
O que é Cassandra?
Cassandra é um banco de dados NoSQL que é um banco de dados distribuído ponto a ponto. É executado em um cluster que possui nós homogêneos. É feito de maneira que possa lidar com grandes volumes de dados. Ao manipular esses dados, ele também deve ser capaz de fornecer uma alta capacidade. O Cassandra oferece alto desempenho quando se trata de operações de leitura e gravação. A arquitetura do cluster Cassandra não possui mestres, escravos ou líderes específicos. Ao usar dessa maneira, garante que não haja um único ponto de falha. Vamos dar uma olhada na arquitetura em detalhes.
Arquitetura Cassandra
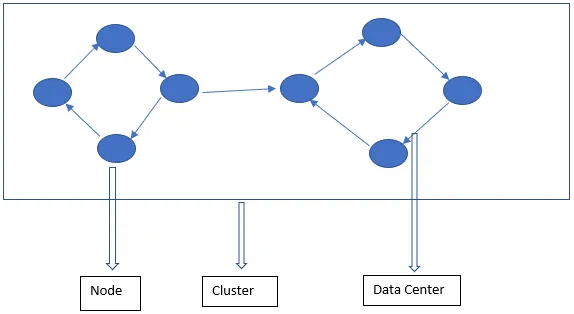
A Arquitetura Cassandra consiste principalmente em Nó, Cluster e Data Center. Além desses, existem outros componentes também. Cassandra é um banco de dados armazenado em linha. Ele permite que usuários autorizados se conectem a qualquer nó em qualquer datacenter usando o CQL.
Estruturas-chave em Cassandra
Estas são as seguintes estruturas-chave no Cassandra:
- Nó - É aqui que os dados são armazenados. É o componente mais básico do Cassandra. Pode ser pensado como um único servidor em um rack. Ele garante que não haja um ponto único de falha.
- Data Center - Um data center é uma coleção de nós. Pode ser físico ou virtual. Dependendo da carga de trabalho, os data centers são divididos e escolhidos. O fator de replicação é decidido com base no data center. Dependendo desse fator de replicação, os dados podem ser gravados em diferentes datacenters.
- Cluster - O cluster compreende um ou mais data centers. Os clusters geralmente se estendem a diferentes locais físicos.
Além desses, os outros componentes que desempenham um papel no Cassandra são os seguintes.
1. Confirmar log
Os dados confirmados para manter a durabilidade dos dados são armazenados no log de confirmação. Os dados são movidos para uma tabela de sequência classificada (explicada a seguir). Uma vez feito esse movimento, o log de confirmação pode ser arquivado, excluído ou reciclado.
2. Tabela SS
Esta tabela, como mencionado no ponto anterior, armazena as tabelas de log ou memória em intervalos regulares. É um arquivo de dados imutável. As tabelas SS podem armazenar dados frequentemente de maneira seqüencial. Eles acrescentam dados e mantêm informações para todas as tabelas do Cassandra.
3. Tabela CQL
A tabela Cassandra Query é uma coleção de colunas ordenadas que podem buscar uma linha nessa tabela. Existem colunas armazenadas nesta tabela onde os dados podem ser buscados usando a chave primária.
4. Filtro Bloom
É um tipo simples de cache em que existem algoritmos não determinísticos armazenados para teste. Ele verifica se um elemento é membro do conjunto ou não. Esses filtros geralmente são acessados após cada consulta executada.
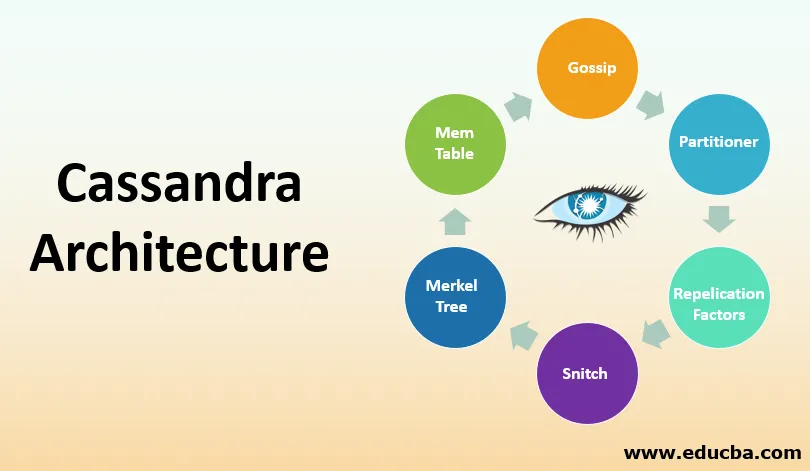
Componentes principais para configurar o Cassandra
Existem os seguintes componentes no Cassandra:
1. Fofocas
- Como o nome sugere, deve haver comunicação entre pares para descobrir e compartilhar a localização e o estado das informações sobre todos os nós.
- Essas informações devem persistir em local para que cada nó possa usá-las assim que um nó for reiniciado. Os nós descobrem informações sobre outros nós trocando informações.
- Isso pode ser feito para um máximo de três nós. As informações não são compartilhadas com todos os nós presentes no cluster ou no datacenter. As informações são compartilhadas com alguns nós, mas eventualmente as informações de estado atravessam o cluster.
2. Particionador
- O particionador decide qual nó deve receber a primeira réplica de qualquer dado. Também é responsável por cuidar da distribuição dessas réplicas.
- Ele determinará qual nó deve ter qual replicação no cluster. Cada linha de dados deve ser identificada exclusivamente. Isso pode ser feito usando uma chave primária ou chave de partição.
- O particionador é uma função de hash que ajuda na obtenção de um token de uma chave primária de qualquer linha. Cada nó possui um valor num_token atribuído a ele, que pode ser definido como o particionador.
- O valor do token gerado ajuda a determinar qual nó recebe a réplica das linhas.
3. Fator de Replicação
- Esse fator determina o número total de réplicas presentes no cluster. Se o fator de replicação for 1, haverá apenas uma cópia de cada linha em um nó.
- Da mesma forma, se o fator de replicação for dois, haverá duas cópias mantidas onde todas as cópias estão presentes em um nó diferente. Como mencionado anteriormente, não há arquitetura mestre-escravo no Cassandra; todas as cópias são importantes.
- O fator de replicação é definido para cada data center. Esse fator deve ser maior que um, mas não maior que o número de nós presentes no cluster.
4. Pomo
- A estratégia de replicação que ajuda a obter o local onde as réplicas devem ser colocadas para um grupo de máquinas no datacenter e no rack é conhecido como Snitch.
- Há uma camada dinâmica que ajuda no monitoramento e no desempenho e ajuda na escolha da melhor réplica a partir da qual os dados podem ser lidos. Os bufos devem ser configurados apenas quando um cluster é criado.
- Possui valores padrão ativados para a maioria das implantações. As alterações na configuração podem ser feitas no arquivo Cassandra.yml, onde o limite de snitch dinâmico para cada nó está presente.
5. Árvore Merkle
- Pode haver diferenças nos blocos de dados. Para encontrar as diferenças facilmente, a árvore Merkle é uma árvore de hash que ajuda a fazer isso.
- Os nós folha da árvore de hash contêm hashes de blocos de dados separados e os nós pais têm as informações ou eles armazenam os hashes de seus filhos também.
- Usando essa técnica, é mais fácil encontrar diferenças entre os nós presentes.
6. Tabela Mem
- Esta tabela possui informações sobre o cache cujos dados ainda não foram liberados e residem na memória.
Conclusão
Cassandra é um banco de dados NoSQL que é útil no processamento de grandes quantidades de dados. Ele não possui uma arquitetura típica de mestre-escravo e, portanto, todos os nós são igualmente importantes. Os nós têm réplicas no cluster de acordo com o fator de replicação. Isso garante a consistência e durabilidade dos dados. Com todos esses recursos, fica claro que o Cassandra é muito útil para big data. Portanto, o Cassandra é durável, rápido, pois é distribuído e confiável.
Artigos recomendados
Este é um guia para a arquitetura Cassandra. Aqui discutimos a introdução, a arquitetura Cassandra, a estrutura e os principais componentes do Cassandra. Você também pode consultar nossos outros artigos sugeridos -
- Visão geral da arquitetura Kubernetes
- O que é arquitetura de big data?
- Recursos adicionados à arquitetura do AutoCAD
- Arquitetura de computação em nuvem