

Diferença entre Hadoop e HBase
O Hadoop é uma estrutura Java de código aberto, usada para gerenciar e processar uma enorme quantidade de dados estruturados e não estruturados. O Hadoop é escalável em massa, portanto, é usado para processar cargas de trabalho de Big Data. Big data é armazenado, acessado e processado no cluster confiável e expansível. O HBase (Hadoop Database) é um banco de dados não relacional e não apenas SQL, ou seja, NoSQL, executado na parte superior do Hadoop como um armazenamento de big data distribuído e escalável. É um banco de dados de código aberto no qual os dados são armazenados na forma de linhas e colunas, nessa célula há uma interseção de colunas e linhas.
Abaixo estão os componentes principais da arquitetura Hadoop:
- Sistema de arquivos distribuídos do Hadoop (HDFS): O Hadoop inclui um sistema de armazenamento distribuído, o HDFS (Sistema de arquivos distribuídos do Hadoop). HDFS é a arquitetura mestre-escravo que armazena dados no cluster. Dados distribuídos em vários nós escravos pelo nó mestre no bloco de formulários. O nó principal é chamado Namenode e os nós escravos são chamados Datanode. O HDFS é facilmente expansível e armazena uma enorme quantidade de dados nos Datanodes. O HDFS possui um fator de replicação configurável com o valor padrão 3, que pode ser editável.
- MapReduce: MapReduce é um paradigma de programação, processado em paralelo em um grande número de conjuntos de dados na rede. MapReduce refere-se a duas tarefas diferentes: mapear os dados de entrada nos quais os dados divididos em um subconjunto de dados chamados como tuplas e reduzir a tarefa pegam essas tuplas do mapa como entrada e se combinam para formar a saída do original.
- Fio: YARN significa Ainda outro navegador de recursos que computa recursos como gerencia CPU e memória, agendando solicitações de recursos.
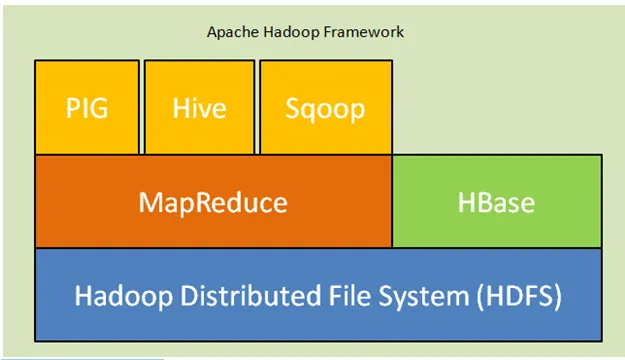
Fig. Estrutura do Apache Hadoop
O servidor da região fornece dados para operações de leitura / gravação. Todos os dados do HBase são armazenados no arquivo HDFS. O HDFS Datanode armazena os dados que o Region Server está gerenciando. O HDFS Namenode mantém informações de metadados para todos os blocos de dados físicos que compõem os arquivos.
O controle de versão é usado para rastrear alterações na célula, que mantém a versão do controle de conteúdo. A partir disso, qualquer versão do conteúdo pode ser recuperada. Cada valor da célula inclui o atributo 'version' em relação ao registro de data e hora para recuperar a célula. Cada valor no mapa é uma matriz ininterrupta de bytes. O mapa é indexado por uma chave de linha, chave de coluna e um registro de data e hora. A arquitetura do HBase é altamente escalável, esparsa, distribuída, persistente e com mapas multidimensionais.
Comparação cara a cara entre Hadoop x HBase (Infográficos)
Abaixo está a diferença entre os 7 principais entre o Hadoop e o HBase
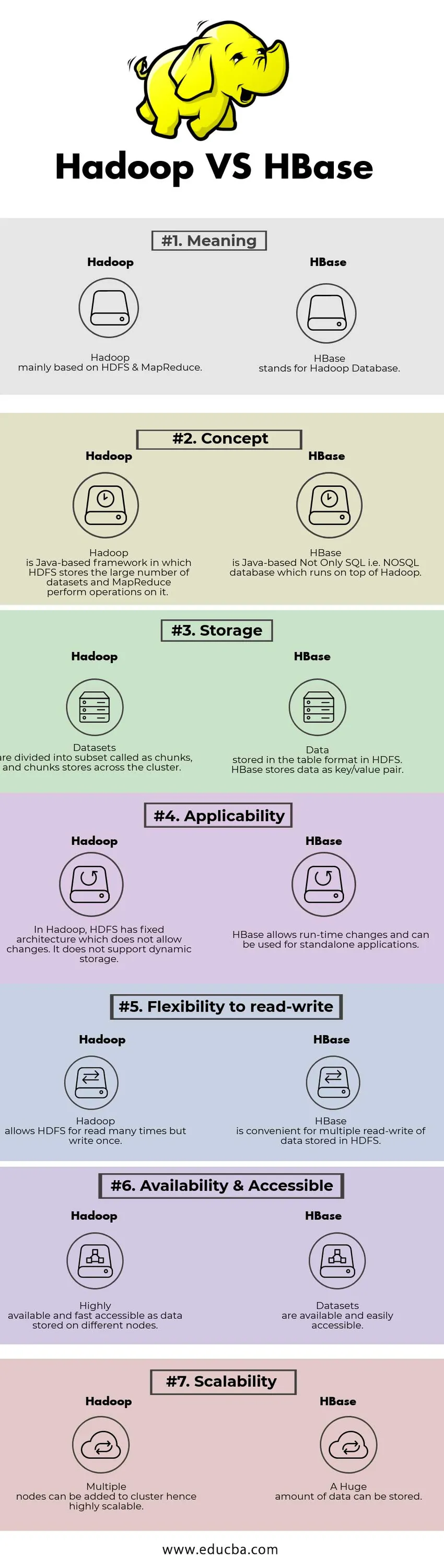
Principais diferenças entre Hadoop e HBase
A diferença entre o Hadoop e o HBase é explicada nos pontos apresentados abaixo:
- O Hadoop não é adequado para o processamento analítico online (OLAP) e o HBase faz parte do ecossistema do Hadoop, que fornece acesso aleatório em tempo real (leitura / gravação) aos dados no sistema de arquivos Hadoop.
- A estrutura do Hadoop é tolerante a falhas por design e suporta transferência rápida de dados entre nós, mesmo durante falhas do sistema. O HBase é um banco de dados Not-Only-SQL não-relacional e de código aberto que é executado sobre o Hadoop. O HBase vem sob o teorema do tipo CP (consistência, disponibilidade e tolerância à partição).
- O Hadoop é mais adequado para a análise de lotes. No entanto, uma de suas maiores desvantagens é a incapacidade de realizar análises em tempo real, o requisito de tendências do setor de TI. O HBase, por outro lado, pode lidar com grandes conjuntos de dados e não é apropriado para análises em lote. Em vez disso, é usado para gravar / ler dados do Hadoop em tempo real.
- O Hadoop e o HBase são capazes de processar dados estruturados, semiestruturados e não estruturados. No Hadoop, o HDFS não possui um mecanismo de processamento na memória que atrasa o processo de análise de dados; pois está usando o MapReduce antigo simples para fazer isso. O HBase, pelo contrário, possui um mecanismo de processamento na memória que aumenta drasticamente a velocidade de leitura / gravação.
- O Hadoop é muito transparente na execução da análise de dados. O HBase, por outro lado, sendo um banco de dados NoSQL em formato tabular, busca valores ao classificá-los sob diferentes valores-chave.
Tabela de comparação Hadoop vs HBase
| BASE DE COMPARAÇÃO | Hadoop | HBase |
| Significado | Hadoop baseado principalmente em HDFS e MapReduce. | HBase significa Hadoop Database. |
| Conceito | O Hadoop é uma estrutura baseada em Java na qual o HDFS armazena o grande número de conjuntos de dados e o MapReduce executa operações nele. | O HBase é um banco de dados Not Only SQL, baseado em Java, ou seja, NoSQL, que roda sobre o Hadoop. |
| Armazenamento | Os conjuntos de dados são divididos em um subconjunto chamado de pedaços e armazenamentos de pedaços no cluster. | Dados armazenados no formato de tabela no HDFS. O HBase armazena dados como par de chave / valor. |
| Aplicabilidade | No Hadoop, o HDFS fixou uma arquitetura que não permite alterações. Não suporta armazenamento dinâmico. | O HBase permite alterações no tempo de execução e pode ser usado para aplicativos independentes. |
| Flexibilidade para leitura e gravação | O Hadoop permite que o HDFS leia muitas vezes, mas escreva uma vez. | O HBase é conveniente para a leitura e gravação múltipla de dados armazenados no HDFS |
| Disponibilidade e Acessibilidade | Altamente disponível e rapidamente acessível como dados armazenados em diferentes nós. | Conjuntos de dados estão disponíveis e são facilmente acessíveis |
| Escalabilidade | Vários nós podem ser adicionados ao cluster, portanto, altamente escaláveis. | Uma quantidade enorme de dados pode ser armazenada. |
Conclusão - Hadoop vs HBase
Arquitetura Hadoop baseada principalmente em HDFS e MapReduce. O HBase é o componente de suporte no sistema Hadoop. O HBase é capaz de hospedar tabelas enormes e fornecer acesso aleatório rápido aos dados disponíveis, enquanto o HDFS é adequado para armazenar arquivos grandes. Tanto o Hadoop quanto o HBase fornecem acesso rápido aos dados, mas com as operações de leitura / gravação do HBase podem ser executadas e para o HDFS são lidas várias vezes e uma vez que a gravação pode ser executada. Este artigo descreveu um entendimento do Hadoop e HBase, destacou brevemente os recursos e comparou-os com sabedoria.
Artigo recomendado
- Apache Hadoop vs Apache Spark | As 10 melhores comparações que você deve saber!
- Hadoop vs Hive - Descubra as melhores diferenças
- HBase vs Cassandra - Qual é o Melhor (Infográficos)
- Top 12 Comparação de Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: quais são os recursos