
Definição do algoritmo de deslocamento médio
O algoritmo de deslocamento médio se enquadra no aprendizado não supervisionado, que é categorizado como o algoritmo de agrupamento. A ideologia do algoritmo Mean Shift é que iterativamente atribui pontos de dados aos clusters, deslocando-os para o ponto que possui o ponto de densidade mais alto (Modo). A lógica de mudança de base subjacente é baseada no conceito de estimativa de densidade do Kernel conhecido como KDE.
Agrupamento de algoritmos de deslocamento médio
Uma técnica de aprendizado não supervisionado descoberta por Fukunaga e Hostetler para encontrar clusters:
- O deslocamento médio também é conhecido como algoritmo de busca de modo que atribui os pontos de dados aos clusters de uma maneira deslocando os pontos de dados para a região de alta densidade. A maior densidade de pontos de dados é denominada como o modelo na região. O algoritmo Mean Shift tem aplicações amplamente usadas no campo da visão computacional e segmentação de imagens.
- O KDE é um método para estimar a distribuição dos pontos de dados. Ele funciona colocando um kernel em cada ponto de dados. O kernel no termo matemático é uma função de ponderação que aplicará pesos para pontos de dados individuais. Adicionar todo o kernel individual gera a probabilidade.
A função Kernel é necessária para satisfazer as seguintes condições:
- O primeiro requisito é garantir que a estimativa de densidade do kernel seja Normalizada.
- O segundo requisito é que o KDE esteja bem associado à simetria do espaço.
Duas funções populares do kernel
Abaixo estão as duas funções populares do kernel usadas nele:
- Flat Kernel
- Núcleo Gaussiano
- Com base no parâmetro Kernel usado, a função de densidade resultante varia. Se nenhum parâmetro do kernel for mencionado, o Gaussian Kernel será chamado por padrão. O KDE utiliza o conceito de função de densidade de probabilidade, que ajuda a encontrar os máximos locais da distribuição de dados. O algoritmo funciona criando pontos de dados para atrair um ao outro, permitindo que eles aponte para a área de alta densidade.
- Os pontos de dados que tentam convergir para o máximo local serão do mesmo grupo de clusters. Em contraste com o algoritmo de agrupamento K-Means, a saída do algoritmo Mean Shift não depende de suposições sobre a forma do ponto de dados e o número de clusters. O número de clusters será determinado pelo algoritmo em relação aos dados.
- Para executar a implementação do algoritmo Mean Shift, usamos o pacote python SKlearn.
Implementação do algoritmo de deslocamento médio
Abaixo está a implementação do algoritmo:
Exemplo 1
Baseado no Tutorial Sklearn para o algoritmo de agrupamento de turnos médios. O primeiro trecho implementará um algoritmo de deslocamento médio para encontrar os clusters do conjunto de dados bidimensional. Pacotes usados para implementar o algoritmo de deslocamento médio.
Código:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Uma coisa importante a ser observada é que usaremos a biblioteca make_blobs do sklearn para gerar pontos de dados centralizados em 3 locais. Para aplicar o algoritmo de deslocamento médio aos pontos gerados, devemos definir a largura de banda que representa a interação entre o comprimento. A Biblioteca do Sklearn possui funções integradas para estimar a largura de banda.
Código:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
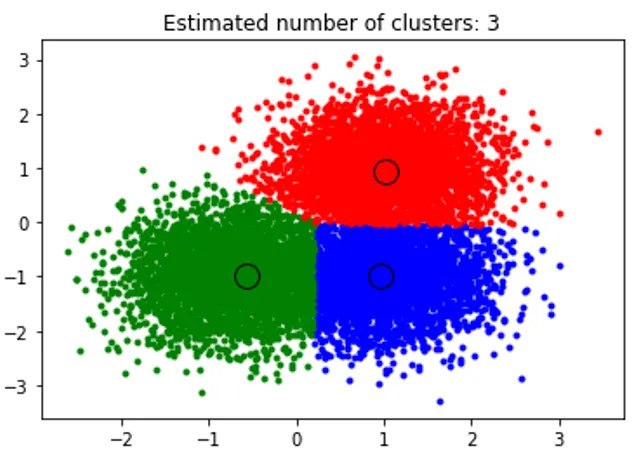
O snippet acima executa cluster e o algoritmo encontrou clusters centralizados em cada blob que geramos. Podemos ver que, na imagem abaixo, plotada pelo trecho, o algoritmo de deslocamento médio é capaz de identificar o número de clusters necessários no tempo de execução e descobrir a largura de banda apropriada para representar a duração da interação.
Resultado:
Exemplo 2
Baseado em Segmentação de Imagem em Visão Computacional. O segundo trecho explorará como o algoritmo de deslocamento médio usado no Deep Learning para realizar a segmentação da imagem colorida. Estamos usando o algoritmo de deslocamento médio para identificar os agrupamentos espaciais. O fragmento anterior que usamos conjunto de dados 2D, enquanto que neste exemplo explorará o espaço 3D. Os pixels da imagem serão tratados como pontos de dados (r, g, b). Precisamos converter a imagem em formato de matriz para que cada pixel represente um ponto de dados na imagem que vamos para o segmento. Agrupar os valores de cores no espaço retorna séries de clusters, em que os pixels no cluster serão semelhantes ao espaço RGB. Pacotes usados para implementar o algoritmo de deslocamento médio:
Código:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Abaixo do snippet para realizar a segmentação da imagem original:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
A imagem gerada afirma que essa abordagem para identificar as formas das imagens e determinar os agrupamentos espaciais pode ser feita de maneira eficaz, sem qualquer processamento de imagem.
Resultado:


Benefícios e Aplicações Algoritmo de Deslocamento Médio
Abaixo estão os benefícios e a aplicação do algoritmo médio:
- É amplamente utilizado para resolver a visão computacional, onde é usado para segmentação de imagens.
- Cluster de pontos de dados em tempo real, sem mencionar o número de clusters.
- Apresenta bom desempenho na segmentação de imagens e rastreamento de vídeo.
- Mais robusto para outliers.
Prós do algoritmo de deslocamento médio
Abaixo estão os profissionais do algoritmo de deslocamento médio:
- A saída do algoritmo é independente das inicializações.
- O procedimento é eficaz, pois possui apenas um parâmetro - Largura de banda.
- Sem suposições sobre o número de clusters de dados e a forma.
- Tem melhor desempenho que o K-Means Clustering.
Contras do algoritmo de deslocamento médio
Abaixo estão os contras do algoritmo de deslocamento médio:
- Caro para grandes recursos.
- Comparado ao cluster K-Means, é muito lento.
- A saída do algoritmo depende da largura de banda do parâmetro.
- A saída depende do tamanho da janela.
Conclusão
Embora seja uma abordagem direta, usada principalmente para resolver problemas relacionados à segmentação de imagens, clustering. É comparativamente mais lento que o K-Means e é computacionalmente caro.
Artigos recomendados
Este é um guia para o algoritmo de deslocamento médio. Aqui discutimos problemas relacionados à segmentação de imagens, clustering, benefícios e duas funções do kernel. Você também pode consultar nossos outros artigos relacionados para saber mais.
- K- significa algoritmo de agrupamento
- Algoritmo KNN em R
- O que é algoritmo genético?
- Métodos do Kernel
- Métodos de kernel no aprendizado de máquina
- Explicação detalhada do algoritmo C ++