
Diferenças entre Data Scientist e Machine Learning
Um Data Scientist é um especialista responsável por coletar, examinar e interpretar grandes volumes de dados para reconhecer maneiras de ajudar uma empresa a melhorar as operações e obter uma vantagem viável sobre os rivais. Segue uma abordagem interdisciplinar. Encontra-se entre a conexão de matemática, estatística, engenharia de software, inteligência artificial e design thinking. Ele lida com a coleta de dados, limpeza, análise, visualização, modelo de validação, previsão de experimentos, projeto, teste e hipótese muito mais. O aprendizado de máquina é uma divisão da inteligência artificial utilizada pela ciência de dados para atingir seus objetivos. O aprendizado de máquina se concentra principalmente em algoritmos, estruturas polinomiais e adição de palavras. Consiste em um grupo de algoritmos, máquinas e permite que eles aprendam sem serem claramente programados para isso.
Cientista de dados
Essa função de cientista de dados é um ramo da função das estatísticas, que inclui o uso da versão avançada das tecnologias de análise, incluindo aprendizado de máquina e modelagem preditiva, para fornecer visões além da análise estatística. A petição por habilidades em ciência de dados cresceu significativamente nos últimos anos, à medida que as empresas buscam coletar informações úteis a partir de enormes quantidades de dados estruturados, semiestruturados e não estruturados que uma grande empresa produz e coletivamente denominados big data. O objetivo de todas as etapas é apenas obter informações dos dados.
Tarefas padrão:
- Aloque, agregue e sintetize dados de várias fontes estruturadas e não estruturadas
- Explore, desenvolva e aplique aprendizado inteligente a dados do mundo real, forneça descobertas importantes e ações bem-sucedidas baseadas neles
- Analisar e fornecer dados coletados na organização
- Projetar e criar novos processos para modelagem, mineração de dados e implementação
- Desenvolver protótipos, algoritmos, modelos preditivos, protótipos
- Realizar solicitações de análise de dados e comunicar suas descobertas e decisões
Além disso, existem tarefas mais específicas, dependendo do domínio em que o empregador está trabalhando ou o projeto está sendo implementado.
Dados brutos -> Ciência de dados ---> Insights acionáveis
Machine Learning
A posição de Engenheiro de aprendizado de máquina é mais "técnica". O ML Engineer tem mais em comum com a Engenharia de Software clássica do que com o Data Scientist. Ajuda você a aprender a função objetivo que plota as entradas na variável de destino e / ou variáveis independentes nas variáveis dependentes.
As tarefas padrão do ML Engineer são geralmente como Data Scientist. Você também precisa trabalhar com dados, experimentar vários algoritmos de Machine Learning que resolverão a tarefa, criarão protótipos e soluções prontas.
O conhecimento e as habilidades necessárias para essa posição também se sobrepõem ao Data Scientist. Das principais diferenças, eu destacaria:
- Fortes habilidades de programação em uma ou mais linguagens populares (geralmente Python e Java), bem como em bancos de dados;
- Menos ênfase na capacidade de trabalhar em ambientes de análise de dados, mas mais ênfase nos algoritmos de Machine Learning;
- R e Python para modelagem são preferíveis ao Matlab, SPSS e SAS;
- Capacidade de usar bibliotecas prontas para várias pilhas no aplicativo, por exemplo, Mahout, Lucene para Java, NumPy / SciPy para Python;
- Capacidade de criar aplicativos distribuídos usando o Hadoop e outras soluções.
Como você pode ver, a posição de Engenheiro de ML (ou mais restrito) requer mais conhecimento em Engenharia de Software e, portanto, é adequado para desenvolvedores experientes. Muitas vezes, o caso funciona quando o desenvolvedor usual deve resolver a tarefa de ML para seu dever e começa a entender os algoritmos e as bibliotecas necessários.
Comparação direta entre cientista de dados e aprendizado de máquina
Abaixo estão as 5 principais diferenças entre o cientista de dados e o engenheiro de aprendizado de máquina 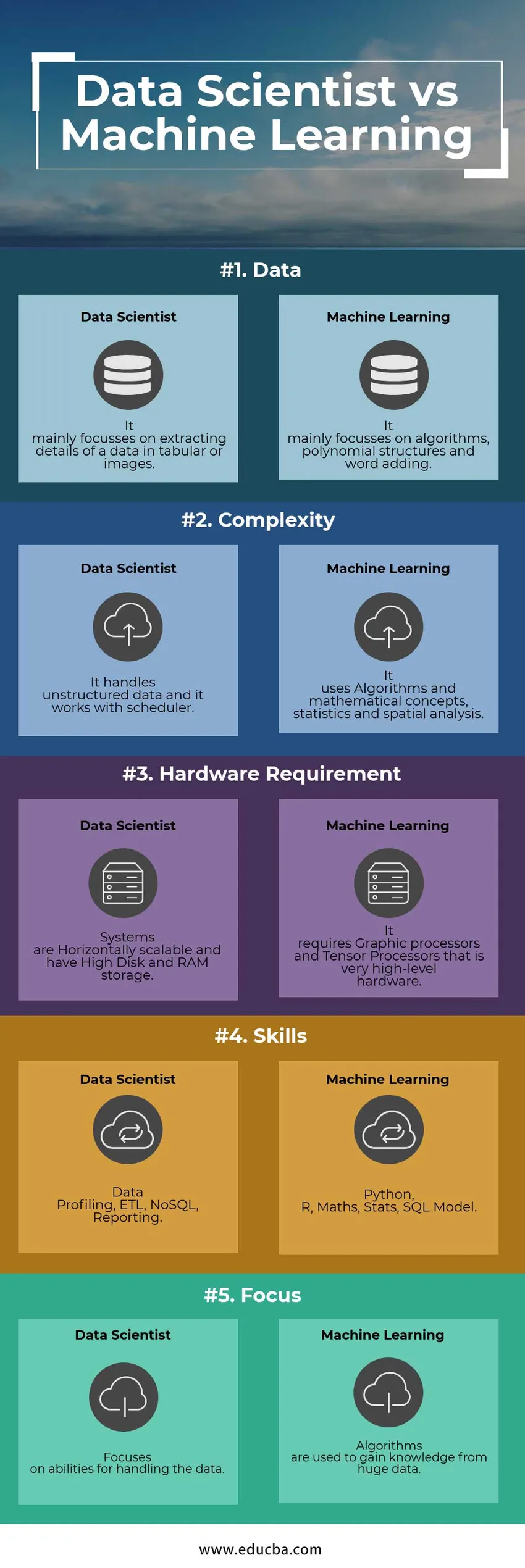
Diferença chave entre cientista de dados e aprendizado de máquina
Abaixo estão as listas de pontos, descreva as principais diferenças entre o cientista de dados e o engenheiro de Machine Learning
- O aprendizado de máquina e as estatísticas fazem parte da ciência de dados. A palavra aprendizado no aprendizado de máquina significa que os algoritmos dependem de alguns dados, usados como um conjunto de treinamento, para ajustar alguns parâmetros de modelo ou algoritmo. Isso abrange muitas técnicas, como regressão, Bayes ingênuo ou agrupamento supervisionado. Mas nem todas as técnicas se encaixam nessa categoria. Por exemplo, o agrupamento não supervisionado - uma técnica estatística e de ciência de dados - visa detectar agrupamentos e estruturas de agrupamentos sem nenhum conhecimento ou conjunto de treinamento prévio para ajudar o algoritmo de classificação. Um ser humano é necessário para rotular os aglomerados encontrados. Algumas técnicas são híbridas, como a classificação semi-supervisionada. Algumas técnicas de detecção de padrões ou estimativa de densidade se encaixam nessa categoria.
- A ciência de dados é muito mais do que aprendizado de máquina. Os dados, na ciência de dados, podem ou não vir de uma máquina ou processo mecânico (os dados da pesquisa podem ser coletados manualmente, os ensaios clínicos envolvem um tipo específico de dados pequenos) e podem não ter nada a ver com o aprendizado, como acabei de discutir. Mas a principal diferença é o fato de a ciência de dados cobrir todo o espectro do processamento de dados, não apenas os aspectos algorítmicos ou estatísticos. A ciência de dados também abrange integração de dados, arquitetura distribuída, aprendizado automatizado de máquinas, visualização de dados, painéis e engenharia de Big Data.
Tabela de comparação Data Scientist vs Machine Learning
A seguir estão as listas de pontos, descreva as comparações entre o Data Scientist e o engenheiro de Machine Learning:
| Característica | Cientista de dados | Machine Learning |
| Dados | Ele se concentra principalmente na extração de detalhes de dados em tabelas ou imagens | Ele se concentra principalmente em algoritmos, estruturas polinomiais e adição de palavras |
| Complexidade | Ele lida com dados não estruturados e funciona com agendador | Utiliza algoritmos e conceitos matemáticos, estatística e análise espacial |
| Requisito de hardware | Os sistemas são escaláveis horizontalmente e possuem armazenamento em disco e RAM alto | Requer processadores gráficos e processadores tensores que são hardware de nível muito alto |
| Habilidades | Criação de perfil de dados, ETL, NoSQL, relatórios | Python, R, Matemática, Estatísticas, Modelo SQL |
| Foco | Concentra-se nas habilidades para lidar com os dados | Algoritmos são usados para obter conhecimento de enormes dados |
Conclusão - Cientista de dados x aprendizado de máquina
O aprendizado de máquina ajuda você a aprender a função objetivo que plota as entradas na variável de destino e / ou variáveis independentes nas variáveis dependentes
Um cientista de dados faz muita exploração de dados e chega à ampla estratégia de como enfrentá-los. Ele é responsável por fazer perguntas dentro dos dados e descobrir quais respostas podem ser extraídas razoavelmente dos dados. A engenharia de recursos pertence ao domínio do Data Scientist. A criatividade também desempenha um papel aqui, e um engenheiro de Machine Learning conhece mais ferramentas e pode criar modelos com base em um conjunto de recursos e dados - conforme instruções do Data Scientist. O domínio do pré-processamento de dados e extração de recursos pertence ao engenheiro de ML.
A ciência e o exame de dados utilizam o aprendizado de máquina para esse tipo de validação e criação arquetípica. É vital observar que todos os algoritmos nessa criação de modelo podem não vir do aprendizado de máquina. Eles podem chegar de vários outros campos. O modelo deseja ser mantido sempre relevante. Se as situações mudarem, o modelo que criamos anteriormente pode se tornar imaterial. Os requisitos do modelo devem ser verificados quanto à sua segurança em momentos diferentes e precisam ser adaptados se a sua segurança diminuir.
A ciência de dados é um domínio totalmente grande. Se tentarmos colocá-lo em um pipeline, ele terá aquisição de dados, armazenamento de dados, pré-processamento ou limpeza de dados, padrões de aprendizado de dados (via aprendizado de máquina), usando o aprendizado para previsões. Essa é uma maneira de entender como o aprendizado de máquina se encaixa na ciência de dados.
Artigo recomendado
Este foi um guia para as diferenças entre o cientista de dados e o engenheiro de Machine Learning, seu significado, comparação cara a cara, diferenças principais, tabela de comparação e conclusão. Você também pode consultar os seguintes artigos para saber mais -
- Data mining vs Machine learning - 10 coisas que você precisa saber
- Machine Learning vs Predictive Analytics - 7 diferenças úteis
- Cientista de dados x analista de negócios - descubra as 5 diferenças impressionantes
- Data Scientist vs Data Engineer - 7 comparações surpreendentes
- Perguntas da entrevista de engenharia de software | Top e mais solicitadas