

Diferença entre Hadoop e Hive
Hadoop:
O Hadoop é um Framework ou Software que foi inventado para gerenciar grandes dados ou Big Data. O Hadoop é usado para armazenar e processar os grandes dados distribuídos em um cluster de servidores comuns.
O Hadoop armazena os dados usando o sistema de arquivos distribuídos Hadoop e os processa / consulta usando o modelo de programação Map Reduce.
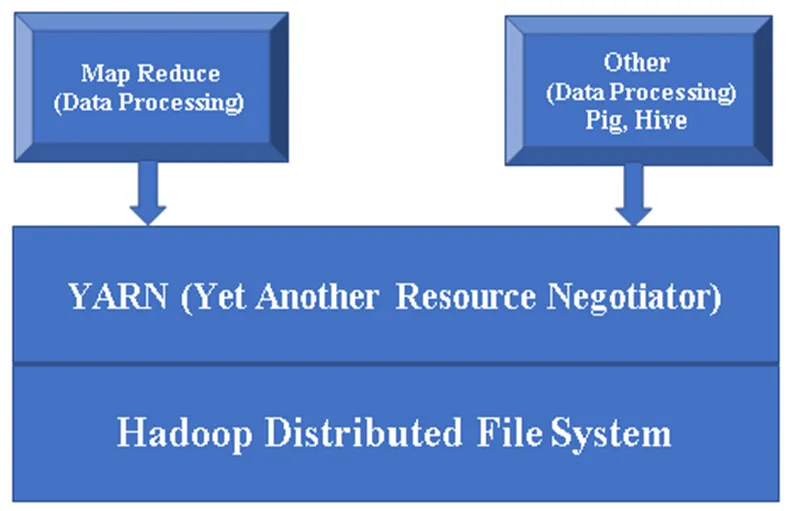
Figura 1, uma arquitetura básica de um componente Hadoop.
Principais componentes do Hadoop:
Hadoop Base / Common: O Hadoop common fornecerá uma plataforma para instalar todos os seus componentes.
HDFS (Sistema de arquivos distribuídos do Hadoop): O HDFS é uma parte importante da estrutura do Hadoop, que cuida de todos os dados no Hadoop Cluster. Ele funciona na arquitetura Master / Slave e armazena os dados usando a replicação.
Arquitetura / Replicação de Mestre / Escravo:
- Nó Mestre / Nó Nome: o nó Nome armazena os metadados de cada bloco / arquivo armazenado no HDFS, o HDFS pode ter apenas um Nó Mestre (no caso de HA, outro Nó Mestre funcionará como Nó Mestre Secundário).
- Nó escravo / nó de dados: os nós de dados contêm arquivos de dados reais em blocos. O HDFS pode ter vários nós de dados.
- Replicação: O HDFS armazena seus dados dividindo-os em blocos. O tamanho padrão do bloco é 64 MB. Devido à replicação, os dados são armazenados em 3 (fator de replicação padrão, pode ser aumentado conforme o requisito) diferentes nós de dados, portanto, há a menor possibilidade de perda dos dados em caso de falha do nó.
YARN (ainda outro negociador de recursos): Ele é basicamente usado para gerenciar recursos do Hadoop e também desempenha um papel importante no agendamento do aplicativo dos usuários.
MR (Map Reduce): este é o modelo de programação básico do Hadoop. É usado para processar / consultar os dados na estrutura do Hadoop.
Colmeia:
O Hive é um aplicativo que é executado na estrutura do Hadoop e fornece uma interface semelhante ao SQL para processar / consultar os dados. O Hive foi projetado e desenvolvido pelo Facebook antes de se tornar parte do projeto Apache-Hadoop.
O Hive executa sua consulta usando o HQL (Hive query language). O Hive está tendo a mesma estrutura que o RDBMS e quase os mesmos comandos podem ser usados no Hive.
O Hive pode armazenar os dados em tabelas externas, portanto, não é obrigatório usar o HDFS, também suporta formatos de arquivo como ORC, Avro, Sequence File e Text, etc.
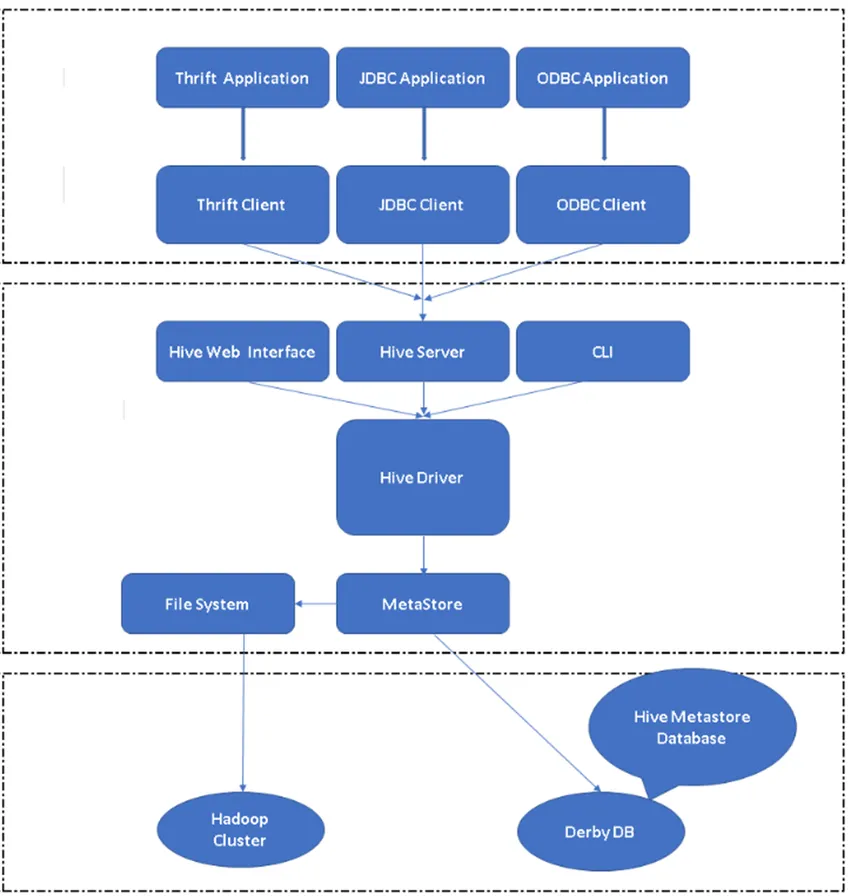
Figura 2, Arquitetura da Hive e seus principais componentes.
Componente principal da Hive:
Clientes Hive: Não apenas o SQL, o Hive também suporta linguagens de programação como Java, C, Python usando vários drivers, como ODBC, JDBC e Thrift. É possível escrever qualquer aplicativo cliente do hive em outros idiomas e executar no Hive usando esses clientes.
Serviços de Hive: Nos serviços de Hive, a execução de comandos e consultas ocorre. A interface da web do Hive possui cinco subcomponentes.
- CLI: Interface de linha de comando padrão fornecida pelo Hive para execução de consultas / comandos do Hive.
- Hive Web Interfaces: É uma interface gráfica de usuário simples. É uma alternativa à linha de comando do Hive e é usada para executar as consultas e comandos no aplicativo Hive.
- Hive Server: Também é chamado de Apache Thrift. É responsável por receber comandos de diferentes interfaces de linha de comando e enviar todos os comandos / consultas ao Hive, além de recuperar o resultado final.
- Driver Apache Hive: É responsável por receber as entradas da CLI, da interface da Web, ODBC, JDBC ou interfaces Thrift por um cliente e passar as informações ao metastore, onde todas as informações do arquivo estão armazenadas.
- Metastore: o Metastore é um repositório para armazenar todas as informações de metadados do Hive. Os metadados do Hive armazenam informações como estrutura de tabelas, partições e tipo de coluna, etc.
Armazenamento do Hive: é o local em que a tarefa real é executada. Todas as consultas executadas no Hive executaram a ação no armazenamento do Hive.
Comparação cara a cara entre Hadoop x Hive (Infográficos)
Abaixo está a diferença top 8 entre Hadoop e Hive
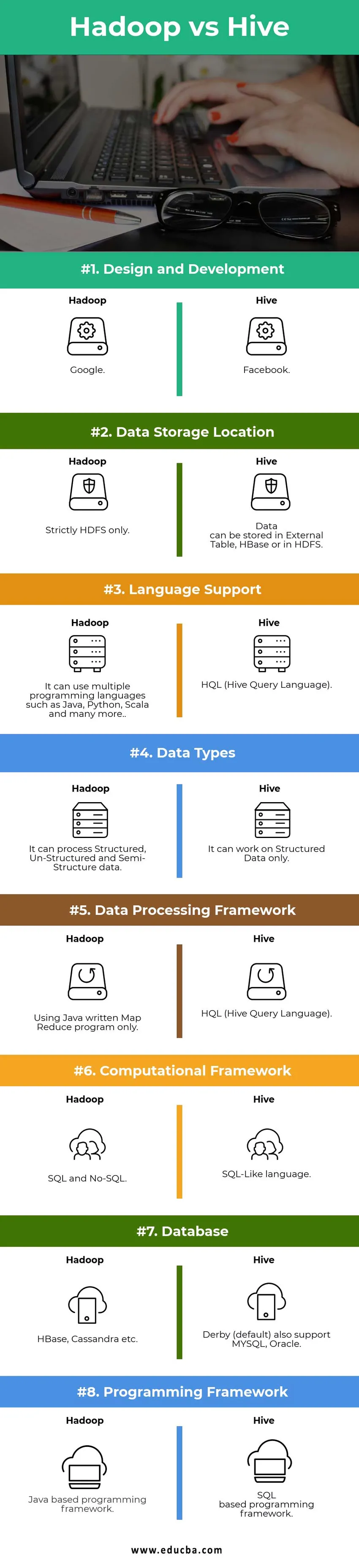
Principais diferenças entre o Hadoop e o Hive:
Abaixo estão as listas de pontos, descreva as principais diferenças entre o Hadoop e o Hive:
1) O Hadoop é uma estrutura para processar / consultar Big Data, enquanto o Hive é uma ferramenta baseada em SQL que se baseia no Hadoop para processar os dados.
2) O Hive processa / consulta todos os dados usando o HQL (Hive Query Language), que é semelhante ao SQL, enquanto o Hadoop pode entender apenas o Map Reduce.
3) Map Reduce é parte integrante do Hadoop, a consulta do Hive é primeiro convertida em Map Reduce do que processada pelo Hadoop para consultar os dados.
4) O Hive funciona na consulta SQL Like, enquanto o Hadoop a entende usando apenas o Map Reduce baseado em Java.
5) No Hive, os comandos tradicionais "Banco de Dados Relacional" usados anteriormente também podem ser usados para consultar os big data, enquanto no Hadoop, é necessário escrever programas complexos de Map Reduce usando Java que não são semelhantes aos tradicionais Java.
6) O Hive pode processar / consultar apenas os dados estruturados, enquanto o Hadoop é destinado a todos os tipos de dados, sejam eles Estruturados, Não Estruturados ou Semi-Estruturados.
7) Usando o Hive, é possível processar / consultar os dados sem programação complexa, enquanto no ecossistema do Simple Hadoop, é necessário escrever um programa Java complexo para os mesmos dados.
8) As estruturas Hadoop de um lado precisam da linha 100s para preparar o programa MR baseado em Java; do outro lado, o Hadoop com o Hive pode consultar os mesmos dados usando 8 a 10 linhas de HQL.
9) No Hive, é muito difícil inserir a saída de uma consulta como entrada de outra, enquanto a mesma consulta pode ser feita facilmente usando o Hadoop com MR.
10) Não é obrigatório ter o Metastore no cluster do Hadoop Enquanto o Hadoop armazena todos os seus metadados no HDFS (Hadoop Distributed File System).
Tabela de comparação Hadoop vs Hive
| Pontos de Comparação | Colmeia | Hadoop |
|
Design e desenvolvimento | ||
| Local de armazenamento de dados |
Os dados podem ser armazenados em External Tabela, HBase ou em HDFS. | Apenas estritamente HDFS. |
| Suporte de linguas | HQL (Hive Query Language) |
Ele pode usar várias linguagens de programação, como Java, Python, Scala e muito mais. |
| Tipos de dados | Ele pode funcionar apenas com dados estruturados. |
Ele pode processar dados estruturados, não estruturados e semiestruturados. |
| Estrutura de processamento de dados |
HQL (Hive Query Language) | Utilizando apenas o programa Map Reduce escrito em Java. |
|
Estrutura Computacional | Linguagem semelhante a SQL. | SQL e No-SQL. |
| Base de dados |
O Derby (padrão) também suporta MYSQL, Oracle… | HBase, Cassandra etc…. |
| Estrutura de programação |
Framework de programação baseado em SQL. | Estrutura de programação baseada em Java. |
Conclusão - Hadoop vs Hive
O Hadoop e o Hive são usados para processar o Big Data. O Hadoop é uma estrutura que fornece plataforma para outros aplicativos consultarem / processarem o Big Data, enquanto o Hive é apenas um aplicativo baseado em SQL que processa os dados usando o HQL (Hive Query Language)
O Hadoop pode ser usado sem o Hive para processar os grandes dados, embora não seja fácil usar o Hive sem o Hadoop.
Como conclusão, não podemos comparar o Hadoop e o Hive de qualquer maneira e em qualquer aspecto. O Hadoop e o Hive são completamente diferentes. A execução da tecnologia em conjunto pode tornar o processo de consulta de Big Data muito mais fácil e confortável para os usuários de Big Data.
Artigos recomendados:
Este foi um guia para o Hadoop vs Hive, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- Hadoop vs Apache Spark - coisas interessantes que você precisa saber
- HADOOP vs RDBMS | Conheça as 12 diferenças úteis
- Como o Big Data está mudando a cara da assistência médica
- Top 12 Comparação de Apache Hive vs Apache HBase (Infographics)
- Guia incrível no Hadoop vs Spark