

Diferença entre Apache Nifi e Apache Spark
Até muito tempo, quando havia um trabalho pesado que precisava ser concluído, as pessoas contavam com cavalos para puxar cargas pesadas, manter a velocidade ou qualquer outra coisa no meio. No entanto, nem todos os cavalos estavam aptos para todas as tarefas. O mesmo acontece com a tecnologia hoje. Com o advento de novas tecnologias chegando todos os dias, torna-se extremamente importante conhecer suas aplicações reais. Duas dessas tecnologias são o Apache Nifi e o Apache Spark e vamos estudar sobre elas neste post.
O Apache Spark é uma estrutura de código aberto de computação de cluster que visa fornecer uma interface para a programação de todo o conjunto de clusters com tolerância implícita a falhas e paralelismo de dados. Ele utiliza RDDs (conjuntos de dados distribuídos resilientes) e processa os dados na forma de fluxos discretos, que são utilizados ainda para fins analíticos.
O Apache Nifi (que é a forma abreviada de NiagaraFiles) é outro projeto de software que visa automatizar o fluxo de dados entre sistemas de software. O design é baseado no modelo de programação baseado em fluxo, que fornece recursos que incluem a operação com capacidade de clusters. É um sistema fácil de usar, confiável e poderoso para processar e distribuir dados. Ele suporta gráficos direcionados escaláveis para roteamento de dados, mediação do sistema e lógica de transformação. Vamos discutir as comparações de ambos os tópicos.
Comparação cara a cara entre Apache Nifi vs Apache Spark (Infographics)
Abaixo está o top 9 de comparação entre Apache Nifi vs Apache Spark
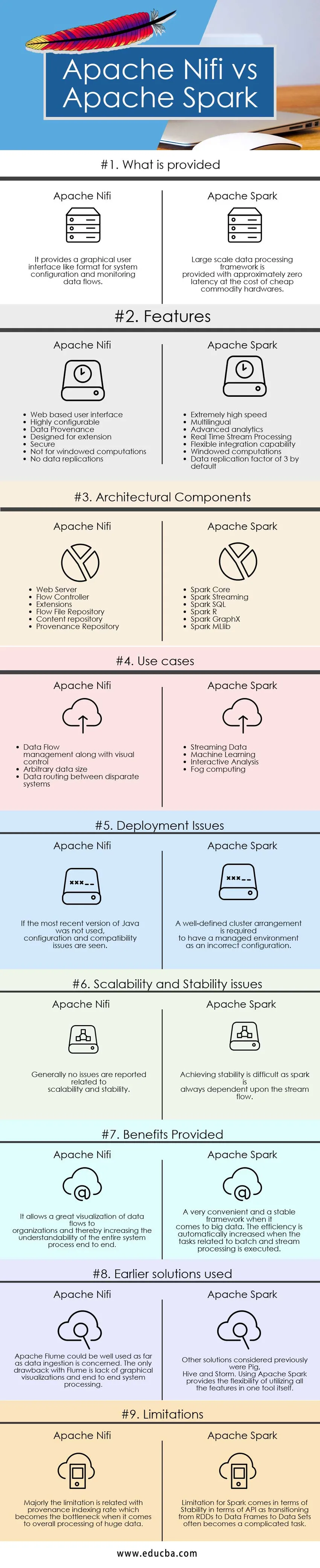
Principais diferenças entre Apache Nifi e Apache Spark
As diferenças entre o Apache Nifi e o Apache Spark são explicadas nos pontos apresentados abaixo:
- O Apache Nifi é uma ferramenta de ingestão de dados usada para fornecer um sistema fácil de usar, poderoso e confiável, para que o processamento e a distribuição de dados por recursos se tornem fáceis, enquanto o Apache Spark é uma tecnologia de computação em cluster extremamente rápida, projetada para uma computação mais rápida por fazendo uso eficiente de consultas interativas, em recursos de gerenciamento de memória e processamento de fluxo.
- O Apache Nifi funciona no modo autônomo e em cluster, enquanto o Apache Spark funciona bem no modo local ou autônomo, Mesos, Yarn e outros tipos de modos de cluster de big data.
- Os recursos do Apache Nifi incluem entrega garantida de dados, buffer eficiente de dados, enfileiramento priorizado, QoS específico de fluxo, proveniência de dados, recuperação de buffer Roll, comando e controle visual, modelos de fluxo, segurança e recursos de fluxo paralelo, enquanto os recursos do apache spark incluem Lightning fast capacidade de processamento de velocidade, computação multilíngue, na memória, utilização eficiente de sistemas de hardware comuns, análise avançada, capacidade de integração eficiente.
- O Apache Nifi permite uma melhor legibilidade e entendimento geral do sistema, fornecendo recursos de visualização e recursos de arrastar e soltar. O fluxo de dados pode ser facilmente gerenciado e controlado usando técnicas e processos convencionais; no caso do Apache Spark, para visualizar esses tipos de visualizações, é necessário um sistema de gerenciamento de cluster como o Ambari. O Apache Spark, por si só, não fornece recursos de visualização e é bom apenas no que diz respeito à programação. É de longe um sistema muito conveniente e estável para processar grandes quantidades de dados.
- A limitação do Apache Nifi está relacionada à sua vantagem. O único recurso de arrastar e soltar fornece uma limitação de não poder escalar e fornecer robustez quando se trata de integrá-lo a outros componentes e ferramentas. No caso do Apache Spark, a principal limitação é o uso de hardware comum extensivo e seu gerenciamento. torna-se uma tarefa tediosa às vezes. A outra limitação relatada vem junto com seus recursos de streaming relacionados a Fluxo discreto e Windowed ou fluxo em lote, onde a transformação de RDDs em quadros de dados e conjuntos de dados fornece uma causa de instabilidade às vezes.
Tabela de comparação Apache Nifi vs Apache Spark
| Base de comparação | Apache Nifi | Apache Spark |
| O que é fornecido | Ele fornece uma interface gráfica com o usuário, como um formato para configuração do sistema e monitoramento de fluxos de dados. | A estrutura de processamento de dados em larga escala é fornecida com latência aproximadamente zero ao custo de hardware de commodity barato. |
| Recursos |
|
|
| Componentes arquitetônicos |
|
|
| Casos de uso |
|
|
| Problemas de implantação | Se a versão mais recente do Java não foi usada, problemas de configuração e compatibilidade são vistos. | É necessário um arranjo de cluster bem definido para ter um ambiente gerenciado como uma configuração incorreta |
| Problemas de escalabilidade e estabilidade | Geralmente, nenhum problema é relatado relacionado à escalabilidade e estabilidade | Alcançar a estabilidade é difícil, pois uma faísca depende sempre do fluxo da corrente. |
| Benefícios oferecidos | Permite uma ótima visualização dos fluxos de dados para as organizações e, assim, aumenta a compreensibilidade de todo o processo do sistema de ponta a ponta | Uma estrutura muito conveniente e estável quando se trata de big data. A eficiência é aumentada automaticamente quando as tarefas relacionadas ao processamento em lote e fluxo são executadas. |
| Soluções anteriores usadas | O Apache Flume pode ser bem utilizado no que diz respeito à ingestão de dados. A única desvantagem do Flume é a falta de visualizações gráficas e o processamento completo do sistema | Outras soluções consideradas anteriormente foram Pig, Hive e Storm. O uso do Apache Spark fornece a flexibilidade de utilizar todos os recursos em uma única ferramenta. |
| Limitações | Principalmente, a limitação está relacionada à taxa de indexação de proveniência, que se torna o gargalo no processamento geral de grandes dados | A limitação do Spark vem em termos de estabilidade em termos de API, pois a transição de RDDs para quadros de dados para conjuntos de dados geralmente se torna uma tarefa complicada. |
Conclusão - Apache Nifi vs Apache Spark
Para concluir o post, pode-se dizer que o Apache Spark é um cavalo de guerra pesado, enquanto o Apache Nifi é um cavalo de corrida ágil. Ambos têm seus próprios benefícios e limitações para serem usados em suas respectivas áreas. Você precisa decidir a ferramenta certa para o seu negócio. Fique ligado no nosso blog para obter mais artigos relacionados às novas tecnologias de big data.
Artigo recomendado
Este foi um guia do Apache Nifi vs Apache Spark, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- Apache Hadoop vs Apache Spark | As 10 melhores comparações que você deve saber!
- Apache Storm vs Apache Spark - Aprenda 15 diferenças úteis
- 7 coisas importantes sobre o Apache Spark (Guia)
- As 15 melhores coisas que você precisa saber sobre o MapReduce vs Spark