

Introdução à junção no Spark SQL
Como sabemos, as junções no SQL são usadas para combinar dados ou linhas de duas ou mais tabelas com base em um campo comum entre elas. Neste tópico, vamos aprender sobre Ingressar no Spark SQL Ingressar no Spark SQL.
No Spark SQL, Dataframe ou Dataset são uma estrutura tabular na memória com linhas e colunas distribuídas por vários nós. Como as tabelas SQL normais, também podemos executar operações de junção no Dataframe ou no Dataset presentes no Spark SQL com base em um campo comum entre elas.
Existem diferentes tipos de operações de junção disponíveis no SQL. Dependendo do caso de uso de negócios, escolhemos a operação Ingressar. Na seção a seguir, demonstraremos cada tipo de junção com o exemplo.
Tipos de junção no Spark SQL
A seguir, estão os diferentes tipos de junções disponíveis no Spark SQL:
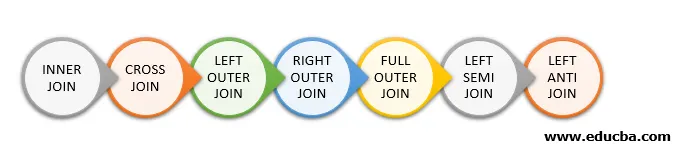
- JUNÇÃO INTERNA
- CROSS JOIN
- JUNTA EXTERNA ESQUERDA
- JUNÇÃO EXTERNA DIREITA
- JUNÇÃO EXTERNA COMPLETA
- SEMI ESQUERDA
- ANTI JOIN ESQUERDA
Exemplo de criação de dados
Usaremos os seguintes dados para demonstrar os diferentes tipos de junções:
Conjunto de dados do livro:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
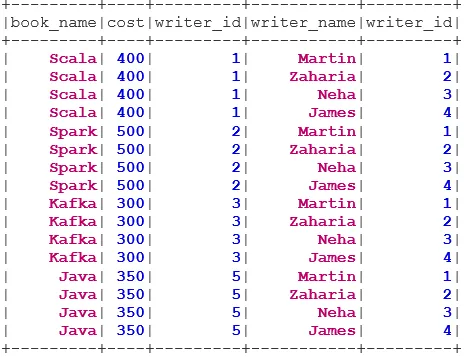
bookDS.show()

Conjunto de dados do gravador:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Tipos de junções
Abaixo são mencionados 7 tipos diferentes de junções:
1. INSCRIÇÃO INTERNA
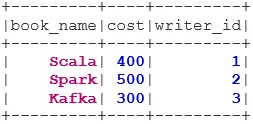
O INNER JOIN retorna o conjunto de dados que possui as linhas que possuem valores correspondentes nos dois conjuntos de dados, ou seja, o valor do campo comum será o mesmo.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. JUNÇÃO TRANSVERSAL
CROSS JOIN retorna o conjunto de dados, que é o número de linhas no primeiro conjunto de dados multiplicado pelo número de linhas no segundo conjunto de dados. Esse tipo de resultado é chamado de produto cartesiano.
Pré-requisito: Para usar uma junção cruzada, spark.sql.crossJoin.enabled deve ser configurado como true. Caso contrário, a exceção será lançada.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. JUNTA EXTERNA ESQUERDA
LEFT OUTER JOIN retorna o conjunto de dados que possui todas as linhas do conjunto de dados esquerdo e as linhas correspondentes do conjunto de dados direito.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. JUNTA EXTERIOR CERTA
O RIGHT OUTER JOIN retorna o conjunto de dados que possui todas as linhas do conjunto de dados direito e as linhas correspondentes do conjunto de dados esquerdo.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. JUNÇÃO EXTERNA COMPLETA
A junção externa completa retorna o conjunto de dados que possui todas as linhas quando há uma correspondência no conjunto de dados esquerdo ou direito.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. JUNTA SEMI ESQUERDA
O LEMI SEMI JOIN retorna o conjunto de dados que tem todas as linhas do conjunto de dados esquerdo que têm sua correspondência no conjunto de dados direito. Diferentemente de LEFT OUTER JOIN, o conjunto de dados retornado em LEFT SEMI JOIN contém apenas as colunas do conjunto de dados esquerdo.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ESQUERDA ANTI-JUNÇÃO
O ANTI SEMI JOIN retorna o conjunto de dados que possui todas as linhas do conjunto de dados esquerdo que não têm correspondência no conjunto de dados correto. Ele também contém apenas as colunas do conjunto de dados esquerdo.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusão - Junte-se ao Spark SQL
A união de dados é uma das operações mais comuns e importantes para atender nosso caso de uso de negócios. O Spark SQL suporta todos os tipos fundamentais de junções. Ao ingressar, precisamos também considerar o desempenho, pois eles podem exigir grandes transferências de rede ou até criar conjuntos de dados além da nossa capacidade de lidar. Para melhorar o desempenho, o Spark usa o otimizador SQL para reordenar ou enviar filtros para baixo. O Spark também restringe a junção perigosa i. e CROSS JOIN. Para usar uma junção cruzada, spark.sql.crossJoin.enabled deve ser definido como true explicitamente.
Artigos recomendados
Este é um guia para ingressar no Spark SQL. Aqui discutimos os diferentes tipos de junções disponíveis no Spark SQL com o exemplo. Você também pode consultar o seguinte artigo.
- Tipos de junções no SQL
- Tabela no SQL
- Consulta de Inserção SQL
- Transações em SQL
- Filtros PHP | Como validar a entrada do usuário usando vários filtros?