
Introdução ao ensacamento e reforço
Ensacamento e Boosting são os dois métodos populares de ensemble. Portanto, antes de entender Bagging e Boosting, vamos ter uma idéia do que é Ensemble Learning. É a técnica de usar vários algoritmos de aprendizado para treinar modelos com o mesmo conjunto de dados para obter uma previsão no aprendizado de máquina. Depois de obter a previsão de cada modelo, usaremos técnicas de média do modelo, como média ponderada, variância ou votação máxima para obter a previsão final. Este método visa obter melhores previsões do que o modelo individual. Isso resulta em melhor precisão, evitando ajustes excessivos e reduz o viés e a covariância. Dois métodos populares de ensemble são:
- Bagging (agregação de bootstrap)
- Impulsionar
Ensacamento:
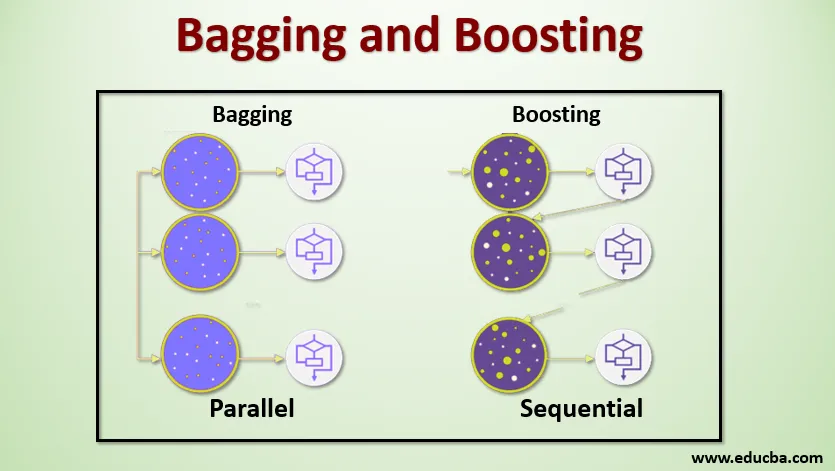
O ensacamento, também conhecido como Agregação de Bootstrap, é usado para melhorar a precisão e tornar o modelo mais generalizado, reduzindo a variação, ou seja, evitando o excesso de ajuste. Neste, pegamos vários subconjuntos do conjunto de dados de treinamento. Para cada subconjunto, adotamos um modelo com os mesmos algoritmos de aprendizado, como árvore de decisão, regressão logística etc. para prever a saída do mesmo conjunto de dados de teste. Depois de obter uma previsão de cada modelo, usamos uma técnica de média do modelo para obter a saída final da previsão. Uma das famosas técnicas usadas no ensacamento é a floresta aleatória . Na floresta Aleatória, usamos várias árvores de decisão.
Impulsionar :
O impulso é usado principalmente para reduzir o viés e a variação de uma técnica de aprendizado supervisionado. Refere-se à família de um algoritmo que converte alunos fracos (aluno de base) em alunos fortes. O aluno fraco é o classificador que está correto apenas em pequena medida com a classificação real, enquanto os alunos fortes são os classificadores que estão bem correlacionados com a classificação real. Poucas técnicas famosas de Boosting são AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Portanto, agora sabemos o que é empacotamento e reforço e quais são seus papéis no Machine Learning.
Trabalho de ensacamento e reforço
Agora vamos entender como funciona o empacotamento e o reforço:
Ensacamento
Para entender o funcionamento do Bagging, suponha que temos um número N de modelos e um conjunto de dados D. Onde m é o número de dados en é o número de recursos em cada dado. E devemos fazer a classificação binária. Primeiro, dividiremos o conjunto de dados. Por enquanto, dividiremos esse conjunto de dados em apenas treinamento e conjunto de testes. Vamos chamar o conjunto de dados de treinamento como onde está o número total de exemplos de treinamento.
Pegue uma amostra dos registros do conjunto de treinamento e use-o para treinar o primeiro modelo, digamos m1. Para o próximo modelo, m2 reamostrar o conjunto de treinamento e coletar outra amostra do conjunto de treinamento. Faremos o mesmo com o número N de modelos. Como estamos reamostrando o conjunto de dados de treinamento e colhendo as amostras sem remover nada do conjunto de dados, é possível que tenhamos dois ou mais registros de dados de treinamento comuns em várias amostras. Essa técnica de reamostrar o conjunto de dados de treinamento e fornecer a amostra ao modelo é denominada Amostragem de Linha com Substituição. Suponha que treinamos cada modelo e agora queremos ver a previsão nos dados de teste. Como estamos trabalhando na classificação binária, a saída pode ser 0 ou 1. O conjunto de dados de teste é passado para cada modelo e obtemos uma previsão de cada modelo. Digamos que, dentre os modelos N, mais do que os modelos N / 2 previam que fosse 1, portanto, usando a técnica de média do modelo como voto máximo, podemos dizer que a saída prevista para os dados de teste é 1.
Impulsionar
Para impulsionar, pegamos os registros do conjunto de dados e os passamos para os alunos de base sequencialmente, aqui os alunos de base podem ser qualquer modelo. Suponha que tenhamos m número de registros no conjunto de dados. Depois, passamos alguns registros para basear o aluno BL1 e treiná-lo. Depois que o BL1 é treinado, passamos todos os registros do conjunto de dados e vemos como o aluno da Base funciona. Para todos os registros que são classificados incorretamente pelo aluno de base, apenas os pegamos e passamos para outro aluno de base, digamos BL2 e, simultaneamente, passamos os registros incorretos classificados por BL2 para treinar BL3. Isso continuará, a menos e até que especifiquemos um número específico de modelos de alunos básicos que precisamos. Por fim, combinamos a saída desses alunos de base e criamos um aluno forte, como resultado, o poder de previsão do modelo é aprimorado. Está bem. Então agora sabemos como funcionam os Ensacamentos e Estímulos.
Vantagens e desvantagens do ensacamento e reforço
Abaixo estão as principais vantagens e desvantagens.
Vantagens do ensacamento
- A maior vantagem do ensacamento é que vários alunos fracos podem trabalhar melhor do que um único aluno forte.
- Ele fornece estabilidade e aumenta a precisão do algoritmo de aprendizado de máquina usado na classificação e regressão estatística.
- Ajuda na redução da variação, ou seja, evita o ajuste excessivo.
Desvantagens do ensacamento
- Isso pode resultar em alto viés se não for modelado corretamente e, portanto, resultar em underfitting.
- Como precisamos usar vários modelos, ele se torna computacionalmente caro e pode não ser adequado em vários casos de uso.
Vantagens de impulsionar
- É uma das técnicas mais bem-sucedidas na solução de problemas de classificação de duas classes.
- É bom em lidar com os dados ausentes.
Desvantagens do impulso
- É difícil implementar o impulso em tempo real devido ao aumento da complexidade do algoritmo.
- A alta flexibilidade dessas técnicas resulta em um número múltiplo de parâmetros que afetam diretamente o comportamento do modelo.
Conclusão
O principal argumento é que o Bagging e o Boosting são um paradigma de aprendizado de máquina no qual usamos vários modelos para resolver o mesmo problema e obter um melhor desempenho. E se combinarmos alunos fracos corretamente, podemos obter um modelo estável, preciso e robusto. Neste artigo, forneci uma visão geral básica de ensacamento e reforço. Nos próximos artigos, você conhecerá as diferentes técnicas usadas em ambos. Por fim, concluirei lembrando que o ensacamento e o reforço estão entre as técnicas mais usadas de aprendizado por conjuntos. A verdadeira arte de melhorar o desempenho está na sua compreensão de quando usar qual modelo e como ajustar os hiperparâmetros.
Artigos recomendados
Este é um guia para ensacamento e reforço. Aqui discutimos a introdução ao ensacamento e reforço e está trabalhando junto com vantagens e desvantagens. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Introdução às Técnicas de Conjunto
- Categorias de algoritmos de aprendizado de máquina
- Algoritmo de aumento de gradiente com código de exemplo
- O que é o algoritmo de impulso?
- Como criar uma árvore de decisão?