
O que é regressão linear em R?
A regressão linear é o algoritmo mais popular e amplamente utilizado na área de estatística e aprendizado de máquina. A regressão linear é uma técnica de modelagem para entender a relação entre variáveis de entrada e saída. Aqui, as variáveis devem ser numéricas. A regressão linear vem do fato de que a variável de saída é uma combinação linear de variáveis de entrada. A saída é geralmente representada por "y", enquanto a entrada é representada por "x".
A regressão linear em R pode ser categorizada de duas maneiras
-
Regressão linear simples
Essa é a regressão em que a variável de saída é uma função de uma única variável de entrada. Representação de regressão linear simples:
y = c0 + c1 * x1
-
Regressão linear múltipla
Essa é a regressão em que a variável de saída é uma função de uma variável de entrada múltipla.
y = c0 + c1 * x1 + c2 * x2
Nos dois casos acima, c0, c1, c2 são os coeficientes que representam pesos de regressão.
Regressão linear em R
R é uma ferramenta estatística muito poderosa. Então, vamos ver como a regressão linear pode ser executada em R e como seus valores de saída podem ser interpretados.
Vamos preparar um conjunto de dados para executar e entender a regressão linear em profundidade agora.
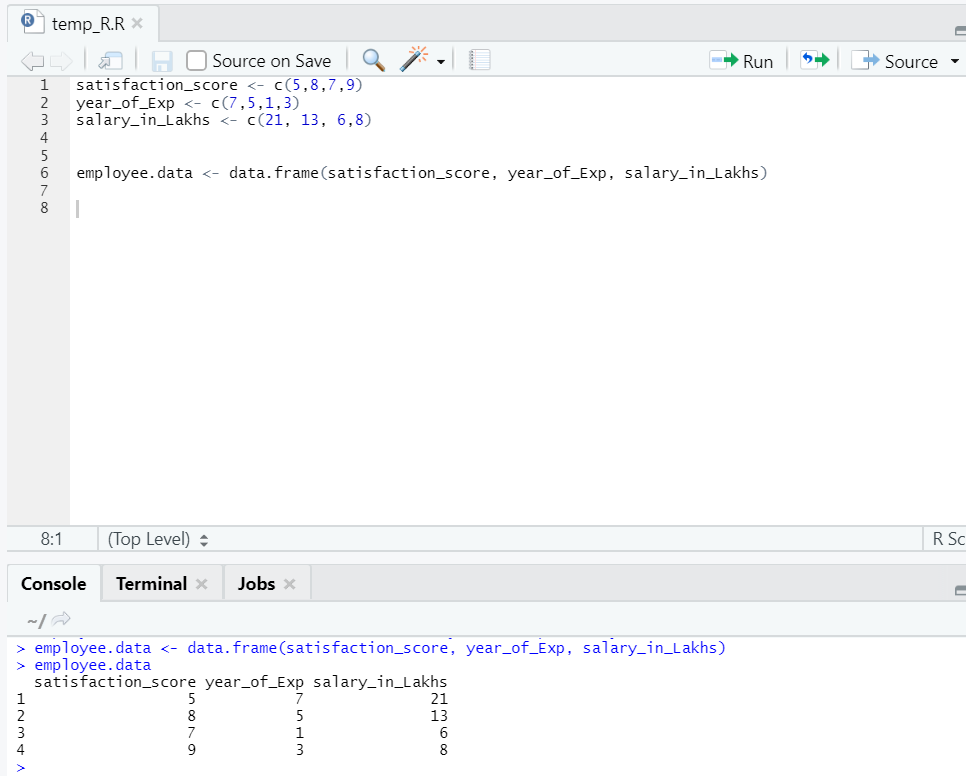
Agora temos um conjunto de dados em que "score_satisfação" e "ano_de_Exp" são a variável independente. "Employee_in_lakhs" é a variável de saída.
Referindo-se ao conjunto de dados acima, o problema que queremos abordar aqui por meio de regressão linear é:
Estimativa do salário de um funcionário, com base no ano de experiência e índice de satisfação em sua empresa.
Código R de regressão linear:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
A saída do código acima será:
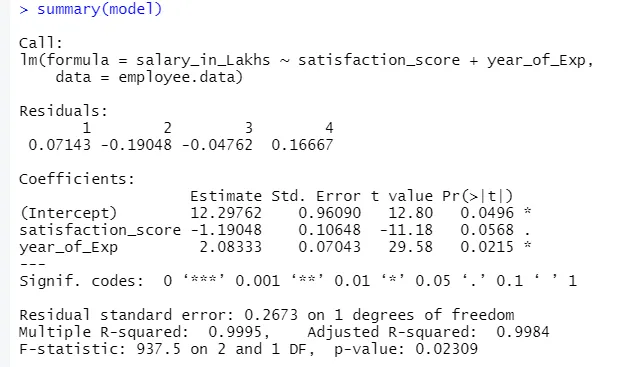
A fórmula da regressão torna-se
Y = 12, 29-1, 19 * pontuação da satisfação + 2, 08 × 2 * ano_de_Exp
No caso, há várias entradas para o modelo.
Então o código R pode ser:
modelo <- lm (salário_em_Lakhs ~., dados = funcionário.dados)
No entanto, se alguém quiser selecionar uma variável dentre várias variáveis de entrada, existem várias técnicas como "Eliminação para trás", "Seleção para frente" etc., também estão disponíveis para isso.
Interpretação da regressão linear em R
Abaixo estão algumas interpretações da regressão linear em r, que são as seguintes:
1.Residuais
Isso se refere à diferença entre a resposta real e a resposta prevista do modelo. Portanto, para cada ponto, haverá uma resposta real e uma resposta prevista. Portanto, os resíduos serão tantas quanto as observações. No nosso caso, temos quatro observações, portanto, quatro resíduos.

2. coeficientes
Indo além, encontraremos a seção de coeficientes, que descreve a interceptação e a inclinação. Se alguém deseja prever o salário de um funcionário com base em sua experiência e pontuação de satisfação, precisa desenvolver uma fórmula modelo baseada na inclinação e na interceptação. Esta fórmula irá ajudá-lo a prever o salário. A interceptação e a inclinação ajudam um analista a encontrar o melhor modelo que se adapte adequadamente aos pontos de dados.
Inclinação: descreve a inclinação da linha.
Interceptação: o local onde a linha corta o eixo.
Vamos entender como a formação de fórmulas é feita com base na inclinação e na interceptação.
Digamos que a interceptação seja 3 e a inclinação é 5.
Portanto, a fórmula é y = 3 + 5x . Isso significa que, se x aumentado por uma unidade, y é aumentado em 5.
a.Ceficiente - Estimativa
Nesse sentido, a interceptação indica o valor médio da variável de saída, quando toda a entrada se torna zero. Portanto, no nosso caso, o salário em lakhs será 12, 29Lakhs como média, considerando o índice de satisfação e a experiência zero. Aqui, a inclinação representa a mudança na variável de saída com uma mudança de unidade na variável de entrada.
b.Ceficiente - erro padrão
O erro padrão é a estimativa do erro que podemos obter ao calcular a diferença entre o valor real e o previsto da nossa variável de resposta. Por sua vez, isso mostra a confiança em relacionar variáveis de entrada e saída.
c.Ceficiente - valor t
Este valor oferece confiança para rejeitar a hipótese nula. Quanto maior o valor do zero, maior a confiança para rejeitar a hipótese nula e estabelecer a relação entre a saída e a variável de entrada. No nosso caso, o valor também está longe de zero.
d.Ceficiente - Pr (> t)
Esse acrônimo representa basicamente o valor-p. Quanto mais próximo de zero, mais fácil podemos rejeitar a hipótese nula. Na linha que vemos no nosso caso, esse valor é próximo de zero, podemos dizer que existe uma relação entre pacote salarial, índice de satisfação e ano de experiências.

Erro padrão residual
Isso representa o erro na previsão da variável de resposta. Quanto menor, maior a precisão do modelo.
R-quadrado múltiplo, R-quadrado ajustado
O quadrado-R é uma medida estatística muito importante para entender o quão perto os dados se ajustaram ao modelo. Portanto, no nosso caso, quão bem nosso modelo, que é regressão linear, representa o conjunto de dados.
O valor do quadrado R sempre fica entre 0 e 1. A fórmula é:

Quanto mais próximo o valor de 1, melhor o modelo descreve os conjuntos de dados e sua variação.
No entanto, quando mais de uma variável de entrada entra em cena, o valor ajustado ao quadrado de R é preferido.
Estatística F
É uma medida forte para determinar a relação entre a variável de entrada e resposta. Quanto maior o valor que 1, maior a confiança na relação entre a variável de entrada e saída.
No nosso caso, é "937, 5", que é relativamente maior, considerando o tamanho dos dados. Portanto, a rejeição da hipótese nula fica mais fácil.
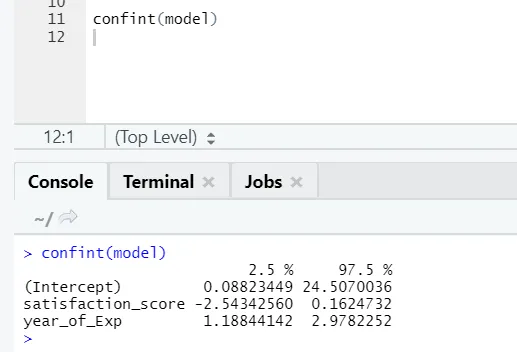
Se alguém quiser ver o intervalo de confiança para os coeficientes do modelo, aqui está a maneira de fazê-lo:
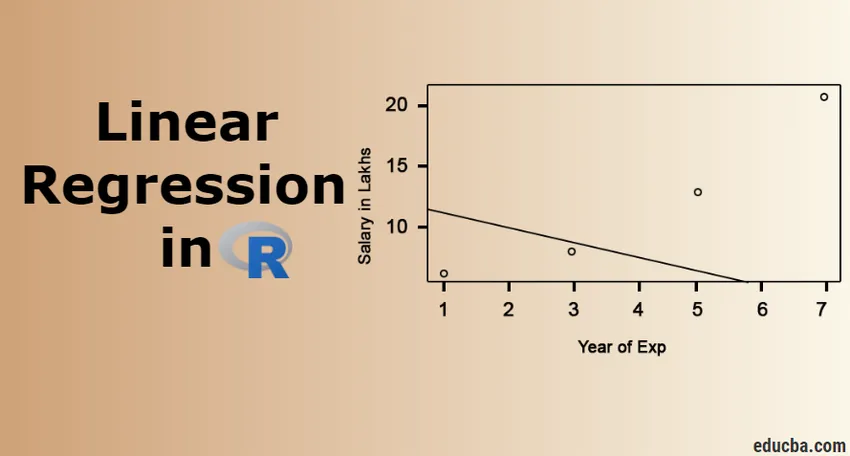
Visualização de regressão
Código R:
plot (salário_em_Lakhs ~ pontuação_satisfação + ano_Ex_, dados = funcionário.dados)
abline (modelo)
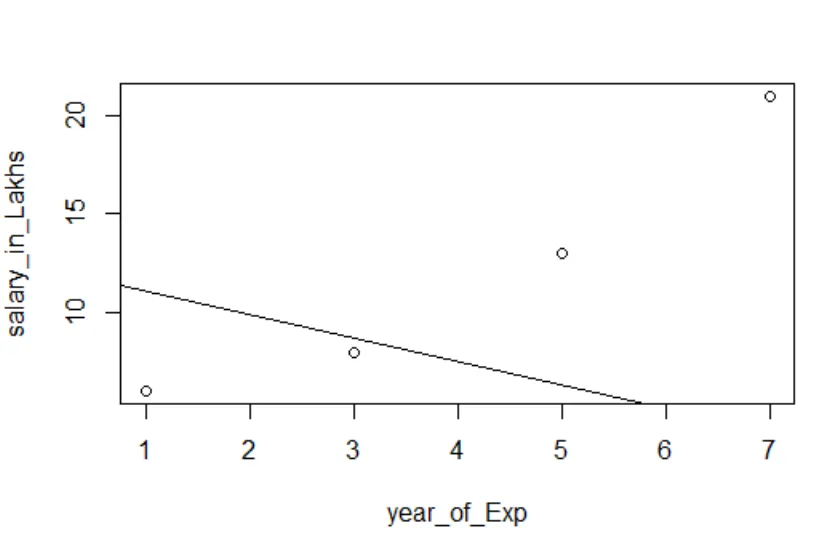
É sempre melhor reunir mais e mais pontos antes de se ajustar a um modelo.
Conclusão - Regressão Linear em R
A regressão linear é simples, fácil de ajustar, fácil de entender e, ainda assim, um modelo muito poderoso. Vimos como a regressão linear pode ser realizada em R. Também tentamos interpretar os resultados, o que pode ajudá-lo na otimização do modelo. Quando se sentir confortável com a regressão linear simples, deve-se tentar a regressão linear múltipla. Junto com isso, como a regressão linear é sensível aos valores discrepantes, é preciso analisá-la, antes de pular diretamente para a regressão linear.
Artigos recomendados
Este é um guia para a regressão linear em R. Aqui discutimos o que é regressão linear em R? categorização, visualização e interpretação de R. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Modelagem Preditiva
- Regressão logística em R
- Árvore de decisão em R
- R Perguntas da entrevista
- Principais diferenças entre regressão e classificação
- Guia da Árvore de Decisão no Machine Learning
- Regressão linear vs regressão logística | Principais diferenças