
Exemplo 1
Temos um site que exibe imagens e gifs com base em pesquisas ou filtros de usuários. Nosso foco principal é servir conteúdo. Existem alguns objetivos a serem alcançados:
- Melhorando a entrega de conteúdo: servindo o que os usuários desejam com eficiência e rapidez suficiente.
- Gerenciar o aplicativo com eficiência: Armazenando os dados do usuário e os logs do site para fins analíticos posteriores.
- Melhorar os negócios: o uso dos dados e análises armazenados toma a decisão de melhorar os negócios a um custo mais barato.
Exemplo 2
Certos gargalos a serem resolvidos para alcançar os objetivos:
- A enorme quantidade de dados em diferentes formatos e lugares diferentes, o que torna complexa a tarefa de processar, armazenar e migrar dados.
Diferentes componentes de armazenamento de dados para diferentes tipos de dados:
- Possíveis dados em tempo real para os usuários registrados: Dynamo DB .
- Logs do servidor da Web para usuários em potencial: Amazon S3 .
- Dados demográficos e credenciais de login: Amazon RDS.
- Dados do sensor e conjunto de dados de terceiros: Amazon S3.
Soluções
- Solução viável: podemos ver que precisamos lidar com diferentes tipos de ferramentas para converter dados de não estruturados em estruturados para análise. Aqui temos que usar ferramentas diferentes para armazenar dados e novamente converter, analisar e armazenar dados processados. Não é uma solução econômica.
- Solução ideal: use um pipeline de dados que lide com processamento, visualização e migração. O pipeline de dados pode ser útil na migração de dados de locais diferentes, analisando também dados e processamento no mesmo local em seu nome.
O que é o pipeline de dados da AWS?
O AWS Data Pipeline é basicamente um serviço da Web oferecido pela Amazon que ajuda a transformar, processar e analisar seus dados de maneira escalável e confiável, além de armazenar dados processados no S3, DynamoDb ou banco de dados local.
- Com o AWS Data Pipeline, você pode acessar facilmente dados de diferentes fontes.
- Transforme e processe esses dados em escala.
- Transfira com eficiência resultados para outros serviços, como S3, tabela DynamoDb ou armazenamento de dados local.
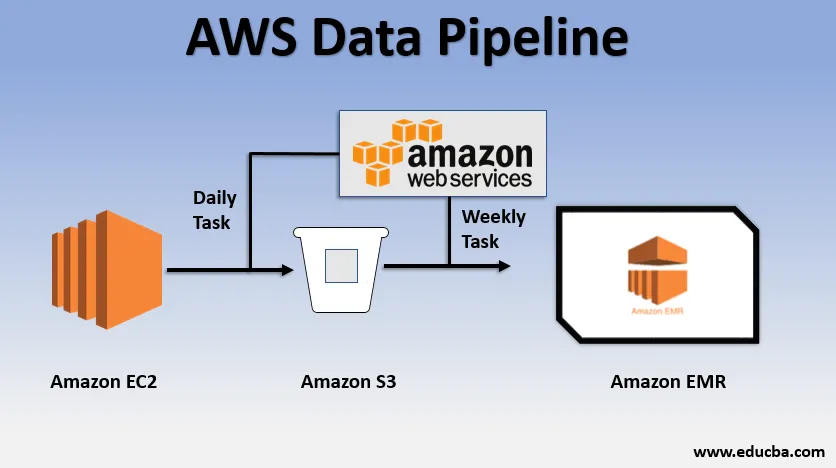
Exemplo de uso básico do pipeline de dados
- Poderíamos ter um site implantado no EC2, que gera logs todos os dias.
- Uma tarefa diária simples pode ser copiada dos arquivos de log do E2 e alcançá-los no bucket S3.
- Uma tarefa semanal poderia ser processar os dados e iniciar a análise de dados no Amazon EMR para gerar relatórios semanais com base em todos os dados coletados.
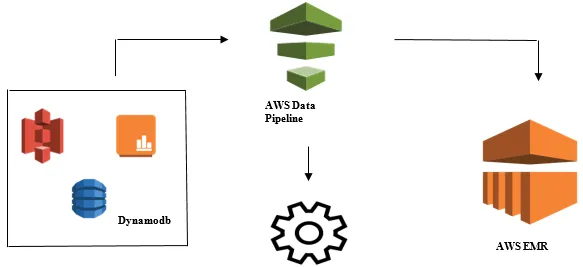
Iniciando a análise de dados com o AWS Data Pipeline
- Coleta de dados de diferentes fontes de dados, como - S3, Dynamodb, Local, dados do sensor etc.
- Execução de transformação, processamento e análise no AWS EMR para gerar relatórios semanais.
- Relatório semanal salvo no Redshift, S3 ou banco de dados local.
Benefícios do AWS Data Pipeline
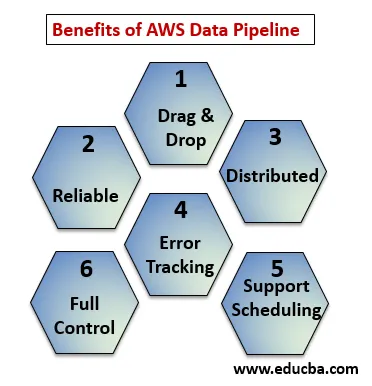
Abaixo os pontos explicam os benefícios do AWS Data Pipeline:
- Console de arrastar e soltar, fácil de entender e usar.
- Infraestrutura distribuída e confiável: os pipelines de dados são executados em serviços escalonáveis e são confiáveis se qualquer erro ou tarefa falhar, ele pode ser configurado para tentar novamente.
- Suporta agendamento e rastreamento de erros: você pode agendar suas tarefas e rastreá-las o que obteve falha e sucesso.
- Distribuído: Pode ser executado paralelamente em várias máquinas ou de maneira linear.
- Controle total sobre recursos computacionais como EC2, clusters de EMR.
Componentes do AWS Data Pipeline
Abaixo estão os componentes do AWS Data Pipeline:
1. Definição de Pipeline
Converta sua lógica de negócios no AWS Data Pipeline.
- Nós de dados : contém o nome, o local e o formato da fonte de dados (S3, dynamodb, local)
- Atividades : mover, transformar ou executar consultas em seus dados.
- Horário : Programe suas atividades diárias ou semanais.
- Pré-condição : condições como iniciar o agendador verificam a disponibilidade dos dados na origem.
- Recursos : Calcular recursos EC2, EMR.
- Ações : atualização sobre o pipeline de dados, envio de notificações, alarme de acionamento.
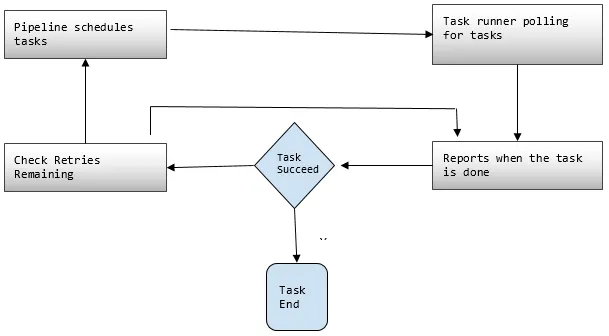
2. Oleodutos
Aqui você agenda e executa as tarefas para executar atividades definidas.
- Oponentes C do pipeline: Os componentes do pipeline são iguais aos componentes da definição de pipeline.
- Instâncias: durante a execução de tarefas, a AWS compila todos os componentes para criar determinadas instâncias acionáveis. Tais instâncias têm todas as informações sobre tarefas específicas.
- Tentativas: Já discutimos a confiabilidade do Data Pipeline com seus mecanismos de nova tentativa. Aqui você define quantas vezes deseja repetir a tarefa, caso ela falhe.
3. Executor de Tarefas
Solicita ou pesquisa tarefas do AWS Data Pipeline e, em seguida, executa essas tarefas.
Preços do AWS Data Pipeline
Abaixo os pontos explicam os preços do pipeline da AWS Data:
1. Nível Grátis
Você pode começar a usar o AWS Data Pipeline gratuitamente, como parte do nível de uso gratuito da AWS. Novos clientes de inscrição recebem todos os meses alguns benefícios gratuitos por um ano:
- 3 Pré-condições de baixa frequência em execução na AWS sem nenhum custo.
- 5 Atividades de baixa frequência em execução na AWS sem nenhum custo.
2. Baixa frequência
A baixa frequência deve funcionar uma vez em um dia ou menos. O Data Pipeline segue a mesma estratégia de cobrança de outros serviços da web da AWS, ou seja, cobrada pelo seu uso. É cobrado com que frequência suas tarefas, atividades e pré-condições são executadas todos os dias e onde elas são executadas (AWS ou local). As atividades de alta frequência estão programadas para serem executadas mais de uma vez por dia.
Exemplo: podemos agendar uma atividade para ser executada a cada hora e processar os logs do site ou a cada 12 horas. Visto que atividades de baixa frequência são aquelas que são executadas uma vez por dia ou menos, se as condições prévias não forem cumpridas; Os dutos inativos têm estados INATIVO, PENDENTE e FINALIZADO.
3. Preço do pipeline de dados da AWS mostrado por região
Região # 1: Leste dos EUA (N.Virginia), Oeste dos EUA (Oregon), Ásia-Pacífico (Sydney), UE (Irlanda)
| Alta frequência | Baixa frequência | |
| Atividades ou pré-condições executando a AWS | US $ 1, 00 por mês | US $ 0, 06 por mês |
| Atividades ou pré-condições em execução no local | US $ 2, 50 por mês | US $ 1, 50 por mês |
| Pipelines inativos: US $ 1, 00 por mês |
Região # 2: Ásia-Pacífico (Tóquio)
| Alta frequência | Baixa frequência | |
| Atividades ou pré-condições executando a AWS | $ 0.9524 por mês | US $ 0, 5715 por mês |
| Atividades ou pré-condições em execução no local | US $ 2.381 por mês | US $ 1.4286 por mês |
| Pipelines inativos: $ 0, 9524 por mês |
O pipeline de que um trabalho diário, ou seja, uma atividade de baixa frequência na AWS para mover dados da tabela do DynamoDB para o Amazon S3, custaria US $ 0, 60 por mês. Se adicionarmos o EC2 para produzir um relatório com base nos dados do Amazon S3, o custo total do pipeline seria de US $ 1, 20 por mês. Se executarmos essa atividade a cada 6 horas, custará US $ 2, 00 por mês, porque seria uma atividade de alta frequência.
Conclusão
O AWS Data Pipeline é uma solução muito útil para gerenciar dados que crescem exponencialmente a um custo mais barato. É muito confiável e escalável de acordo com o seu uso. Para qualquer necessidade comercial em que lide com uma grande quantidade de dados, o AWS Data Pipeline é uma ótima opção para atingir todas as nossas metas comerciais.
Artigos recomendados
Este é um guia para o AWS Data Pipeline. Aqui discutimos as necessidades do pipeline de dados, o que é o pipeline de dados da AWS, seus detalhes de componentes e preços. Você também pode consultar nossos outros artigos relacionados para saber mais -
- AWS EBS
- Bancos de dados da AWS
- O que é o AWS EC2?
- Benefícios da visualização de dados
- Os 7 principais concorrentes da AWS com recursos
- Aprenda a lista de recursos do Amazon Web Services