

Introdução às redes neurais recorrentes (RNN)
Uma rede neural recorrente é um tipo de Rede Neural Artificial (RNA) e é usada em áreas de aplicação de Processamento de Linguagem Natural (PNL) e Reconhecimento de Fala. Um modelo RNN é projetado para reconhecer as características seqüenciais dos dados e, posteriormente, usar os padrões para prever o cenário futuro.
Trabalho de redes neurais recorrentes
Quando falamos de redes neurais tradicionais, todas as saídas e entradas são independentes uma da outra, como mostrado no diagrama abaixo:
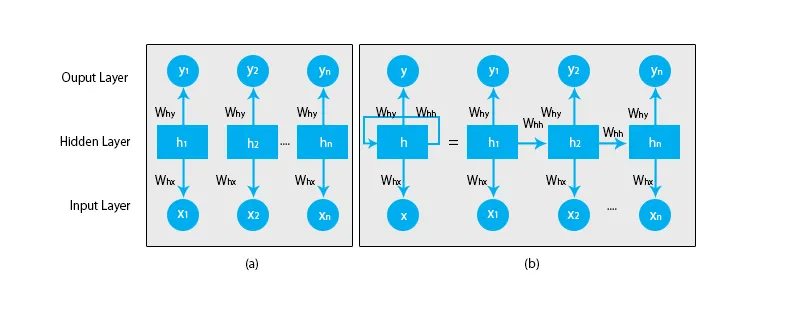
Porém, no caso de redes neurais recorrentes, a saída das etapas anteriores é inserida na entrada do estado atual. Por exemplo, para prever a próxima letra de qualquer palavra ou para prever a próxima palavra da frase, é necessário lembrar as letras anteriores ou as palavras e armazená-las em alguma forma de memória.
A camada oculta é aquela que lembra algumas informações sobre a sequência. Um exemplo simples da vida real com o qual podemos nos relacionar com a RNN é quando assistimos a um filme e, em muitos casos, estamos em posição de prever o que acontecerá a seguir, mas e se alguém apenas se juntasse ao filme e lhe pedissem para prever o que vai acontecer a seguir? Qual será a resposta dele? Ele ou ela não terão nenhuma pista, porque não estão cientes dos eventos anteriores do filme e não têm memória sobre isso.
Uma ilustração de um modelo RNN típico é fornecida abaixo:
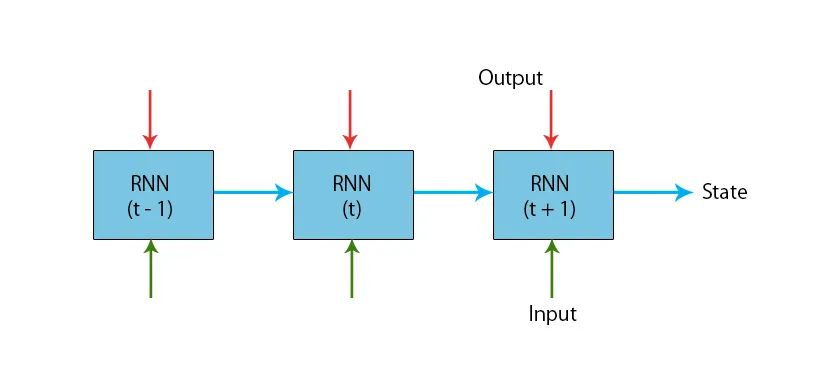
Os modelos RNN estão tendo uma memória que sempre lembra o que foi feito nas etapas anteriores e o que foi calculado. A mesma tarefa está sendo executada em todas as entradas e a RNN usa o mesmo parâmetro para cada uma das entradas. Como a rede neural tradicional possui conjuntos independentes de entrada e saída, eles são mais complexos que a RNN.
Agora vamos tentar entender a Rede Neural Recorrente com a ajuda de um exemplo.
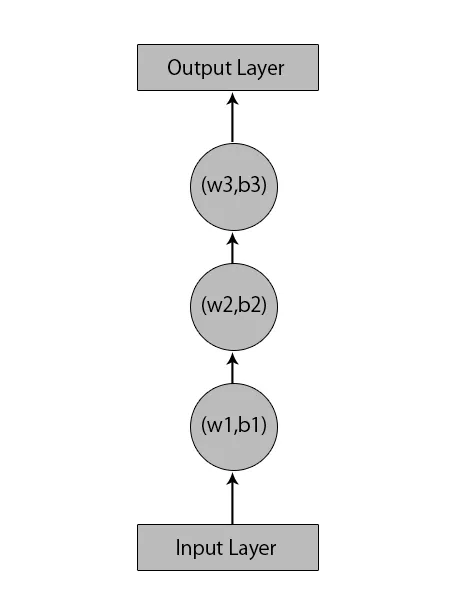
Digamos que temos uma rede neural com 1 camada de entrada, 3 camadas ocultas e 1 camada de saída.
Quando falamos de outras redes neurais ou tradicionais, elas terão seus próprios conjuntos de vieses e pesos em suas camadas ocultas, como (w1, b1) para a camada oculta 1, (w2, b2) para a camada oculta 2 e (w3, b3 ) para a terceira camada oculta, onde: w1, w2 e w3 são os pesos e, b1, b2 e b3 são os vieses.
Diante disso, podemos dizer que cada camada não depende de outra e que elas não conseguem se lembrar de nada sobre a entrada anterior:
Agora, o que uma RNN fará é o seguinte:
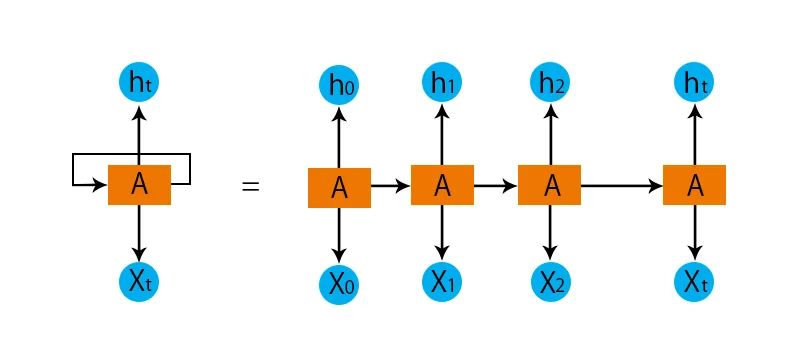
- As camadas independentes serão convertidas na camada dependente. Isso é feito fornecendo os mesmos desvios e pesos para todas as camadas. Isso também reduz o número de parâmetros e camadas na rede neural recorrente e ajuda a RNN a memorizar a saída anterior, emitindo a saída anterior como entrada para a próxima camada oculta.
- Para resumir, todas as camadas ocultas podem ser unidas em uma única camada recorrente, de modo que os pesos e desvios sejam os mesmos para todas as camadas ocultas.
Portanto, uma rede neural recorrente será semelhante a abaixo:
Agora é hora de lidar com algumas das equações de um modelo RNN.
- Para calcular o estado atual,
h t= f (h t-1, x t ),
Onde:
x t é o estado de entrada
h t-1 é o estado anterior,
h t é o estado atual.
- Para calcular a função de ativação
h t= tanh (W hh h t-1 +W xh x t ),
Onde:
W xh é o peso no neurônio de entrada,
W hh é o peso do neurônio recorrente.
- Para calcular a saída:
Y t =W hy h t.
Onde,
Y t é a saída e,
Qual é o peso na camada de saída.
Etapas para treinar uma rede neural recorrente
- Nas camadas de entrada, a entrada inicial é enviada com todas as mesmas funções de peso e ativação.
- Usando a entrada atual e a saída do estado anterior, o estado atual é calculado.
- Agora, o estado atual h t se tornará h t-1 pela segunda vez.
- Isso continua repetindo todas as etapas e, para resolver qualquer problema específico, pode continuar várias vezes para juntar as informações de todas as etapas anteriores.
- A etapa final é então calculada pelo estado atual do estado final e por todas as outras etapas anteriores.
- Agora, um erro é gerado calculando a diferença entre a saída real e a saída gerada pelo nosso modelo RNN.
- A etapa final é quando ocorre o processo de retropropagação, em que o erro é retropropagado para atualizar os pesos.
Vantagens das redes neurais recorrentes
- A RNN pode processar entradas de qualquer tamanho.
- Um modelo RNN é modelado para lembrar cada informação ao longo do tempo, o que é muito útil em qualquer preditor de séries temporais.
- Mesmo que o tamanho da entrada seja maior, o tamanho do modelo não aumenta.
- Os pesos podem ser compartilhados através das etapas de tempo.
- A RNN pode usar sua memória interna para processar as séries arbitrárias de entradas, o que não é o caso das redes neurais feedforward.
Desvantagens das redes neurais recorrentes
- Devido à sua natureza recorrente, o cálculo é lento.
- O treinamento dos modelos RNN pode ser difícil.
- Se estivermos usando relu ou tanh como funções de ativação, torna-se muito difícil processar seqüências que são muito longas.
- Propenso a problemas como explosão e desaparecimento de gradientes.
Conclusão
Neste artigo, aprendemos outro tipo de rede neural artificial chamada Rede Neural Recorrente, focamos na principal diferença que faz a RNN se destacar de outros tipos de redes neurais, áreas em que pode ser usada extensivamente, como no reconhecimento de fala e PNL (Processamento de Linguagem Natural). Além disso, fomos atrás do trabalho dos modelos e funções da RNN que são usados para criar um modelo RNN robusto.
Artigos recomendados
Este é um guia para redes neurais recorrentes. Aqui discutimos a introdução, como funciona, etapas, vantagens e desvantagens da RNN, etc. Você também pode consultar nossos outros artigos sugeridos para saber mais -- O que são redes neurais?
- Estruturas de aprendizado de máquina
- Introdução à Inteligência Artificial
- Introdução ao Big Data Analytics
- Implementação de redes neurais