
Introdução ao ciclo de vida do Machine Learning (ML)
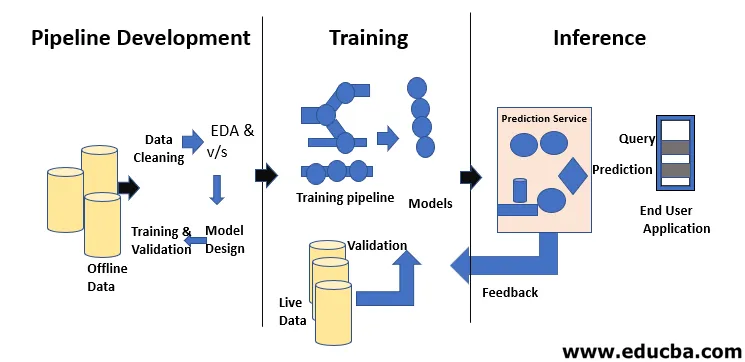
O Ciclo de Vida do Machine Learning é sobre a aquisição de conhecimento por meio de dados. O ciclo de vida do aprendizado de máquina descreve um processo trifásico usado por cientistas e engenheiros de dados para desenvolver, treinar e servir modelos. O desenvolvimento, treinamento e serviço de modelos de aprendizado de máquina é o resultado de um processo chamado ciclo de vida de aprendizado de máquina. É um sistema que utiliza dados como entrada, tendo a capacidade de aprender e melhorar o uso de algoritmos sem ser programado para isso. O ciclo de vida do aprendizado de máquina possui três fases, conforme mostrado na figura abaixo: desenvolvimento de pipeline, treinamento e inferência.
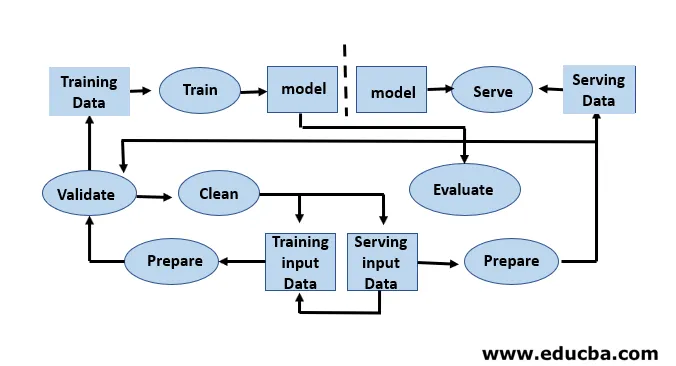
A primeira etapa do ciclo de vida do aprendizado de máquina consiste em transformar dados brutos em um conjunto de dados limpo, que geralmente é compartilhado e reutilizado. Se um analista ou um cientista de dados que encontrar problemas nos dados recebidos, precisará acessar os dados originais e os scripts de transformação. Há vários motivos pelos quais podemos retornar às versões anteriores de nossos modelos e dados. Por exemplo, encontrar a melhor versão anterior pode exigir a pesquisa em muitas versões alternativas, pois os modelos degradam inevitavelmente seu poder preditivo. Há muitas razões para essa degradação, como uma mudança na distribuição de dados que pode resultar em um rápido declínio no poder preditivo como compensação por erros. Diagnosticar esse declínio pode exigir a comparação de dados de treinamento com dados ativos, a reciclagem do modelo, a revisão de decisões anteriores do projeto ou a reformulação do modelo.
Aprendendo com erros
O desenvolvimento de modelos requer treinamento separado e conjuntos de dados de teste. O uso excessivo de dados de teste durante o treinamento pode levar a uma generalização e desempenho ruins, pois podem levar a um ajuste excessivo. O contexto desempenha um papel vital aqui, portanto, é necessário entender quais dados foram usados para treinar os modelos pretendidos e com quais configurações. O ciclo de vida do aprendizado de máquina é orientado por dados, porque o modelo e a saída do treinamento estão vinculados aos dados nos quais foram treinados. Uma visão geral de um pipeline de aprendizado de máquina de ponta a ponta com um ponto de vista de dados é mostrada na figura abaixo:
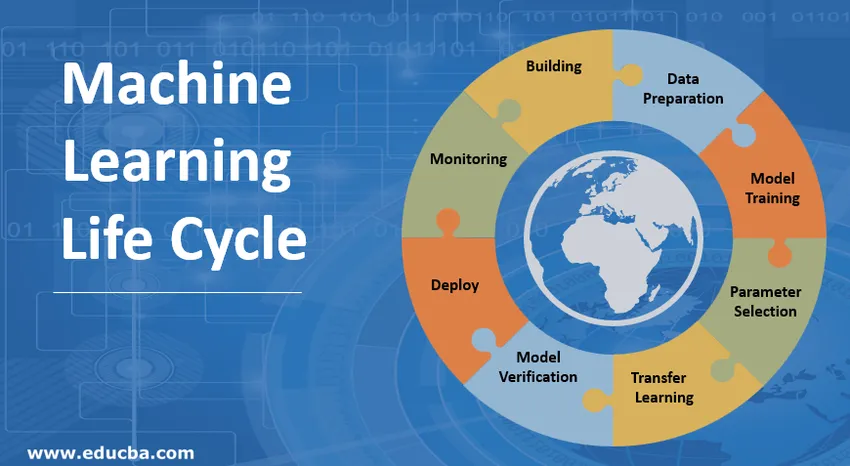
Etapas envolvidas no ciclo de vida do Machine Learning
O desenvolvedor do Machine Learning realiza constantemente experimentação com novos conjuntos de dados, modelos, bibliotecas de software, parâmetros de ajuste para otimizar e aprimorar a precisão do modelo. Como o desempenho do modelo depende completamente dos dados de entrada e do processo de treinamento.
1. Construindo o modelo de aprendizado de máquina
Esta etapa decide o tipo de modelo com base no aplicativo. Ele também conclui que a aplicação do modelo no estágio de aprendizado do modelo, para que eles possam ser projetados adequadamente, de acordo com a necessidade de um aplicativo pretendido. Uma variedade de modelos de aprendizado de máquina está disponível, como modelo supervisionado, modelo não supervisionado, modelos de classificação, modelos de regressão, modelos de cluster e modelos de aprendizado por reforço. Uma visão detalhada é mostrada na figura abaixo:
2. Preparação de Dados
Uma variedade de dados pode ser usada como entrada para fins de aprendizado de máquina. Esses dados podem vir de várias fontes, como empresas, empresas farmacêuticas, dispositivos de IoT, empresas, bancos, hospitais etc. Um grande volume de dados é fornecido no estágio de aprendizado da máquina, pois, à medida que o número de dados aumenta, ele se alinha com os produzindo os resultados desejados. Esses dados de saída podem ser usados para análise ou alimentados como entrada em outros aplicativos ou sistemas de aprendizado de máquina para os quais atuarão como uma semente.
3. Treinamento do Modelo
Esse estágio está relacionado à criação de um modelo a partir dos dados fornecidos a ele. Nesta fase, uma parte dos dados de treinamento é usada para encontrar parâmetros do modelo, como os coeficientes de um polinômio ou pesos no aprendizado de máquina, o que ajuda a minimizar o erro para o conjunto de dados fornecido. Os dados restantes são usados para testar o modelo. Essas duas etapas geralmente são repetidas várias vezes para melhorar o desempenho do modelo.
4. Seleção de Parâmetros
Envolve a seleção dos parâmetros associados ao treinamento, também chamados de hiperparâmetros. Esses parâmetros controlam a eficácia do processo de treinamento e, portanto, em última análise, o desempenho do modelo depende disso. Eles são muito cruciais para a produção bem-sucedida do modelo de aprendizado de máquina.
5. Transferência de Aprendizado
Como existem muitos benefícios na reutilização de modelos de aprendizado de máquina em vários domínios. Assim, apesar de um modelo não poder ser transferido diretamente entre diferentes domínios diretamente, é usado para fornecer um material de partida para iniciar o treinamento de um modelo de estágio seguinte. Assim, reduz significativamente o tempo de treinamento.
6. Verificação de Modelo
A entrada desse estágio é o modelo treinado produzido pelo estágio de aprendizado do modelo e a saída é um modelo verificado que fornece informações suficientes para permitir que os usuários determinem se o modelo é adequado para a aplicação pretendida. Portanto, esse estágio do ciclo de vida do aprendizado de máquina se preocupa com o fato de um modelo estar funcionando corretamente quando tratado com entradas que não são vistas.
7. Implemente o modelo de aprendizado de máquina
Nesta fase do ciclo de vida do aprendizado de máquina, aplicamos a integração de modelos de aprendizado de máquina em processos e aplicativos. O objetivo final desse estágio é a funcionalidade adequada do modelo após a implantação. Os modelos devem ser implantados de forma que possam ser usados para inferência, bem como devem ser atualizados regularmente.
8. Monitoramento
Envolve a inclusão de medidas de segurança para garantir o funcionamento correto do modelo durante sua vida útil. Para que isso aconteça, é necessário gerenciamento e atualização adequados.
Vantagem do ciclo de vida do aprendizado de máquina
O aprendizado de máquina fornece os benefícios de potência, velocidade, eficiência e inteligência por meio do aprendizado sem programá-los explicitamente em um aplicativo. Oferece oportunidades para melhor desempenho, produtividade e robustez.
Conclusão - Ciclo de vida do aprendizado de máquina
Os sistemas de aprendizado de máquina estão se tornando mais importantes dia a dia, à medida que a quantidade de dados envolvidos em vários aplicativos aumenta rapidamente. A tecnologia de aprendizado de máquina é o coração de dispositivos inteligentes, eletrodomésticos e serviços online. O sucesso do aprendizado de máquina pode ser estendido ainda mais a sistemas críticos de segurança, gerenciamento de dados e computação de alto desempenho, com grande potencial para domínios de aplicativos.
Artigos recomendados
Este é um guia para o Ciclo de Vida do Aprendizado de Máquina. Aqui discutimos a introdução, Aprendendo com erros, etapas envolvidas no ciclo de vida e nas vantagens do Machine Learning Você também pode consultar nossos outros artigos sugeridos para saber mais:
- Empresas de Inteligência Artificial
- Análise do conjunto QlikView
- Ecossistema de IoT
- Modelagem de Dados Cassandra