

Introdução à instalação do Hive
Na instalação do Hive, alguns pré-requisitos devem ser feitos antes da instalação.
Todos os componentes do Hadoop, como Hive, Hbase, Pig, etc, oferecem suporte ao ambiente Linux. Portanto, é recomendável ter um sistema operacional Linux no seu dispositivo. Se não for o caso, e você deseja praticar na seção, enquanto possui janelas no sistema. O que você pode fazer é instalar a máquina CDH no seu sistema e usá-la como uma plataforma para explorar o Hadoop. Isso exigirá um mínimo de 4 GB de RAM no seu sistema ou você pode ter uma máquina CDH no seu pen drive e usá-la.
De qualquer forma, você sempre pode ter uma solução para sua pergunta, talvez mais cedo ou mais tarde.
Pré-requisitos para instalar o Hive
Existem alguns pré-requisitos para instalar o hive em qualquer máquina:
- Instalação Java
- Instalação do Hadoop
Passo 1
- Verifique se o Java está instalado.
- Abra o terminal e digite o comando.
Versão Java
- Se o java estiver instalado no sistema, ele fornecerá a versão ou um erro. No meu caso, Java já está instalado e abaixo está a saída do comando.

- No caso, o Java não está instalado no seu sistema. Você pode visitar o link abaixo, baixar o java e instalá-lo.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Instalação Java
- Extraia o baixado.
- Mova para "/ usr / local /".
- Configure as variáveis PATH e JAVA_HOME.
Passo 2
- Verifique se o Hadoop está instalado.
- Abra o terminal e digite o comando
Versão do Hadoop
- Se o Hadoop já estiver instalado, esse comando fornecerá a versão ou um erro.
- No meu caso, o Hadoop já instalou a saída abaixo.
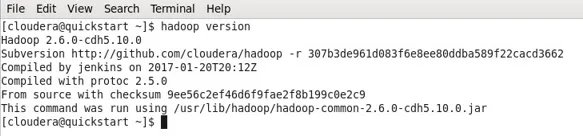
- Agora você pode observar que estou trabalhando com uma máquina CDH5.
- Se o Hadoop não estiver instalado, faça o download do Hadoop da fundação de software Apache.
Instalação do Hadoop
1. Configurar o Hadoop
2. Configure o Hadoop
Os arquivos que precisam ser editados para configurar o Hadoop são:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Configure o Namenode usando o comando:
Hdfs namenode -format
4. Inicie o dfs usando o seguinte comando:
start -dfs.sh
5. Inicie o fio usando o comando:
Start -yarn.sh
Como instalar o Hive?
Abaixo dos pontos, ajuda a instalar a seção:
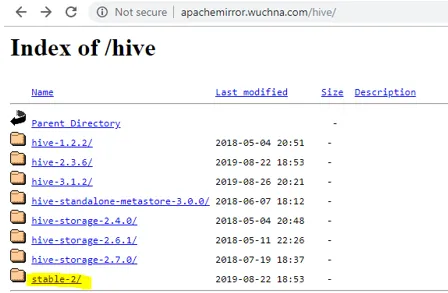
- A primeira coisa que precisamos fazer é baixar o release da seção, que pode ser executado clicando no link abaixo: http://apachemirror.wuchna.com/hive/
- O link acima fornecerá o link a partir do qual você deve escolher o stable-2 destacado abaixo em amarelo:
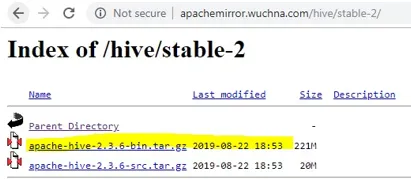
- Após abrir o stable-2, escolha o arquivo bin (destacado em amarelo na captura de tela) e clique com o botão direito do mouse e em “copiar endereço do link”.
Etapas para instalar o Hive
Abaixo estão as etapas para instalar a seção:
Etapa 1: faça o download do arquivo tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Etapa 2: extraia o arquivo.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Etapa 3: Mova os arquivos apache para o diretório / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Etapa 4: configurar o ambiente do Hive anexando as seguintes linhas ao arquivo ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Etapa 5: execute o arquivo bashrc.
$ source ~/.bashrc
Etapa 6: Configuração do Hive - Edite o arquivo hive-env.sh para acrescentar isso:
export HADOOP_HOME=/usr/local/Hadoop
Etapa 7: edite usando os comandos abaixo:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Agora, para verificar se a seção está instalada ou não, use o comando hive-version.
- Aqui, a versão do hive entra no shell do hive, o que significa que o hive está instalado. No entanto, no meu caso, é a versão mais antiga, portanto, dando o aviso.

Conclusão - Instalação do Hive
O Hive abre o big data para muitas pessoas devido à sua facilidade e natureza semelhante ao SQL, como linguagem de consulta e interfaces. O Hive é construído no núcleo do Hadoop, pois usa o Mapreduce para execução. Muito fácil de recuperar os dados e processar o Big Data.
Artigos recomendados
Este é um guia para a instalação do Hive. Aqui discutimos alguns pré-requisitos para instalar o hive em qualquer máquina e como instalar o hive em etapas para melhor entendimento. Você também pode consultar nossos outros artigos relacionados para saber mais.
- O que é uma colméia?
- Comandos do Hive
- Como instalar o Hive
- O que é porco?